
[筆者:Derrick Harris ]
編集者注記: Derrick HarrisはMesosphereのシニアリサーチアナリスト。Harrisは最近GigaOMに、クラウドとビッグデータについて書いた。
インターネットはこれまでの20年間で生活を大きく変えた。Webとモバイルのアプリケーションで、どこからでも、情報の検索と買い物とスムーズなコミュニケーションができ、しかもそのスピードは、これまでありえなかったほどに速い。車のダッシュボードでおすすめの映画を知り、携帯電話でビデオの制作と掲載ができる。温度計を買えば、仕事に出かける時間に暖房を消してくれる。
テクノロジ業界の外にいる人には、これらの技術進歩がマジックのように見えるかもしれないが、実際にこれらのアプリケーションを作っている人たちは、そこにどれだけ多くのものが込められているかを理解している。でも最近ではビジネスの世界にいる人たちみんなが、それを理解していることが重要になりつつある。
その理由は簡単だ: 優秀な企業は、次の10年の企業競争で落伍しないためにはITについてまったく新しい考え方をしなければならないことを理解している。モバイルアプリから冷蔵庫に至るまでのあらゆるものが、さらに一層個人化され、一層インテリジェントになり、より機敏に反応しなければならない。企業は機械学習を行い、センサのデータを取り入れ、ユーザのトラフィックの予期せざる急騰に無事に対応しなければならない。
後戻りはできない。アプリケーションが、ユーザが期待する体験を提供できなければ、彼らは、それを提供できるほかのアプリケーションを見つけるだろう。
アプリケーションのアーキテクチャの革命
アプリケーションとWebサイトのユーザは、過去数年間で百万のオーダーに達し、アプリケーションのそれまでのアーキテクチャは、その膨大な量のトラフィックとユーザデータに対応できなくなっている。さらに最近では、その大量のデジタルデータを有効利用しようという欲求が生まれ、その目的だけに奉仕するまったく新しい種類の技術への関心が芽生えてきた。
それらの技術には多くの場合、サーバの複数のクラスタにまたがって容易にスケールできるように設計された新しいストレージや処理能力、およびデータベースのフレームワークを作ることが含まれている。またさらに、これら各部位間の情報の移動を単純化し、高速化することも求められる。GoogleやLinkedIn、Facebook、Yahoo、Twitterなどの大きなインターネット企業では、この同じ一般的パターンが、何度も何度も繰り返し実装されている。
たとえばデータベースのレイヤでは、ほとんど誰もが関係データベースからスタートし、今になって新しいプランを考えなければならなくなっている。一部の企業は、MySQLデータベースをその自然な限界を超えて酷使するために、秘かに何百万ドルもの費用と人時間を投入し続けている。逆に新しいデータベース技術を作ったところもあるし、新旧の二股をかけているところもある。
