
ここ数カ月、Google、Microsoft、 IBM他の有力ライバルがこぞって量子コンピューティングにおける進歩を宣伝する中、 AmazonのAWSは沈黙を守ってきた。またAWSには量子コンピュータ研究の部署がなかった。しかし米国時間12月2日、AWSはラスベガスで開幕したデベロッパー・カンファレンスのre:Invent 2019で、独自の量子コンピューティングサービスとしてBraket(ブラケット)を発表した。
現在利用できるのはプレビュー版で、量子力学計算でよく用いられるディラックが発明したブラケット記法が名称の由来だ。ただしこの量子コンピューティングはAWSが独自に開発したものではない。D-Wave、IonQ、Rigettiと提携し、これらのシステムをクラウドで利用可能とした。同時にAWSは量子コンピューティングの専門組織を整備し、 Center for Quantum Computing(量子コンピューティングセンター)とAWS Quantum Solutions Lab(量子ソリューションラボ)を開設した。
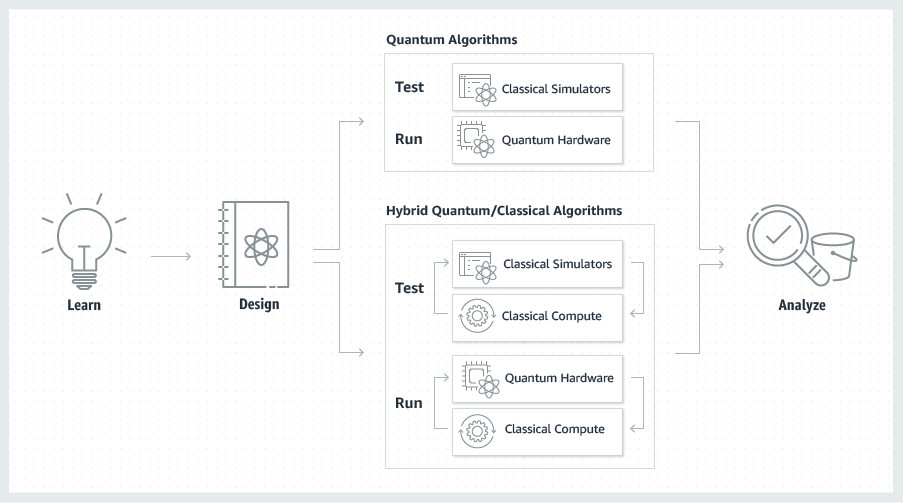
Braketではデベロッパーは独自の量子コンピューティング・アルゴリズムを開発してAWSで実行をシミュレーションできる。同時にAWSを通じて提携パートナーの量子コンピュータハードウェアを用いて実際にテストすることが可能だ。これはAWSとして巧妙なリスクヘッジ戦略だろう。
AWSとしては量子コンピュータを独自に開発するための膨大なリソースを必要とせずに量子コンピューティングをサービスにとり入れることができる。提携先パートナーは自社の量子コンピューティングのマーケティングやディストリビューションにAWSの巨大なユーザーベースが利用できる。デベロッパーや研究者はAWSのシンプルで一貫したインターフェイスを利用して量子コンピューティングを研究、開発することができる。従来、個別の量子コンピューティングにアクセスするのは手間のかかる作業であり、いくつもモデルを比較してニーズに適合した量子コンピューティングを選ぶのは非常に困難だった。
Rigetti Computingの創業者でCEOのチャド・リゲッティ(Chad Rigetti)氏は「AWSとの提携により、我々のテクノロジーを広い範囲に提供することが可能になった。これは量子コンピューティングというマーケットの拡大を大きく加速するだろう」と述べた。D-Waveの最高プロダクト責任者、R&D担当エグゼクティブ・バイスプレジデントのアラン・バラツ(Alan Baratz)氏も同じ趣旨のことを述べている。
【略】
AWSが自社のデータセンターに直接量子コンピュータを導入したわけではないのが重要なポイントだ。簡単にいえばAWSは複数の量子コンピューティングに対して多くのユーザーになじみがある一貫したインターフェイスを提供する。個々の提携先企業はすでに量子コンピューティングを自社のラボやデータセンター内で稼働させていたが、それぞれインターフェイスが異なるため外部のユーザーがアクセスするのが難しかった。
これに対してBraketはAWSの標準的インターフェイスを通じて他のクラウドサービスと同様のマネージドコンピューティングを提供する。またデベロッパーはオープンソースのJupyter notebook 環境を通じてアルゴリズムをテストできる。Bracketにはこれ以外にも多数のデベロッパーツールがプリインストールされているという。また標準的量子コンピューティングやハイブリッドコンピューティングを開発するためのチュートリアル、サンプルも多数用意される。
また新たに開設されたAWSの専門組織は、研究者が量子コンピューティングのパートナーと協力、提携することを助ける。「我々の量子ソリューション・ラボはユーザーが量子コンピュータを開発している各社と提携することを助ける共同研究プロジェクトだ。これにより世界のトップクラスの専門家と提携し、ハイパフォーマンス・コンピューティングを推進できる」とAWSでは説明してる。
研究センター、ラボの開設はAWSにとって長期的な量子コンピューティング戦略の基礎となるものだろう。AWSの過去の動向から考えると、これはテクノロジーそのものの開発というよりむしろサードパーティが開発したテクノロジーに広い範囲のユーザーがアクセスできるプラットフォームを提供するところに力点が置かれるものとなりそうだ。
AWSのユーティリティ・サービス担当のシニア・バイスプレジデント、チャーリー・ベル(Charlie Bell)氏は次のように述べた。「量子コンピューティングは本質的にクラウド・テクノロジーであり、ユーザーは量子コンピュータにクラウドを通じてアクセスするのが自然だ。Braketサービスと量子ソリューション・ラボはAWSのユーザーがわれわれのパートナーの量子コンピュータにアクセスする。これにより新しいテクノロジーにどのようなメリットがあるのかは実際に体験できる。また量子コンピューティング・センターは大学を始め広く研究機関と協力し量子コンピューティングの可能性を広げていく」。

[原文へ]
(翻訳:滑川海彦@Facebook)










 ジャシー氏は「AQUAは求められるコンピューティングのパワーをストレージレイヤーに直接もたらす。Amazonの標準的なS3サービスの上位にキャッシュが置かれるため、必要な数のノードに必要なだけスケールできる」と説明した。
ジャシー氏は「AQUAは求められるコンピューティングのパワーをストレージレイヤーに直接もたらす。Amazonの標準的なS3サービスの上位にキャッシュが置かれるため、必要な数のノードに必要なだけスケールできる」と説明した。












