セキュリティ関連技術を研究する中国人研究者が、「音」を発せずに音声認識システムを作動させる方法を開発した。人間には聞こえず、しかしマイクでは検知できる高周波音を用いるのだ。このしくみを用いて、人間には音が聞こえない状況で、さまざまなコマンドを発することに成功したのだそうだ。メジャーな音声認識アシスタントのすべてを操作することができたとのこと。
今回の成果を発表したのは浙江大学の研究者たちで、超音波を用いてコミュニケートするイルカたちにならって、用いた仕組みを「DolphinAttack(PDF)」と呼んでいる。しくみをごく簡単に説明しておこう。
音を発せずに音声アシスタントを動かす仕組み
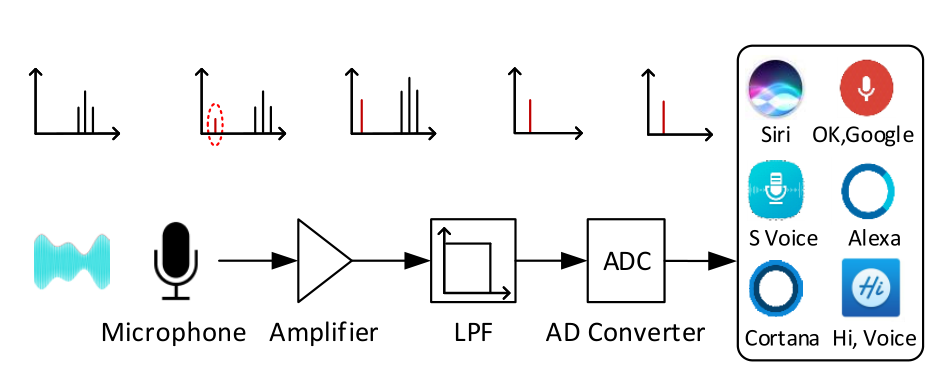
電子デバイスに搭載されるマイクは、音波によって変化する空気圧に反応する小さくて薄い皮膜を利用している。人間はふつう、20キロヘルツ以上の音を感知できないので、一般的なマイクでも20キロヘルツ以上の「音」に反応しない仕組みが搭載されている。その仕組みはローパスフィルタと呼ばれている。
このローパスフィルタ機能が理論通りに機能すれば、たしかに意図した周波数の音声のみに反応することになる。しかし現実には「ハーモニクス」というやっかいなものが存在する。たとえば400Hzの音は、200Hzあるいは800Hzを捉えるようになっているマイクにも捉えられてしまうのだ(正確な仕組みは端折って、効果についてのみ記している。詳細を知りたい方はWikipediaなどを参照してほしい)。ただし「ハーモニクス」は、もとの音声に比べるとかなり小さく響くようになるもので、通常はハーモニクスの存在がなにか問題を引き起こすようなことはない。
ただ、100Hzの音を拾うマイクに対し、何らかの事情で100Hzのを発することができない事情があったとしよう。この場合、音の大きさを大きくすれば、800Hzの音でマイクを反応させることができるのだ。100Hzの音を発したことをさとられずに、マイクのみに100Hzのハーモニクスを伝達することができるのだ。人間の耳には800Hzの音のみが伝わることとなる。
変調装置の仕組み
研究者たちも、大まかにいえば上に記した仕組みをもちいてマイクにのみ通じる音を発生させている。もちろん実際にはさまざまな複雑なプロセスを経るようになっている。そしていろいろと試してみたところでは、スマートフォン、スマートウォッチ、ホームハブなど、音声に反応するように設計されているデバイスのほとんどが、ハーモニクスに反応したとのことだ。

超音波(黒の音声信号)がハーモニクス(赤の信号)を発生させる様子。超音波の方はローパスフィルタによりカットされる。
最初は単なる超音波信号を発生させる実験を行なっていた。それがうまくいったので、次に500ヘルツないし1000ヘルツの音声信号を生成することにしたのだ。複雑な作業が必要になるものの、しかし基本的には同様の方法で音声信号の生成に成功したとのこと。作業が複雑になるといっても、特殊なハードウェアを必要とするわけではない。エレクトロニクスパーツを扱っている店で手に入る部品のみを用いて実現できる。
