Apache Sparkのオリジナル開発者が創業したビッグデータ分析サービスであるDatabricks(データブリックス)は米国時間10月15日、データレイク(構造化データや非構造化データ、バイナリなどのファイルを含めて一元的に格納するデータリポジトリのこと)の構築に使われるDelta LakeオープンソースプロジェクトをLinux Foundationへオープンガバナンスモデルの下に移管することを発表した。同社は今年の初めにDelta Lakeのローンチを発表した。比較的新しいプロジェクトにもかかわらず、すでに多くの組織に採用され、Intel(インテル)、Alibaba(アリババ)、Booz Allen Hamilton(ブーズ・アレン・ハミルトン)などの企業からの支援を受けている。

画像クレジット: Donald Iain Smith / Getty Images
「2013年に、私たちはDatabricks社内で、SQLをSparkに追加する小さなプロジェクトを行っていました、それはその後Apache Foundationに寄付されました」と語るのはDatabricksのCEOで共同創業者のAli Ghodsi(アリ・ゴッシ)氏だ。「長年にわたって、多くの人たちが、Sparkを実際に活用する方法を変えてきました。そしてようやく昨年くらいからでしょうか、私たちが最初に想定していたものとは、全く異なるパターンでSparkが使われ始めていることに気が付き始めました」
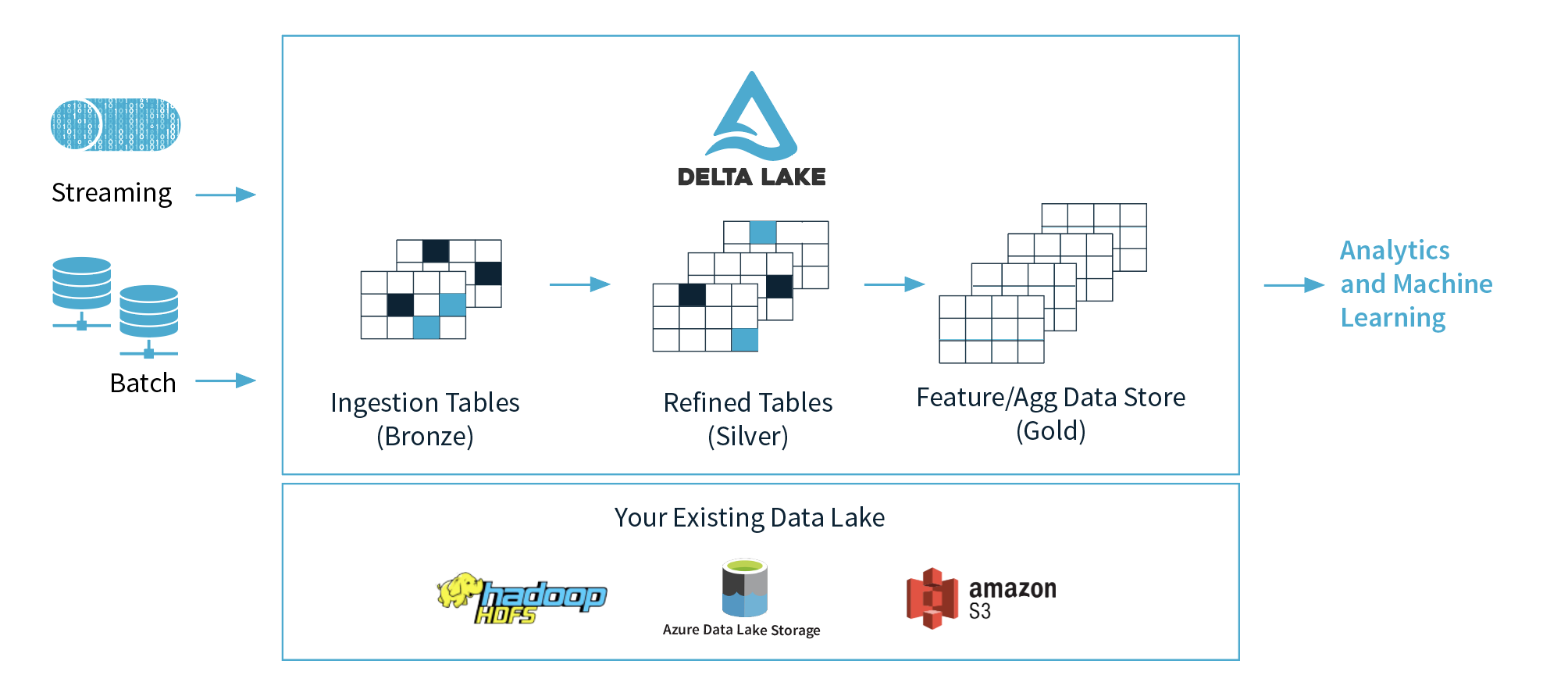
彼によれば、そのパターンとは、企業がすべてのデータをデータレイクに投入し、このデータを使用してさまざまなことを行うというものだ。もちろん機械学習とデータサイエンスは明らかな応用パターンだ。しかも企業はまた、ビジネスインテリジェンスやレポートなど、従来はデータウェアハウスに関連付けられてきたことも行っているのだ。ゴッシ氏がこの種の利用法を指すために使う言葉は「Lake House」(レイクハウス)だ。Databricksは、Sparkが単にHadoopを置き換えたりETL(Extract、Transform、Load)に使われるだけでなく、上記のような目的にますます使用されるようになっていることを理解している。「私たちが目にしたこの種のレイクハウスパターンが、より頻出するようになってきたので、私たちはそれに倍賭けしようと考えたのです」。
 本日リリースされたSpark 3.0は、プラグインなデータカタログをSparkに追加できる新機能に加えて、上記のようなユースケースの多くを可能にし、大幅にスピードアップしたものになっている。
本日リリースされたSpark 3.0は、プラグインなデータカタログをSparkに追加できる新機能に加えて、上記のようなユースケースの多くを可能にし、大幅にスピードアップしたものになっている。
ゴッシ氏によれば、Delta Lakeは本質的にはレイクハウスパターンのデータ層に相当するものだと言う。たとえば、データレイクへのACIDトランザクション、スケーラブルなメタデータ処理、およびデータバージョン管理のサポートをData Lakeは提供する。すべてのデータはApache Parquet形式で保存され、ユーザーは自分でスキーマを適用することができる(必要に応じて比較的簡単にスキーマを変更することもできる)。
Linux FoundationがApache Foundationをルーツに持つことを考えると、DatabricksがこのプロジェクトのためにLinux Foundation選択したことは、興味深い。「彼らと提携できることをとてもうれしく思っています」とゴッシ氏は口にして、同社がLinux Foundationを選んだ理由について以下のように語った。「彼らは、Linuxプロジェクトだけでなく、多くのクラウドプロジェクトを含む、地上最大のプロジェクトたちを運営しています。クラウドネイティブのものはすべてLinux Foundationの中に置かれています」。
「中立的なLinux FoundationへDelta Lakeを移管することによって、このプロジェクトに依存しているオープンソースコミュニティたちが、オンプレミスとクラウドの両方で、ビッグデータを保存および処理する技術を開発しやすくなります」 と語るのはLinux Foundationの戦略プログラムVPであるMichael Dolan(マイケル・ドーラン)氏だ。「Linux Foundationは、データストレージと信頼性の最新技術を向上させて業界の幅広い貢献とコンセンサスの構築を可能にするオープンガバナンスモデルを、オープンソースコミュニティたちが活用しやすくなる手助けをいたします」。
[原文へ]
(翻訳:sako)