
Enterprise Dropboxに、一部のユーザーが待ち焦がれていたと思われる便利な機能がやってきた。それは画像やPDFファイル中の文字を自動的にテキストデータへ書き起こす光学式文字認識(optical character recognition/reader, OCR)機能だ。これからは、セーブした写真をかき回してレシートを探さなくてもよいし、目的の情報を探してたくさんのファイルを開かなくてもよい。単純に、テキストで検索できるのだ。
Dropboxのテキスト認識エンジンは今後数か月で、DropboxのPro, Business Advanced, そしてEnterpriseアカウントに実装されるが、アーリーアクセスがあるかもしれないから、ときどきチェックしてみよう。
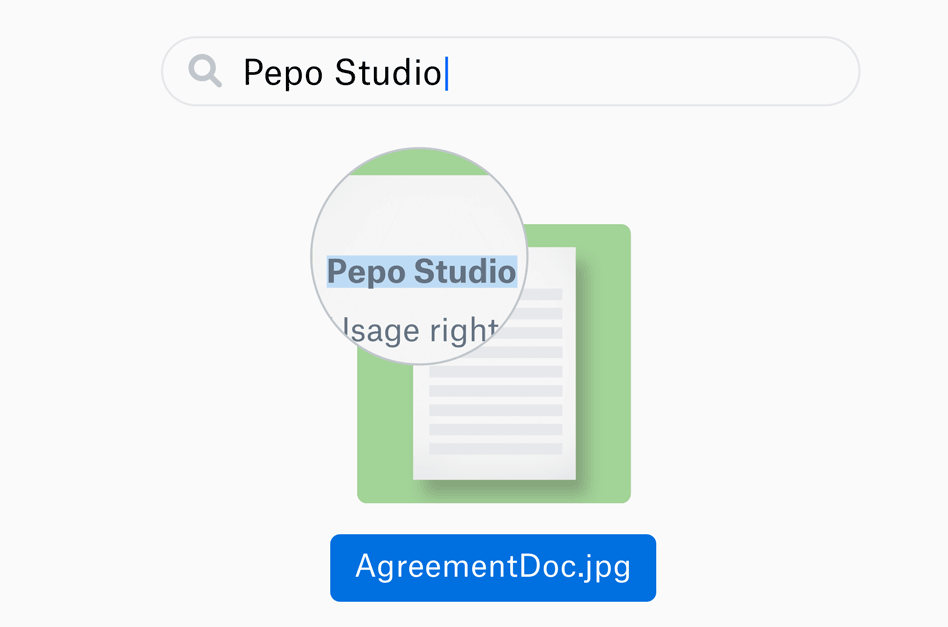
このOCR機能は、ユーザーのすべての画像やPDFをスキャンしてテキストを取り出し、それらをメタデータに加えるので、ユーザーはそれを検索できる。もちろんそのデータは、正規のドキュメントとして安全に保存される。便利だが、問題は書き起こしの精度だ。OCRはときどき、気難しいからね。
Dropboxに永久につきまとう、もっと簡潔な名前のコンペティターBoxは昨年、多機能なOCRを導入した。多機能というのは、文字だけでなくオブジェクト(物)も認識するからだ。これに比べてDropboxのは、機能的にやや劣るかもしれないが、でも日常のOCRニーズには十分だろう。
これまで、指定したドキュメントをOCRすることはできたが、もちろんこっちの方が便利だ。Dropboxの技術情報のブログには、この自動化OCR機能の開発史が語られている。Boxは、GoogleのOCR機能を下敷きにしたらしい。〔訳注: Google Drive -> Google DocsにもOCRがある(全自動ではない)。〕
Dropbox Enterpriseのようなグループアカウントのメンバーは、全員がこの機能を利用でき、しかもこの機能が有効になったときは自動的に、既存のドキュメントもすべてOCRされる。