
再生可能エネルギーには将来が約束されているが、現時点では誰がソーラーパネルを屋根の上や裏庭に設置したり、隣人と共有しているかについての追跡は行われていない。幸いにも、ソーラーパネルは一般に、光に晒されたときにもっとも良く働く。このことにより、パネルを衛星軌道上から発見し、数えることが容易になる。これこそが、DeepSolarプロジェクトが行っていることだ。
こうした情報を収集するための取り組みはいくつも存在している。規制によって行われているものもあれば、自主的なもの、自動化されたものもある。しかし、いずれの取り組みも、国家レベルまたは州レベルで、政策やビジネス上の決定を下すために十分な包括性はもっていない。
スタンフォードのエンジニアであるArun MajumdarとRam Rajagopal(それぞれ機械と土木が専門)はこの状況を、言われてみれば当たり前の方法で解決する決心をした。
機械学習システムは、それが「認識訓練された」ものならば、たとえ対象が猫、顔、車などであっても、画像を見て対象をきちんと認識することができる。ならばソーラーパネルも扱えない筈はない。
大学院生であるJiafan YuとZhecheng Wangを含む彼らのチームは、数十万枚の衛星画像を使って訓練を行った画像認識機械学習エージェントを用意した。用意されたモデルは、画像の中のソーラーパネルの存在を特定すること、ならびにそれらのパネルの形と設置場所を特定することの両者を学んでいる。
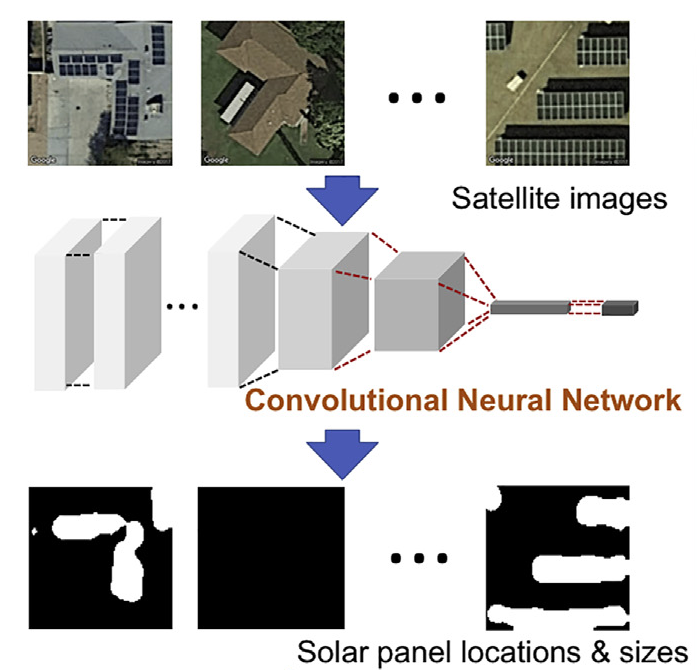
モデルを、ランダムに選んだ他の米国の衛星画像を使って評価したところ、(適合率と再現率が共に)およそ90%の正確性を達成した(どのように計算するかによって多少数字は上下する)。これは類似の他のモデルよりもかなり優れた数値である。またそのセルサイズの見積もりに関しては誤差はわずかに3%ほどだった(非常に小さなパネルの検知が主な弱点だとRajagopalは私に説明した。だがその理由の一部は、画像そのものの限界に起因している)。
そしてチームは、適切な画像を見つけることができた隣接する48州をカバーする、10億枚以上のイメージタイルをモデルに適用した。その中ではかなりの地域が除外されてはいるが、その大部分は、例えば山岳地帯である。そうした地域にはあまりソーラーパネルは設置されておらず、国立公園内にセルを置こうとしている者もほとんどいない。
こうしたエリアは合計で実際の国土の6%を占めている。だが都市部はわずかに3.5%を占めているに過ぎないので、それらは皆カバーされているとRajagopalは指摘した。彼は、システムがまだ処理できていない(現在取り組んでいる)地域に、おそらく全設置数の5%が存在しているだろうと見積もっている。
