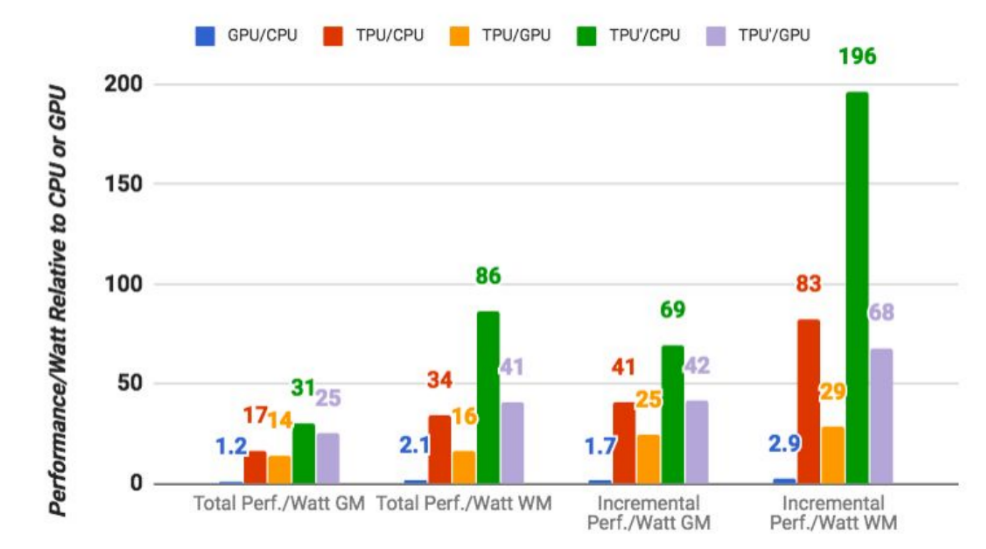
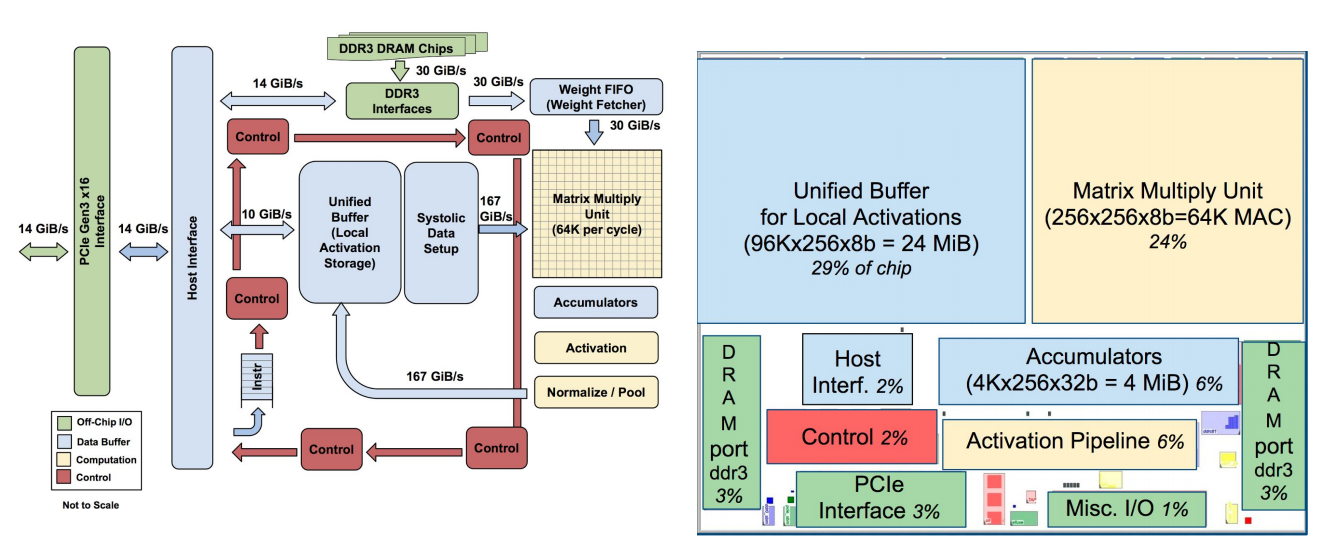
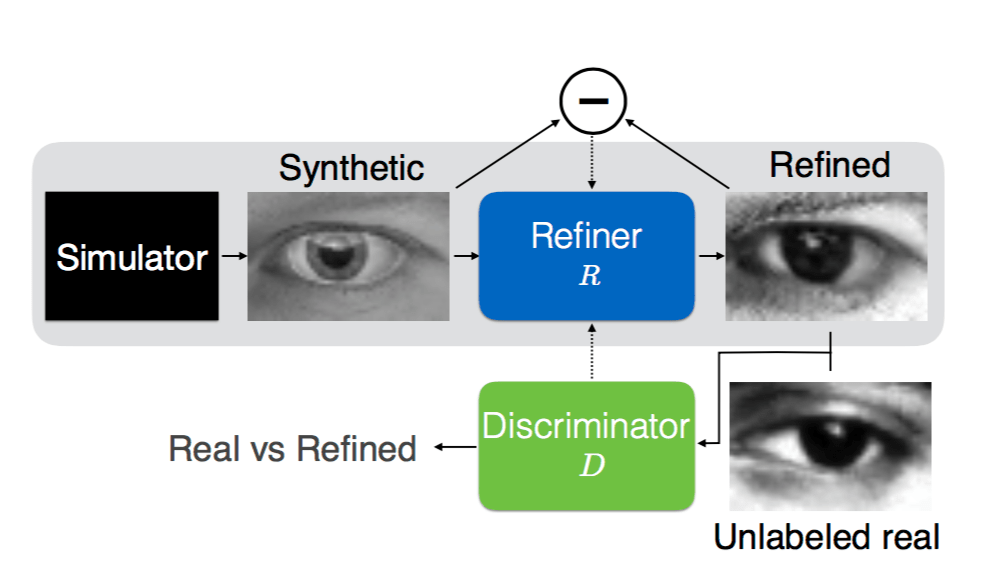
編集部注: Jarno M. Koponen氏はデザイナーであり人文科学社でもある。またメディア関連のスタートアップであるRandomの共同ファウンダーでもある。新しい「人間中心」のデジタルエクスペリエンスを模索している。
インターネット上のさまざまなことがアルゴリズムにより処理されるようになった。しかしどうやら「人間のため」という視点が欠落しつつあるようにも見える。実現したところで何のメリットもないような「ソリューション」が提示されることすらあるように思うのだ。
アルゴリズムにより表現される自己の危うさ
デジタルデバイスは、ポケットに入るものになり、そして身に付けるものとなって、さらには身体と一体化するようにまで進化してきている。わたしたちがオンラインで触れるものも、アルゴリズムにより決定されている面もある。近いうちには家庭や車の中に存在する現実のモノすらも変えることになりそうだ。
アルゴリズムが進化して「パーソナライズ」ということが言われるようになり、私たち自身がアルゴリズムに組み込まれることとなった。加えて、そもそも「パーソナライズ」という言葉も矛盾しているように思える。「パーソナライズ」がアルゴリズムにより行われるおかげで、私たちは「自分で」(パーソナルに)パーソナライズすることができないのだ。また、アルゴリズム的に認識されている私たちの姿を変更することも、自由に行うことはできない。これは今現在だけの問題というわけでなく、そもそも「パーソナライズ」ということが、そうした方向で実現されつつあるのだ。
「パーソナライズ」を行うアルゴリズムに、「パーソナライズ」される側から関わることはできない。「パーソナライズ」の仕組みは完全にオープンなものではなく、わかりやすいものでもない。何がどのように影響するのかがよくわからない。どのような現象を把握して、判断指標としてどの程度の重み付けをされるのかがまったく見えないのだ。自分自身の行動も、またアルゴリズムにより把握されている自分自身さえも、自分では理解できない「データの塊」として存在するようになる。
「パーソナライズ」のアルゴリズム自体が、個人の判断に影響し、ひいては行動も影響を及ぼす。「パーソナライズ」のためのアルゴリズムが存在するのは、他のだれかが、ある人物の思考ないし行動様式を理解するためだ。今、必要なものも、あるいは将来必要になるものも、アルゴリズムにより判断されて(誰か他のひとの立場から)提示されることとなる。
「パーソナライズ」のアルゴリズムは、完全に「ニュートラル」の立場にあるわけではない。もちろんだからといって、「誰かによる支配」を直ちに招くというものでもない。しかし「パーソナライズ」のアルゴリズムは(たいていの場合)誰か他の人のものの見方から生まれたものだ。アルゴリズムを生んだ人のものにくらべ、「パーソナライズ」して利用する人のものの見方が軽んじられることはあり得る。ここから自らの考えを反映しない「パーソナライズ」が生まれたり、別の人の考えを押し付けてくるような現象に戸惑ったりすることもあるわけだ。
