公益事業をサポートする社会貢献財団「日本財団」は、「手話言語の国際デー」(9月23日)を目前に控えた9月22日に、手話学習オンラインゲーム「手話タウン」を正式公開し、発表会を開催した。同アプリは、香港中文大学、関西学院大学、Googleの協力を得て、ベータ版を公開していたもの。
香港中文大学と関西学院大学は、各国の手話データの収集やろう者に関する知見の提供を、またGoogleは、プロジェクトのコンセプト立案と機械学習用オープンソースライブラリー「TensorFlow」を活用し、人のポーズとジェスチャーを認識する「PoseNet」、口と顔の表情を認識する「Facemesh」、手の形と指の検出をするハンドトラッキング(Hands)といった3つの機械学習モデルを組み合わせた手話動作の検出技術を開発するといった役割を担った。
発表会では、日本財団会長の笹川陽平氏、開発チームの中心となった日本財団特定事業部True Colorsの川俣郁美氏、自身もろう者で「聞こえない人あるある」など耳の聞こえない人の日常を「ユリマガール」として発信しているYouTuber くろえ氏が登壇。手話言語を取り巻く日本の環境や、手話タウンにかける思いなどを語った。
日本では手話が言語認定されていない?
まず笹川氏は、国連総会で決議された「手話言語の国際デー」について触れ、「日本は障害者権利条約を批准しているにもかかわらず手話を言語として認めていない」という現状を語った。

日本財団会長の笹川陽平氏
「手話言語法制定がなかなか進まず、手話を言語として認めない状態では、障害者雇用も一向に進まない」とのことで、民間の大企業に関心を持ってもらうよう日本財団が働きかけてきたという笹川氏。
「世界には約15億人の障害者がいるという。働く能力も情熱もある彼らは、ビッグマーケットでもある。健常者には汲み取れないニーズを理解できる障害者を雇い入れることで、障害者が本当に必要とするような製品開発も進む。
すでにGoogleやMicrosoft、SONYや日立など大企業500社がタッグを組んで障害者雇用を率先して行っている。アフターコロナはこのようなダイバーシティ&インクルージョンが一気に進むだろう」(笹川氏)
「その取り組みのひとつが『手話タウン』。誰もが共に働ける社会の実現に向け、手話に気軽に触れてもらいたい」とあいさつをした。
手話タウンは手話への入り口
続いて登壇した川俣氏は、手話で手話タウンが生まれた背景、概要、目指すところについて説明した。

日本財団特定事業部True Colorsチーム 川俣郁美氏
聴覚障害者は世界で4億6600万人。会話はできるけれど聞き取りづらい、飛行機の轟音さえ聞こえないなどレベルは様々だが、20人に1人が聞こえで課題を持っていることになる。
そのうち、手話を日常的に使うろう者は20%。つまり、世界人口の100人に1人が手話でコミュニケーションをとっている。

ここでひとつ思い出したいことがある。私たちが「物心ついた時」というのは、言葉を覚え始めた頃ではないだろうか。つまり、言語と思考には密接な関連があるということだ。
音のない世界で生活するろう者(ここでは、手話の未習得者で耳の聞こえない人のこと)は、手話という言語を習得することにより、自分の意志を相手に伝え、相手のことを理解し、学習し、思考することができるようになる。このことから手話がコミュニケーションというものを超越した“生きることの基盤である”、ということが理解できるだろう。
しかし、「国内では手話を言語として認めないだけでなく、手話への理解も少ない」と川俣氏。「米国では手話を第2言語として教える手話クラスのある公立高校が1100校あるが、国内で手話を授業に総合学習のような形でも取り入れたことのある学校がある市区は38.3%(230市区)、に過ぎない。大学など高等教育機関に至っては、手話を語学として講義を行っているのが9校であるのに対し、米国では第2言語として792校がコースを開講している。西語、仏語に続き3番目に多く履修されている言語だ」と解説した。

