
もし私があなたにある部屋の一枚の写真を見せたなら、おそらくあなたはすぐに、目の前テーブルがあり、その前に椅子が置かれていて、両者はおそらくほぼおなじ大きさで、だいだいこれくらいお互いに離れていて、壁からはこれくらい離れているといったことを、すぐに説明できるだろう。その部屋のざっとした見取り図を書くのには十分だ。コンピュータビジョンシステムは、このような空間理解への直感を有してはいないが、DeepMindを用いた最新の研究は、これまで以上にその境地に近づきつつある。
このGoogleの研究組織から発表された新しい論文は、本日(米国時間6月14日)Science誌に掲載された(研究を引用したニュース記事も添えられている)。この論文が詳述するシステムは、事実上何も知らないニューラルネットワークが、1、2枚の静的2次元映像を見るだけで、ほぼ正確な3Dモデルを構築するというものだ。なお、ここで話題にしているのは、複数のスナップショットから完全な3D画像を構築する(Facebookがそれに取り組んでいる)という話ではなく、人間が世界を観察して分析する際の、直感的で空間的な認知を模倣しようとする試みだ。
私が「事実上何も知らない」と表現するとき、それはただ標準的な機械学習システムであるということを意味してはいない。ほとんどのコンピュータビジョンアルゴリズムは、教師付き学習と呼ばれるものを介して動作する。教師付き学習では、人間が正しい解答を付けた大量のデータを取り込む。
一方、この新しいシステムは、頼りにできるそのような知識は保有していない。物体の色が端に向かってどのように変化していくのか、距離が変わるにつれてどのくらい物体が大きくなったり小さくなったりするのかといった、私たちが行っているような世界を見る方法とは、完全に独立して動作する。
大まかに言えば、これは以下のように動作する。システムの半分は 「表現」(representation)部であり、これは与えられた3Dシーンをある角度から観察して、それをベクトルと呼ばれる複雑な数学的形式で符号化することができる。そして残りの半分は「生成」(generative)部である。こちらは先に作られたベクトルだけに基づいて、シーンの異なる部分がどのように見えるかを予測する。
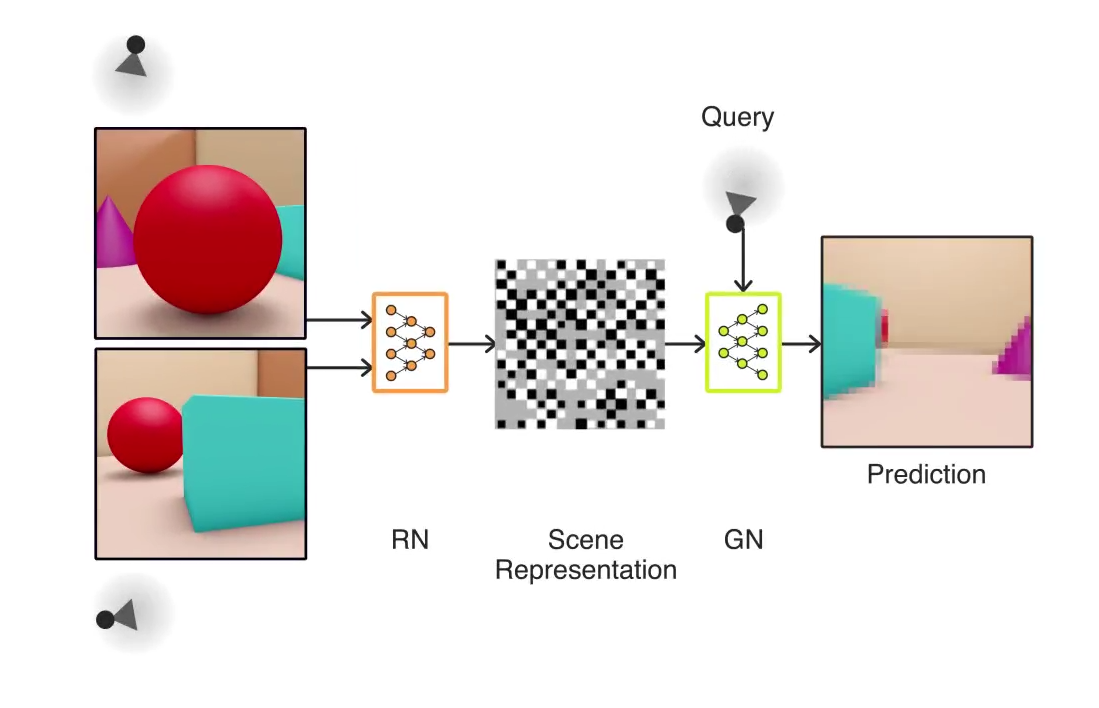
(この仕組みをもう少し詳しく見せてくれる動画はこちら)。