「パーソナライズ」はごく一面的な判断に基づいて、あるいは特定の一面を必要以上に強調して為されることがある。アルゴリズムにより生み出される「アルゴリズム的自己」(algorithmic self)は細かく分断されているのだ。たとえばAmazonとOkCupidにおける自分は別の興味をもつ人物となっているだろう。これによりアルゴリズム側の行う、どのような人なのかの判断も異なるものとなる。このように、場合場合に応じて特定の一面だけをとりあげて解釈することで、「パーソナライズ」を行う世界においては、人間はかなり「一般化」され、かつ「単純化」される。把握できた人間像と不一致であり、また現在の人間像の解釈にやく立たずなデータは捨て去られる。「必要」だと判断して集めたデータがあまりに薄っぺらいものであったような場合は、アルゴリズム側で「似た人」と判断する人物のデータを流用して補正したりする。すなわち「アルゴリズム的自己」は、統一的な深みなど持たず、特定の条件に定まった反応をする、いわば成長前のフランケンシュタインのようなものとなっているのだ。
しかも、そうして生まれた「アルゴリズム的自己」が、自らのコントロールを離れてうろつき回るような状況となりつつある。デジタル環境において私たちの代理人となるような存在は消え去りつつあるのだ。すなわちデジタル界には「私たち」はいなくなり、それであるにも関わらずその「アルゴリズム的自己」に基づいてさまざまな「パーソナライズ」したサービスや情報が提供されることとなってしまっている。このような状況は変える必要があるのではなかろうか。
「アルゴリズム的自己」は、器官を寄せ集めただけの「デジタル・フランケンシュタイン」のようなもの
人工「天使」を待望する
いろいろと言ってはきたが、果たして「パーソナライズ」のアルゴリズムが明らかになれば問題は解決するのだろうか。あるいはアルゴリズムがわかったところで、さほど役に立たない話なのだろうか。
きっと有効性は低いのだと思う。私たちのために働いてくれる人工存在を生み出す方が良さそうだ。新しい概念であり決まった用語もないので「人工天使」(algorithmic angels)とでもしておこう。困ったときには助けてくれるし、いつも私たちを守ってくれ、トラブルに巻き込まれたりしないように配慮してくれる存在だ。
もちろん不器用そうなクリッパーのことではないし、微妙なことになると「わかりません」を連発するSiriでもない。IBMのWatsonでもなく、もちろん悪意を持っているHALでもあり得ない。私たちのことを学習して、ともかく私たちを守ろうとする存在を想定しているのだ。デジタル世界の「アルゴリズム的自己」のいたらない点を補正してくれる存在であることが期待される。具体的な働きをイメージしてみよう。
「人工天使」は理由なく自由を制限するような動きに対抗してくれる。「パーソナライズ」にあたっての行き過ぎた個人情報提供を見張り、場合によっては情報提供を無効化する。不必要に情報を集めまくるサービスに対抗する術を与えてくれる。