またビッグデータの処理でも、新しいパターンが生まれている。具体的な技術はさまざまでも、今の大型Web企業に共通している新しいアーキテクチャは、データ処理のリアルタイム部分と、準リアルタイム部分と、バッチ部分という三層構造だ(下図)。必要に応じて、個人化されたWeb体験やコンテンツ体験をリアルタイムで高速に提供しなければならない。しかしまた同時に、社内のデータアナリストやデータサイエンティストたちが、データの集合に対して彼らの能力を十二分に発揮できなければならない。
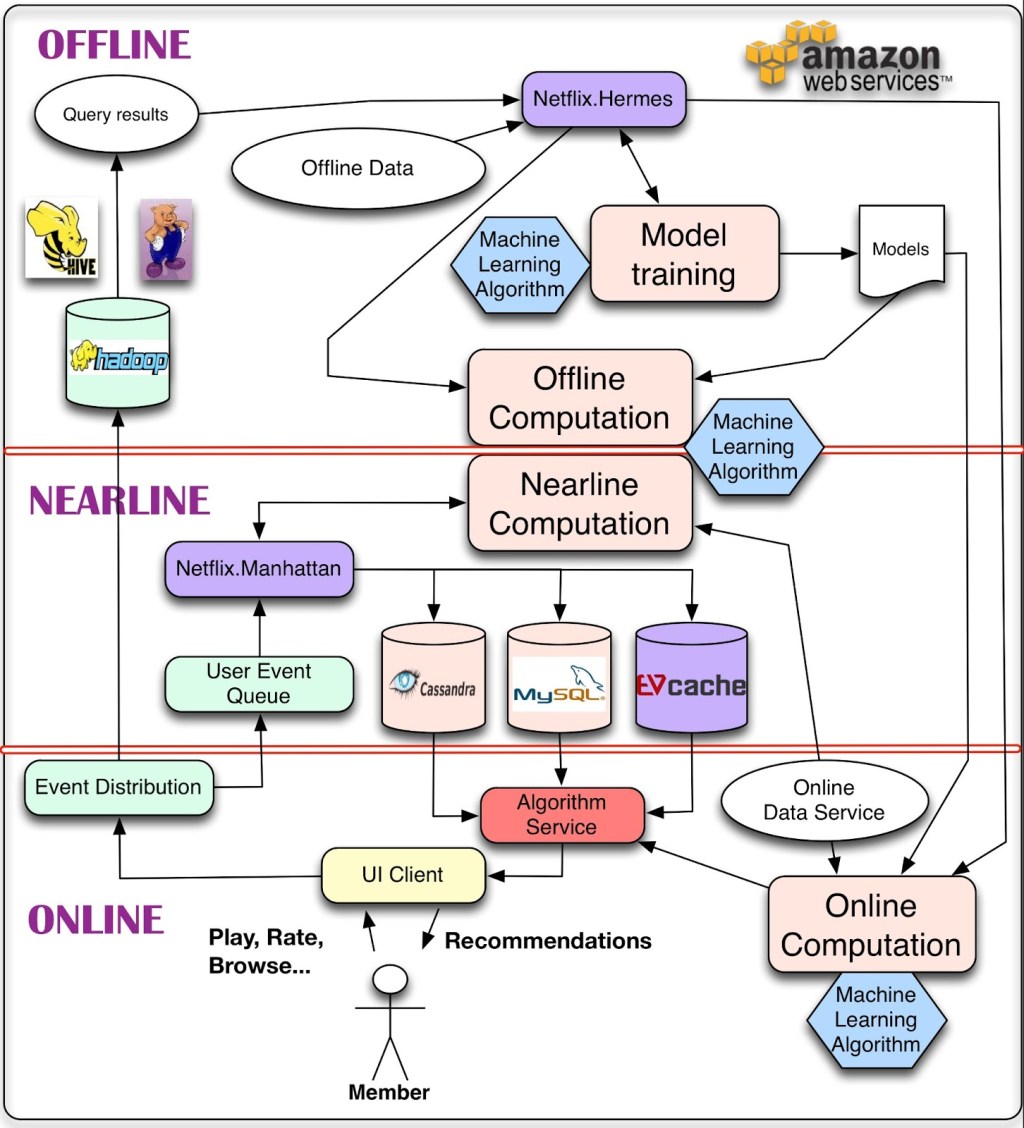
アプリケーションの構成部位としてのデータセンター
今ITに起きているイノベーションは、ものすごいスケールだ。GoogleやFacebook、Amazonなどは日々数十億のユーザに奉仕し、数百万件のユーザ対応処理が並列で行われている。それと同時に、大量のデータが保存される。しかしそれでも、彼らはめったにクラッシュしない。Twitterも、インフラストラクチャに思い切った投資をしてからは、あのfail whale(クジラさん)が現れなくなった。
これらの企業はこれまで、MapReduce、Hadoop、Cassandra、Kafkaなどなど、数々の技術を生み出してきた。また無名のスタートアップやデベロッパたちも、主にオープンソースの世界で、アプリケーションのパフォーマンスをとスケーラビリティを高め、ときにはまったく新しい機能を実現するための新しいツールを作ってきた。それらの中では、Spark、Storm、Elasticsearchなどがとくに有名だ。
また、そのような極端に巨大なスケールでも安定して動くアプリケーションを開発するための、アプリケーションの新しいアーキテクチャも生まれてきた。
たとえば、今いちばんもてはやされているのがマイクロサービスだ。これはアプリケーションを個々のサービスの集合として構成するアーキテクチャで、部品であるサービスは複数のアプリケーションから使われてもよい。これまでの、一枚岩的なアプリケーションアーキテクチャでは、各部位がそのアプリケーションの専用の部品として閉じ込められている。しかし、自立した個々のサービスの集まり、という新しいアーキテクチャでは、各部位間や、部位と特定のアプリケーションとのあいだの依存性がなくなり、サービスのスケールアップをアプリケーションの再構築を必要とせずに実現できる。
また、マイクロサービスと並んでビッグなトレンドになっているのが、コンテナ化だ。コンテナは、Dockerのようなデベロッパフレンドリなフレームワークを利用して作ってもよいし、もっと低レベルにLinux control groupsを使ってもよい。コンテナに収めたアプリケーションは分散サービスに容易にプラグインでき、いつ何をどこで動かすか、などをいちいち気にする必要がなくなる。コンテナがあることによってデベロッパは、自分のアプリケーションの機能や構造の磨き上げに集中できる。
