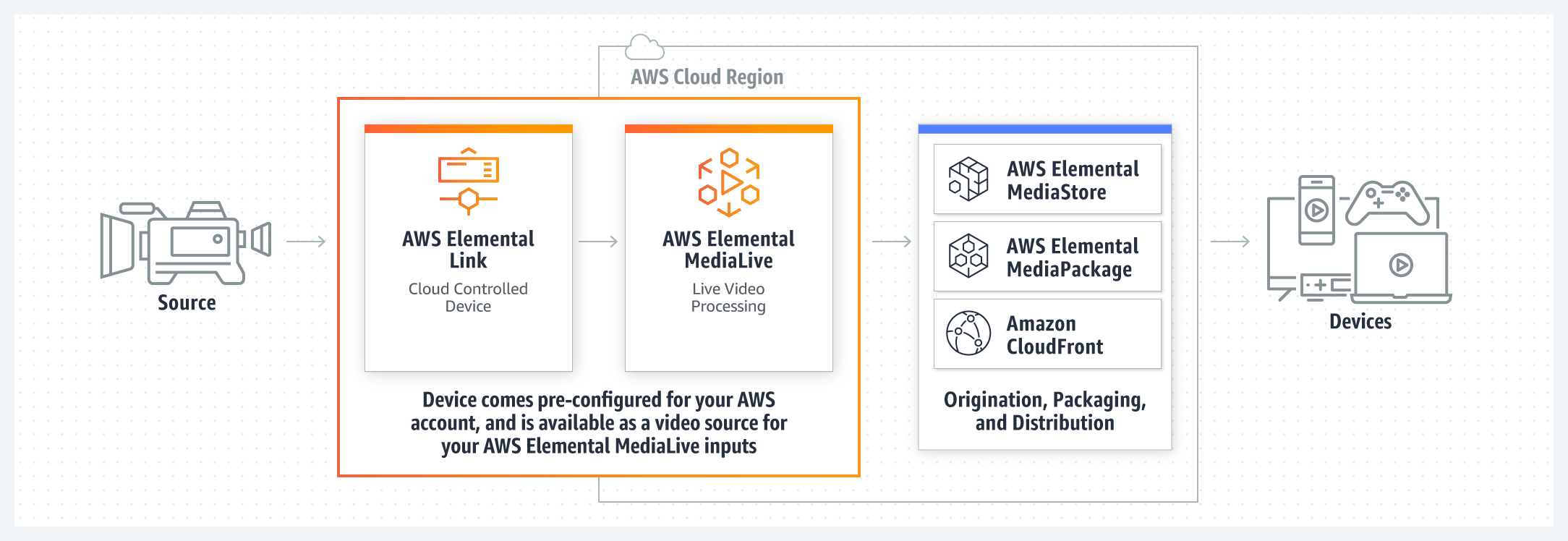
エンタープライズサーチは常に難題だった。目標は社内用のGoogle検索だ。キーワードを入力すると結果の上位に、常に完璧な結果を得たい。でもローカルな検索ではコンテンツが少ないので、満足な結果を得ることが難しかった。
Google(グーグル)にはWorld Wide Webという大きな宇宙があるが、エンタープライズが得る検索結果はもっと小さい。対象が少なければ理想的な結果を得やすいと思いがちだが、事実はその逆だ。データは、多ければ多いほど目的の情報を得やすい。
Amazon(アマゾン)は、エンタープライズサーチでもウェブのような完全な結果が得られるために、機械学習の導入による検索技術のアップデートを目指している。
米国時間5月11日に同社が一般公開したAmazon Kendraは、同社が昨年のAWS re:Inventで発表したクラウドベースのエンタープライズサーチプロダクトだ。自然言語処理の機能があるのでユーザーは単純に質問を入力でき、すると検索エンジンに接続された複数のリポジトリから正確な答えを見つける。
同社はリリース声明で「Amazon Kendraはエンタープライズサーチをゼロから作り直して、ユーザーは正しいキーワードだけでなく本当の質問を入力して、複数のデータサイロ全域を検索できる。そして内部では機械学習のモデルを利用してドキュメントの内容とそれらの間の関係を理解し、リンクのランダムなリストではなくユーザーが求める正確な答を提供する」と説明している。
AWSはこの検索エンジンを、IT、ヘルスケア、保険など主要な業種分野別にチューンアップしている。年内に対応を予定している業種分野は、エネルギー、工業、金融サービス、法務、メディア、エンターテインメント、旅行とホスピタリティ、人事、ニュース、通信、鉱業、食品と飲料、そして自動車だ。
ということは、この検索エンジンは各専門分野の特殊な用語も理解するので、導入したらその日からすぐに使える。また、会社で作るアプリケーションやウェブサイトにKendraを組み込んでもいい。現在では検索入力に必須ともいえる、入力補助機能(先行入力機能)もある。
エンタープライズサーチの歴史は長いが、今回AIと機械学習が加わったことによって、ついにその最終解が得られたと言えるかもしれない。
関連記事:AWS announces new enterprise search tool powered by machine learning(AWSがエンタープライズサーチに機械学習を導入、未訳)
[原文へ]
(翻訳:iwatani、a.k.a. hiwa)