「自治体で手話の講習会を開いているところもあるが、教育機関として学べる米国のように、体系的かつ若い時から学んで触れる機会がない日本では、ろう者が生活していく上で難しい場面も多い。
少しでも手話を身近なものと感じてもらいたい、手話に触れる入り口にしてもらいたい、という想いで手話タウンを開発した」(川俣氏)
公式版は、よりフレンドリーなユーザーインターフェースに
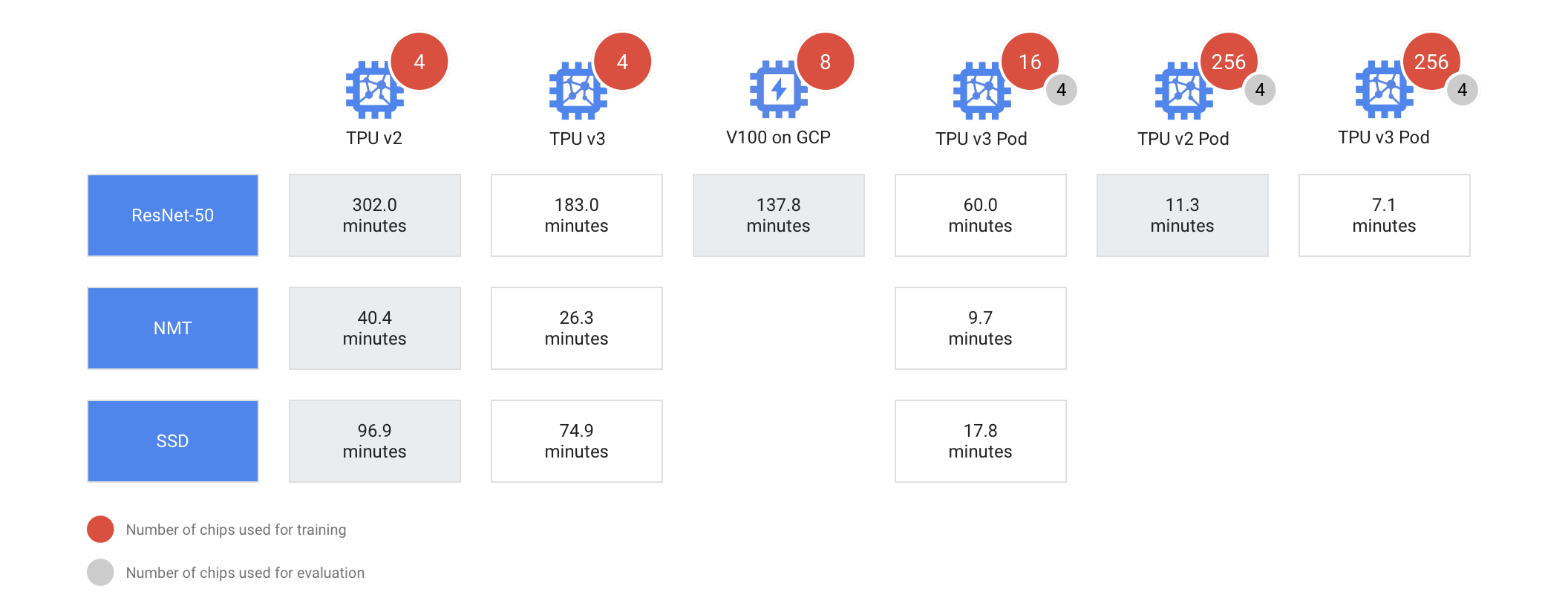
5月24日にリリースした手話タウンベータ版の体験者約8500人(延べ)から得たフィードバックにより、公式版では次のような改良が加えられた。
- チュートリアルの追加
- 見本動画の拡大・スロー再生機能追加
- 見本動画と自分の手話の比較表示機能追加
手話は、顔だけでなく肘を含む手の動きで表現する。そのため、一般的なビデオ会議のとき以上にPCのカメラから離れる必要がある。どれほど離れる必要があるのか、正しく認識されているかをチェックするために、チュートリアルが追加された。

