【抄訳】
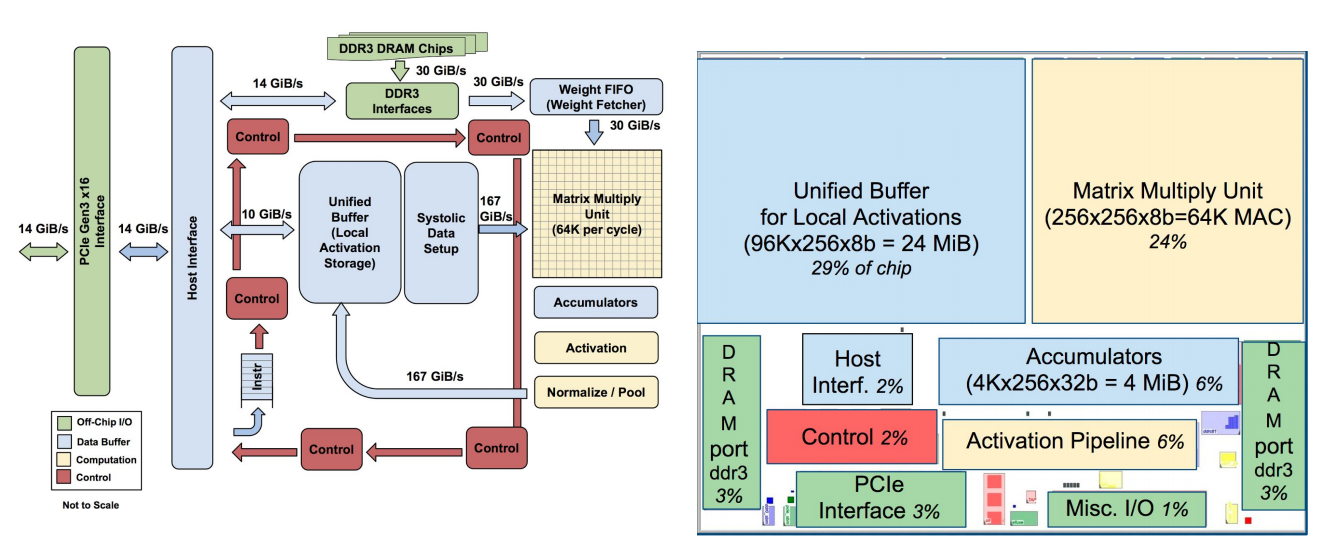
Googleが同社の機械学習アルゴリズムを高速に実行するカスタムチップを独自に開発したことは、前から知られていた。その Tensor Processing Units(TPU)と呼ばれるチップが初めて公開されたのは、2016年の同社のI/Oデベロッパーカンファレンスだったが、詳しい情報は乏しくて、ただ、同社自身の機械学習フレームワークTensorFlowに向けて最適化されている、という話だけだった。そして今日(米国時間4/5)初めて、同社はこのプロジェクトの詳細とベンチマークを共有した。
チップの設計をやってる人なら、Googleのペーパーを読んで、TPUの動作に関するややこしいすばらしい詳細情報を理解できるだろう。でもここで主に取り上げたいのは、Google自身のベンチマークの結果だ(客観的な第三者の評価ではない)。それによるとTPUは、Googleの通常の機械学習のワークロードを、標準のGPU/CPU機(IntelのHaswellプロセッサーとNvidia K80 GPUs)より平均で15〜30倍速く実行できた。また、データセンターでは電力消費が重要だが、TPUのTeraOps/Wattは30〜80倍高い。将来は高速メモリの使用により、これよりもさらに高くなるという。
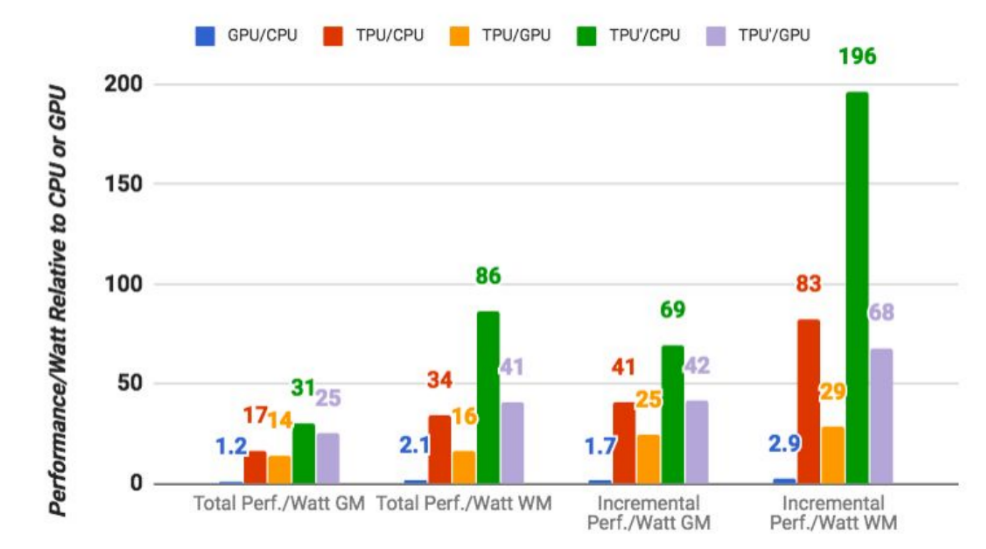
なお、これは実際に使われている機械学習モデルを使った場合の数字であり、モデルの作成は関わっていない。
Googleによると、一般的にこの種のチップはconvolutional neural networks(畳み込みニューラルネットワーク、画像認識などによく使われる)向けに最適化されることが多いが、Googleのデータセンターのワークロードではこの種のネットワークは全体の約5%にすぎず、大多数はmulti-layer perceptrons(多層パーセプトロン)のアプリケーションだ、という。
【中略】
Googleには、TPUを自分のクラウドの外で可利用にする気はないようだが、しかし同社は、これを勉強した誰かが将来、彼らが作る後継機により、“バーの高さをさらに上げる”ことを期待する、と言っている。