例えばあなたに、ある部屋の写真を何枚か手渡してくる人がいると考えて欲しい。そしてその人はあなたに、その部屋のある特定の場所に立ったときに見える景色を予想して描いてくれと依頼してくる。このシステムが行うのはそのような予想なのだ。繰り返すが、これは私たち人間にとっては造作もないことだ。しかしコンピューターはそのようなことを自然に行う能力は持っていない。彼らの視覚(もし私たちがそう呼べるとしての話だが)は極めて初歩的で、想像力に欠けたものである。もちろん機械自身も想像力を欠いている。
しかし、隠れて見えないものが何かを言う能力を表現するための、適切な言葉はほとんど存在していない。
「ニューラルネットワークがこれほど正確かつ制御された方法で画像を作成することを学ぶことができるかどうかは、まったく明らかではありませんでした」と論文と共にリリースされた記事で語ったのは、論文の筆頭著者であるAli Eslamiだ。「しかしながら、私たちは十分に深いネットワークは、人間工学を用いなくても、視点、遮蔽、照明について学ぶことができることを発見しました。これは本当に驚くべき発見でした」。
また、次に示されたブロックのような、単一のビューから、3Dオブジェクトを正確に再現することも可能だ。
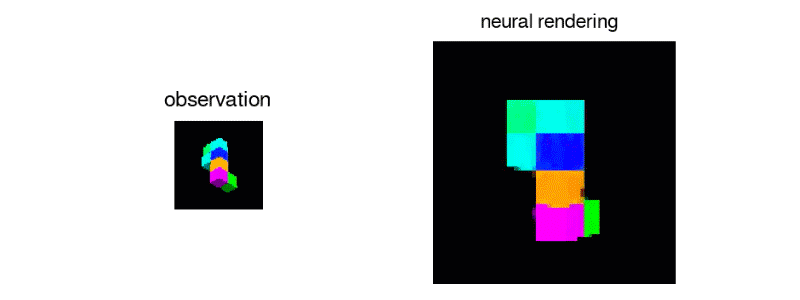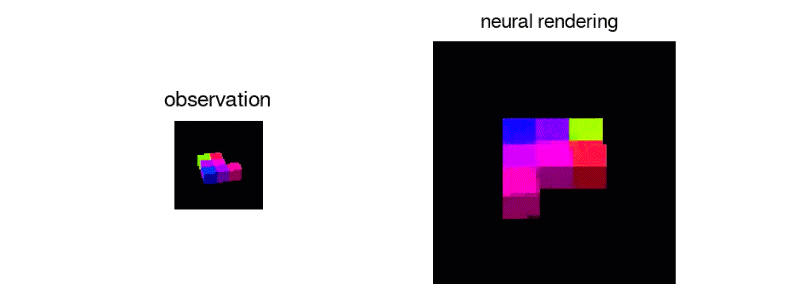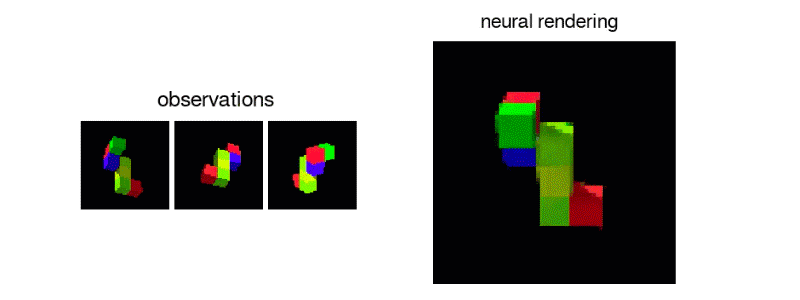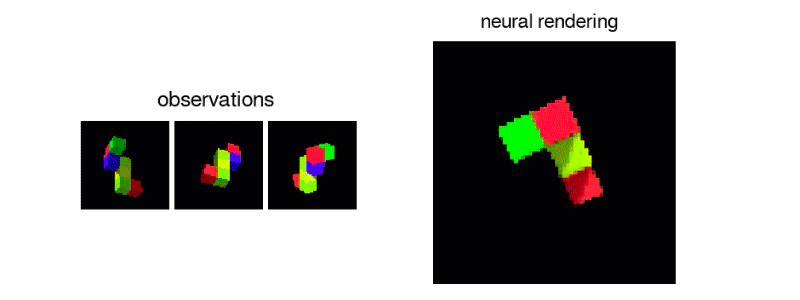
私自身、これをうまくできるかどうか自信がない。
明らかに、1つの視点からでは、ブロックのある部分が、カメラから隠れた方向に向けて遠く伸びているかどうかを知ることはできない。しかし、それは全ての方向から見て正確かどうかはともかく、まずまずもっともらしいブロック構造を生み出す。1つまたは2つ以上の観測を追加することで、システムの複数のビューの修正が迫られるが、その結果さらに良い表現を得ることができる。
このような能力は、ロボットにとっては不可欠なものだ。なぜなら彼らは現実世界を感知し、見たものに反応することによって、現実世界を移動する必要があるからだ。重要な手がかりが一時的に視界から隠されるといった、限られた情報によって、ロボットはフリーズしたり、非論理的な選択を行う可能性がある。しかし、ロボットの頭脳の中で今回のようなことを行うことで、例えば1インチ刻みの情報なしに部屋のレイアウトに対して、合理的な仮定を行うことが可能になる。
「この新しいタイプのシステムを現実世界に導入するには、より多くのデータと高速なハードウェアが必要ですが」とEslamiは語る。「自分で学習するエージェントを構築する方法を理解する方法へと、私たちを一歩付けてくれるのです」。
[原文へ]
(翻訳:sako)