超音波から生じた音声は確かに機能し、たいていの音声認識プラットフォームで狙い通りに認識されたとのこと。
DolphinAttackで使う音は、人間には聞こえず、感知することすらできません。しかし音声認識を行うデバイスはこの「音声」に反応するのです。Siri、Google Now、Samsung S Voice、Huawei HiVoice、Cortana、およびAlexaなど、いずれのプラットフォームで動作することを確認しました。
超音波から生成した音声により、簡単なフレーズ(「OK、Google」)から、やや複雑なコマンド(「unlock the back door」―勝手口の鍵を開けて)などを認識させ動作させることができたとのこと。スマートフォンによって通じやすいフレーズや通じにくいものがあったり、超音波を発する距離によっても実験結果が左右されたとのこと。ただし、5フィート以上の距離から発した超音波ーハーモニクスに反応したデバイスはなかったとのことだ。
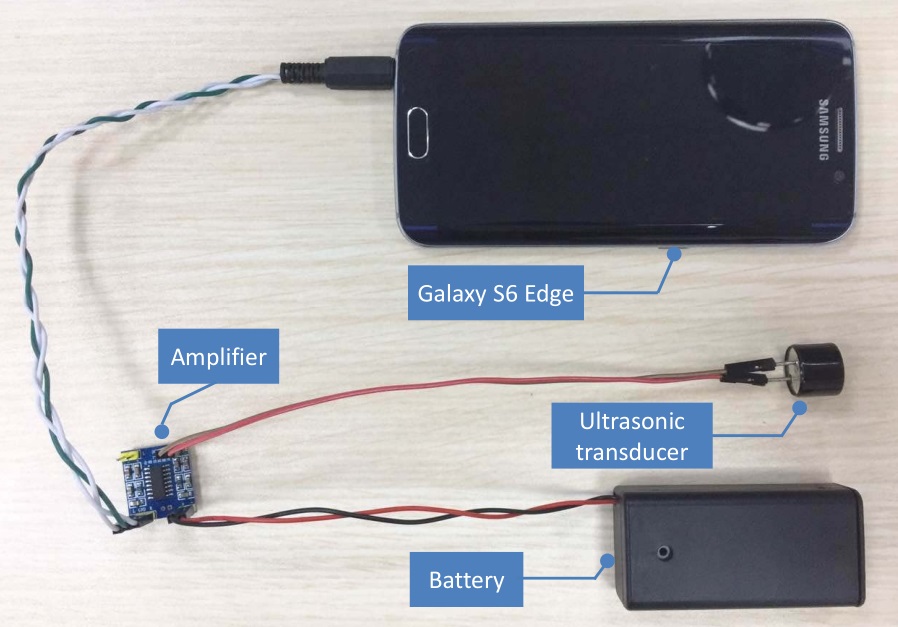
研究で使用した簡単な超音波ーハーモニクス発生システム。
距離に制限があるということのようだが、しかしそれでも脅威に感じる。感知できないコマンドが発せられ、それによって手元のデバイスが作動してしまうのだ(Wi-Fiにも似たようなリスクがないわけではない)。ただし、今のところは大騒ぎすることもないのかもしれない。
たとえば、音声コマンドによってデバイスを活動状態にする機能をオフにしておくだけで、大半のリスクを避けることができるようになる。音声コマンドを受け付けるのは、デバイスがアクティブな状態にあるときのみになるわけだ。
さらに、たとえスリープからの復帰を音声コマンドで行えるようにしていても、たいていのデバイスでは電話をかけたり、アプリケーションを実行したり、あるいはウェブにアクセスしたりする機能を制限している。天候を確認したり、近くのレストランを表示するようなことはできるが、悪意あるサイトへのアクセスなどはできないことが多い。
また、音声コマンドは数フィート以内の距離から発しなければならないというのが一般的だ。もちろん、知らない誰かがすぐ近くから超音波ーハーモニクス音声をもちいてコマンドを発行することはできるだろう。しかし突然スマートフォンがスリープから復帰して、「モスクワに送金しました」などといえば、ただちに適切な対応をすることができるのではなかろうか。
もちろん危険性がゼロでないのは事実だ。超音波を発することのできる、スピーカーを備えたIoTデバイスがEchoに話しかけて、家のロックやアラームを解除するような可能性だってあるわけだ。
直ちにさまざまなリスクに対応する必要があるというわけではないかもしれない。しかし、電子デバイスに対する攻撃を実行しようとするひとたちに、新たな可能性が開かれつつあるのは事実だ。そのリスクを公にし、日常的に利用するデバイスにて対抗手段を備えることが重要になりつつあるといえよう。
[原文へ]
(翻訳:Maeda, H)