スキャンには1ヶ月かかったが、モデルは147万箇所の設置済ソーラーを発見した(この数には、屋根の上にある数枚のパネルから、大きなソーラーファームまでが含まれている)。これは他の取り組みによって数えられたものよりもずっと多く、最も成功したものであったとしても、DeepSolarのデータが示しているような、正確な位置は提供していない。
こうしたデータの基本的なプロットを行うことで、様々な興味深い新しい情報が得られる。ソーラー設置密度を、州、群、国勢調査区域、あるいは平方マイルのレベルでも比較することが可能であり、それを他の様々なメトリック(年間平均日照日数、家計収入、投票選好など)と比較することもできる。
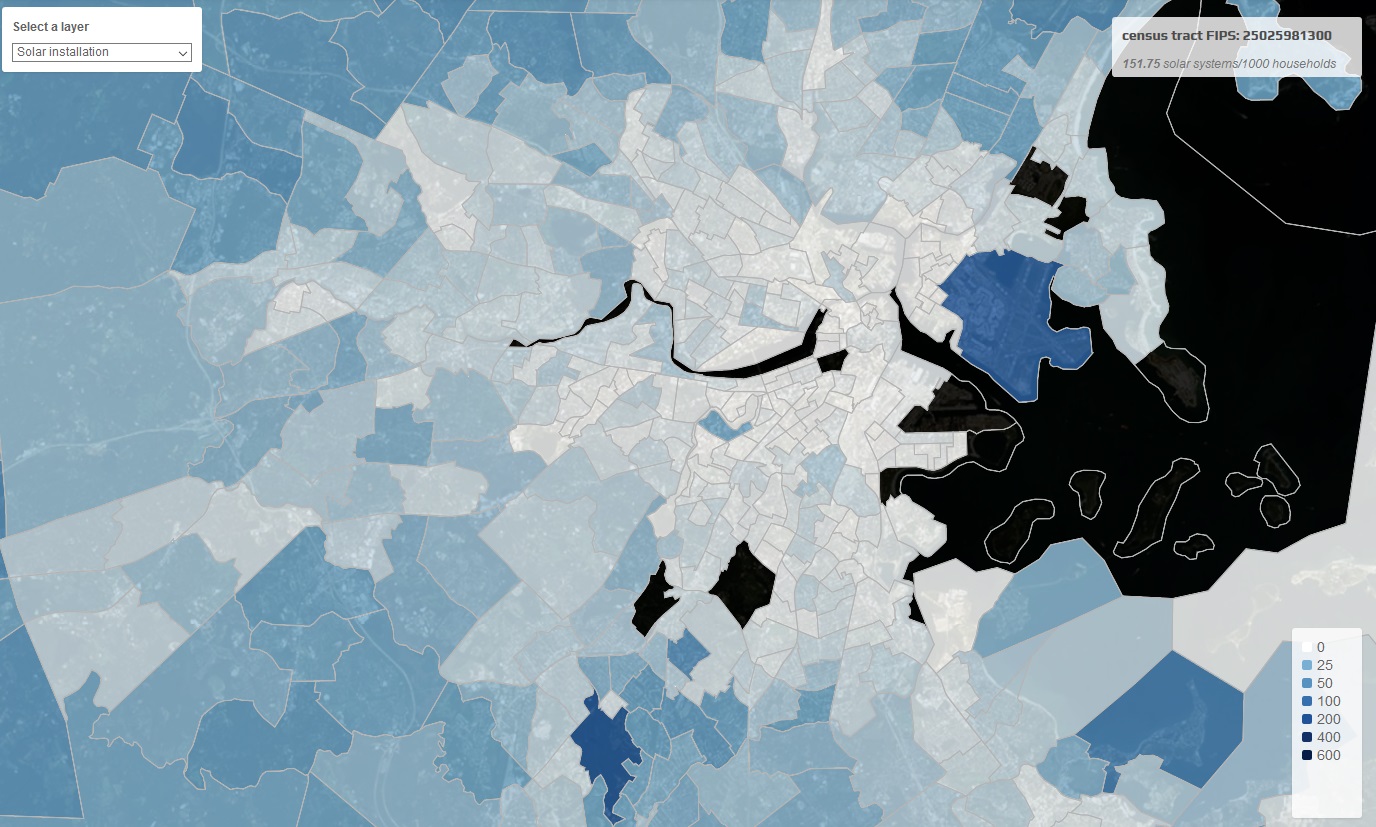
いくつかのの興味深い発見を紹介しておくと、例えば、住宅レベルのソーラーシステムが100軒以上ある(設置密度が高い)のは、すべての国勢調査区域のわずか4%(約7万5000のうち3000)に過ぎない。あるいは、住宅レベルで設置されたソーラーは、総設置数の87%を占めているが、そのサイズの中央値は約25平方メートルに過ぎず、セル表面積の総合計の34%を占めているのに過ぎない。
設置密度のピークがあるのは、1平方マイル(2.56平方キロメートル)あたりの人口が約1000人のエリアだ。これは大都市ではなく、小さな町あるいは都市郊外だと考えれば良いだろう。そして人びとが設置を始める変曲点が存在している:それは1平方メートルあたり1日の日光照射量が4.5kWhを超える地域である。それが天気、場所、日照などと、どのように対応しているかは、より複雑な問題である。
こうしたことをはじめとするデモグラフィックデータ(人口統計データ)は、もしソーラーに投資を考えている場合には参考になる。なぜならそれらは、どの地域がソーラーを必要としているかに関する基本的な情報を提供してくれるからだ。
「私たちは皆さんにデータを眺めて貰えるウェブサイトを作成してリリースしました。データは消費者のプライバシーを考慮して集約されたレベルで示しています(私たちは元のデータは国勢調査レベルで保存しています)」とRajagopalは語る。「私たちはプライバシーに配慮しながら、個別のデータを公開する方法を検討している最中です(おそらく公的機関の参加の奨励とクラウドソーシングを行うことになるでしょう)」。
「私たちは、産業界やアカデミアに属する人びとにデータはもちろん方法論も活用して貰うために、それらをオープンソースとして公開することを決心しました。そこからより多くの洞察を生み出して欲しいからです。私たちは、変化が速く起こる必要があると感じていますが、これはそれを助ける一つの方法なのです。おそらく将来的には、この種のデータを中心に、サービスを構築することができるでしょう」と彼は続けた。
サービスを米国の残りの地域や他の国に拡大する計画も進んでいる。精査できるデータはここにある。あるいはここから地図として閲覧が可能だ。プロジェクトに関して説明したチームの論文は本日(米国時間12月19日)Joule誌に掲載された。
[原文へ]
(翻訳:sako)