遊び方の説明も追加された。どのようにプレイするかが一目瞭然

チュートリアルではカメラの位置(実際には自分の位置)調整、認識するのに体のどの部分が必要なのかが、よりわかりやすくなった
スロー再生(0.25倍速再生)で細かい動きをしっかり把握しやすく
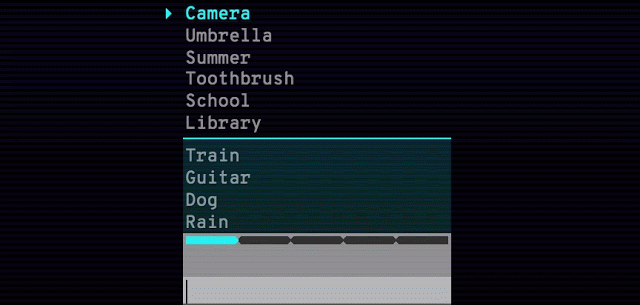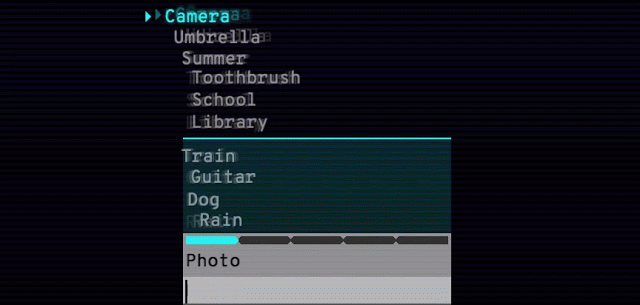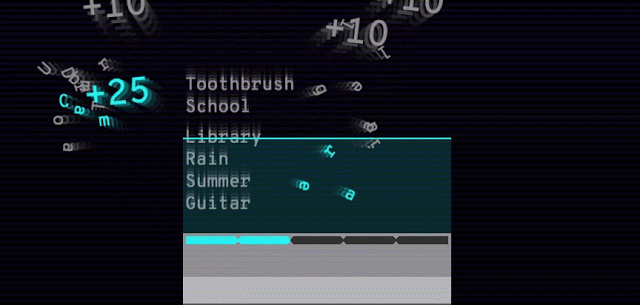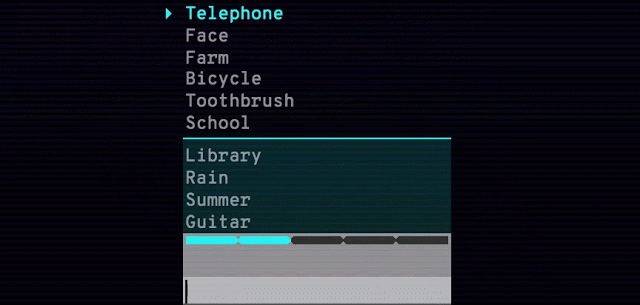
また、ベータ版では見本となる動画が小さく、動きも早かった。また、2つの窓で同時に表現するため、目がさまよってしまい、選んで表現したいと思う側に注目できないという課題も合った。実際、筆者も「これは指を何本立てているのか」「右下? 真下?」と戸惑うことが多かった(ダンスなどの振り付けを覚えにくいという特性も関係しているが……)。それが正式版では、拡大表示することで1ウィンドウで大きく見られるようになり、その状態でスロー再生(0.25倍速再生)して、しっかり動きを把握できるようになった。

以前の見本動画の一例。並べて表示するため小さく、目がさまよってしまう

正式版ではそれぞれの見本動画を拡大表示できるようになった。また「0.25x」をクリックすればスロー再生も可能。細かなところまで確認できる

地味な追加要素ながら、文字のわからない子どもや外国語話者でも理解できるよう、それぞれの見本動画の左上に、表現したいものを表すアイコンが添えられるようになった
見本動画と自分の手話表現の動画を見比べて、客観的に違いを確認できるように
最後は、自分の手話表現が「間違い」だったときに、見本動画と自分の手話表現の動画を横に並べることで、どこが違うのかを見比べられるよう比較表示機能が追加された。自分では完璧に真似をしているつもりでも、客観的に「そうじゃない」ということがわかるというわけだ。

手話タウンは「プロジェクト手話」の一環、音声からの手話作成や手話から音声への翻訳などの目標も
公式版になった手話タウンをプレイした くろえ氏は、「キャラクターがかわいらしいので、小さな妹と一緒にプレイできる。今、日本語手話だけでなく外国語手話に興味があるので、香港手話を学べるのはありがたい。今後、ほかの国の手話も学べるとうれしい。友人と一緒に遊んでみたい」と感想を語った。

「ユリマガール」YouTuber くろえ氏
川俣氏は、「手話タウンは、『プロジェクト手話』の一環に過ぎない。将来的には音声から手話を自動的に作成したり、手話から音声へ翻訳したりするという大きな目標がある。今は3場面、36単語しか学べない、またPCのウェブブラウザーからしかアクセスできない手話タウンだが、今後は単語数を増やし、スマホやタブレットでも遊べるようにしていきたい」と今後の抱負を述べた。
また、発表会後、個別取材に対応したTrue Colorsチーム チームリーダー青木透氏は「手話タウンは、手話に触れる門戸を広げることが第一の目的なので、今はアカウントの作成や登録なしにプレイしてもらえる仕様になっている。しかし、場面や単語数が増えた将来には、習熟度をチェックしたいというニーズも増えてくるだろう。協力者である香港中文大学、Google、関西学院大学と共に、アカウント方式にするかしないかを検討するようになるかもしれない」と話していた。