以上のような、分散サービスの集合体とコンテナ化という新しいアーキテクチャ技術を一つの全体として見た場合には、それを“data center application stack”(データセンターアプリケーションスタック==アプリケーションの基本構成要素としてのデータセンター)と呼べる。奉仕すべきユーザが複数のプラットホーム上に何百万もいるようなアプリケーションを作り、それらのアプリケーションが多量かつ多様なデータをハイスピードで利用していくときには、どうしてもそういう、サービスの集合体的なものを使うことになる。したがって高性能なデータセンターが、いわば、アプリケーションの心臓部になる。
これらは、将来そうなるという説ではなくて、今急速に進展しているトレンドだ。巨大な消費者アプリや、Salesforc.comのような巨大なビジネスアプリケーションを志向するスタートアップたちのあいだでは、これらの技術がすでに常備品になっている。
またデベロッパやスタートアップだけでなく、企業も変わりつつある。Fortune 500社だけでなく、ITのイノベーションとは無縁と思われていた中規模の企業ですら、インターネットの時代に対応しようとすると変わらざるをえない。したがって彼らも、今ではデータセンターが提供するサービスに関心を持ち始めている。データセンターのアプリケーションスタック化は、企業の内部にも浸透していく。
“ビッグデータ”と“リアルタイム”と“物のインターネット(IoT)”は、今や単なるバズワードではなく、21世紀の経済において企業の成功を左右する必修科目だ。
そしてデータセンターアプリケーションのためのオペレーティングシステムが
しかしこれらはいずれも、実装が難しい。Hadoopをデプロイして管理してスケールする。Cassandraを〜〜〜〜。Kubernetesを〜〜〜〜。等々。使用するフレームワークやサービスごとに、あなたは手を洗って同じことを繰り返す。実装の困難さは、口にしてもしょうがないから、誰も口にしない。だから、世に氾濫する‘かっこいい話’には出てこない。
でもある時点で企業は、それまでのアプリケーションの書き方を反省し、データのパイプラインを築くことで、より強靭なアーキテクチャを確保したくなるだろう。
GoogleやMicrosoftのような、大きくてエンジニアをたくさん抱えている企業は、この問題をBorgやAutopilotなどのシステムを自分で作って解決してきた。こういうシステムがあると、リソースの適正な割り当てを自動的にやってくれるから、何百万台ものサーバにまたがって動くサービスやアプリケーションの高い可用性が確保される。デベロッパやソフトウェアアーキテクトが頑張らなくても、アルゴリズムが、どこで、何を、どれだけのマシンの上で動かすかを決める。
しかし、BorgもAutopilotもすばらしいシステムだが、どちらもプロプライエタリだ。Googleが某論文の中で、Borgというものの存在を認めたのも、ごく最近のことだ。MicrosoftはAutopilotについて、ほとんど何も明らかにしていない。そしてBもAも、一般的なサービスとしては提供されていない。
そこで、Mesosphereだ、というお話になるのだが、それは次の機会のお楽しみに。

〔原文のコメントに、Microsoftの元社員からの反論があります。〕

{kind=link}