
ワールドカップのシーズンなので、機械学習の記事もフットボールを取り上げないわけにはいかない。その見事なゲームへの今日のオマージュは、試合の2Dビデオから3Dのコンテンツを作り、すでに拡張現実のセットアップのある人ならそれをコーヒーテーブルの上でも観戦できるシステムだ。まだそれほど‘リアル’ではないが、テレビよりはおもしろいだろう。
その“Soccer On Your Tabletop”(卓上サッカー)システムは、試合のビデオを入力とし、それを注意深く見ながら各選手の動きを追い、そして選手たちの像を3Dモデルへマップする。それらのモデルは、複数のサッカービデオゲームから抽出された動きを、フィールド上の3D表現に変換したものだ。基本的にそれは、PS4のFIFA 18と現実の映像を組み合わせたもので、一種のミニチュアの現実/人工ハイブリッドを作り出している。
[入力フレーム][選手分析][奥行きの推計]

ソースデータは二次元で解像度が低く、たえず動いているから、そんなものからリアルでほぼ正確な各選手の3D像を再構成するのは、たいへんな作業だ。
目下それは、完全にはほど遠い。これはまだ実用レベルではない、と感じる人もいるだろう。キャラクターの位置は推計だから、ちょっとジャンプするし、ボールはよく見えない。だから全員がフィールドで踊っているように見える。いや、フィールド上の歓喜のダンスも、今後の実装課題に含まれている。
でもそのアイデアはすごいし、まだ制約は大きいけどすでに実動システムだ。今後、複数のアングルから撮ったゲームを入力にすることができたら、それをテレビ放送のライブ中継から得るなどして、試合終了数分後には3Dのリプレイを提供できるだろう。
さらにもっと高度な技術を想像すれば、一箇所の中心的な位置からゲームを複数アングルで撮る/見ることも可能だろう。テレビのスポーツ放送でいちばんつまんないのは、必ず、ワンシーン==ワンアングルであることだ。ひとつのシーンを同時に複数のアングルから自由に見れたら、最高だろうな。
そのためには、完全なホログラムディスプレイが安く入手できるようになり、全アングルバージョンの実況中継が放送されるようになることが、必要だ。
この研究はソルトレイクシティで行われたComputer Vision and Pattern Recognitionカンファレンスでプレゼンされた、FacebookとGoogleとワシントン大学のコラボレーションだ。

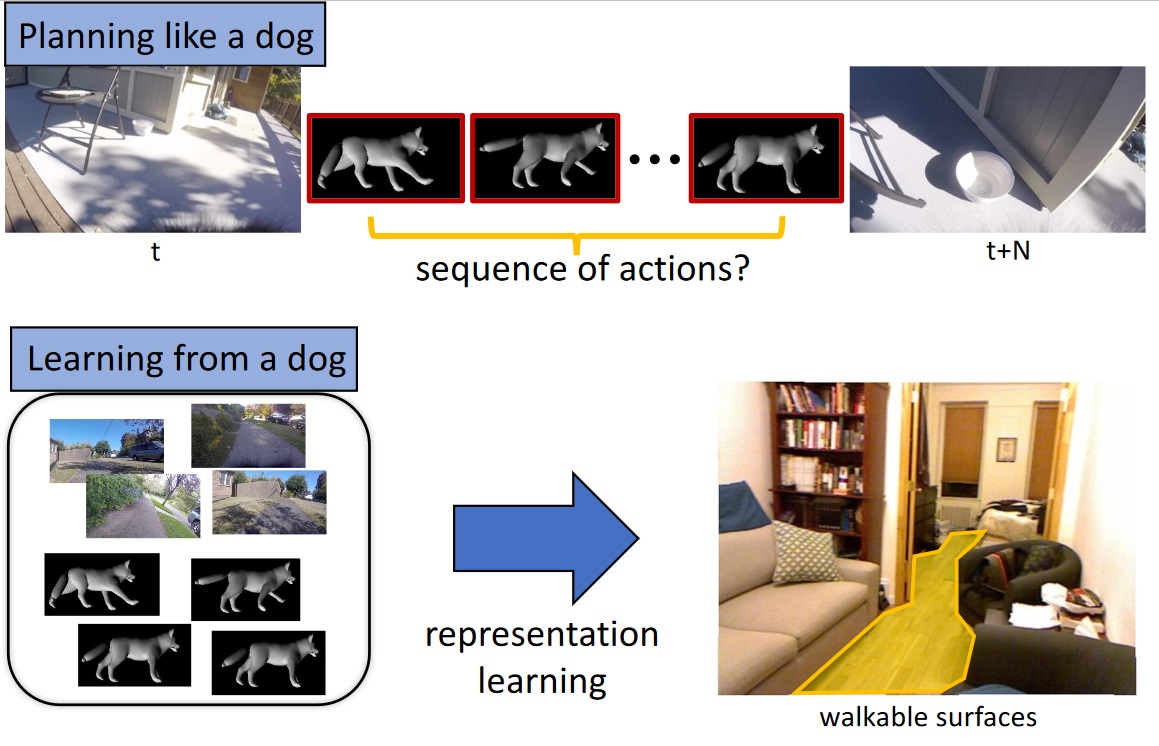 これは、かなり複雑なデータも生成することが可能だ。例えば犬のモデルは、本物の犬自身がそうしている様に、ここからそこまで歩く際に、どこを歩くことができるのかを知らなければならない。それは木の上や車の上、そして(家庭によると思うが)ソファの上を歩くことはできないからだ。したがって、モデルはそれらも学習する。その結果は別途コンピュータービジョンモデルとして利用され、ペット(もしくは脚付きロボット)が、見えている画像のどこを歩くことができるのかを決定するために利用できる。
これは、かなり複雑なデータも生成することが可能だ。例えば犬のモデルは、本物の犬自身がそうしている様に、ここからそこまで歩く際に、どこを歩くことができるのかを知らなければならない。それは木の上や車の上、そして(家庭によると思うが)ソファの上を歩くことはできないからだ。したがって、モデルはそれらも学習する。その結果は別途コンピュータービジョンモデルとして利用され、ペット(もしくは脚付きロボット)が、見えている画像のどこを歩くことができるのかを決定するために利用できる。