別の選択肢を示し、物事の他の見方を示してくれる。私たちは偏見をもったり、あるいは一面的な常識に囚われてしまうことがある。それがために、アルゴリズムの提示する「事実」をそのまま受け入れてしまいがちになる。そのようなときに「人工天使」が登場し、妄執を戒めてくれる。新しい世界を開き、独善的な振る舞いを改める機会を得ることができる。情報を取り入れる新しいやり方が示され、新鮮で新しい気づきをもたらしてくれるのだ。
無用な調査の対象から外してくれる。「人工天使」のおかげで、実名と匿名を適切に使い分けることができるようになる。利用するサービスに応じて、適切な設定を行ったプロファイル情報を利用してくれる。もちろん、これは「人工天使」に任せっきりにするのではなく、自分でさまざまな設定を使い分けることもできる。
自分に関するデータの扱いを、主体的に決定できるようになる。人工天使のおかげで、自分に関するデータの流れを主体的に制御できるようになるわけだ。自身の詳細な情報に誰がアクセスできるのかを決めたりすることができるようになる。必要なときには、従来のやり方ではばらばらにされて存在していた「アルゴリズム的自己」をまとめて活用することもできるようになる。もちろんデータの安全性は担保され、データの取り扱いはあくまでも所有者の主体的意志にひょり決せられることとなる。自分のどのような情報をネット上に流し、どういった情報を削除するかを自分の意志で決められるようになるわけだ。
人工天使はデバイスや環境間の違いも吸収してケアしてくれる。自身の情報は、望んだように提供/制限されるようになり、必要としないマーケティング行動のためのデータとはならない。そのために、たとえばウェアラブルなどから収集する情報についても適切に扱ってくれる。
こうした機能をもつ「天使」の存在のおかげで、リアル/バーチャルの違いなく、統合的かつ主体的に提供する自己情報に基づいて生活できるようになるというわけだ。
もちろんときにはこの「人工天使」機能をオフにしたくなることもあるだろう。天使なき世界がどのようなものであるのか、いつでも見てみることができる。
「人工天使」が無敵の人工知能である必要はない。別の表現を使うのなら、人間ほど賢い必要はない。デジタル社会の進化にともなって広がるネットワークワールドでのふるまいについてスマートであれば、それで事足りるのだ。多くの人が創造する「人工知能」とは、求められるものが異なることになるだろう。私たちは人間の立場で考え、評価し、選択する。「人工天使」は「機械」風に考え、そこで得られる知見をすべて人間のために使ってくれれば良いのだ。
「アルゴリズム的自己」の出現シーンが拡大し、そうした「自己」が活躍する分野の重要性は増してくることだろう。そのようなときには、今までよりもさらに自己情報の管理を丁寧に行うことが求められる。自律的存在であり続けるために、アルゴリズムで動作する守護天使が求められる時代となりつつあるのだ。そうした存在なしには、とてもさまざまな「アルゴリズム的自己」を活躍させることなどできなくなる。
「人工知能」の行き過ぎが危惧されることも増えてきた。「人工天使」を生み出すことにより、意外に簡単にバランスがとれる話なのかもしれない。
(訳注:本稿は昨年4月にTechCrunchサイトに掲載されました。訳出を見送っていましたが、最近の状況との絡みで面白そうだと判断して訳出いたしました)
[原文へ]
(翻訳:Maeda, H)










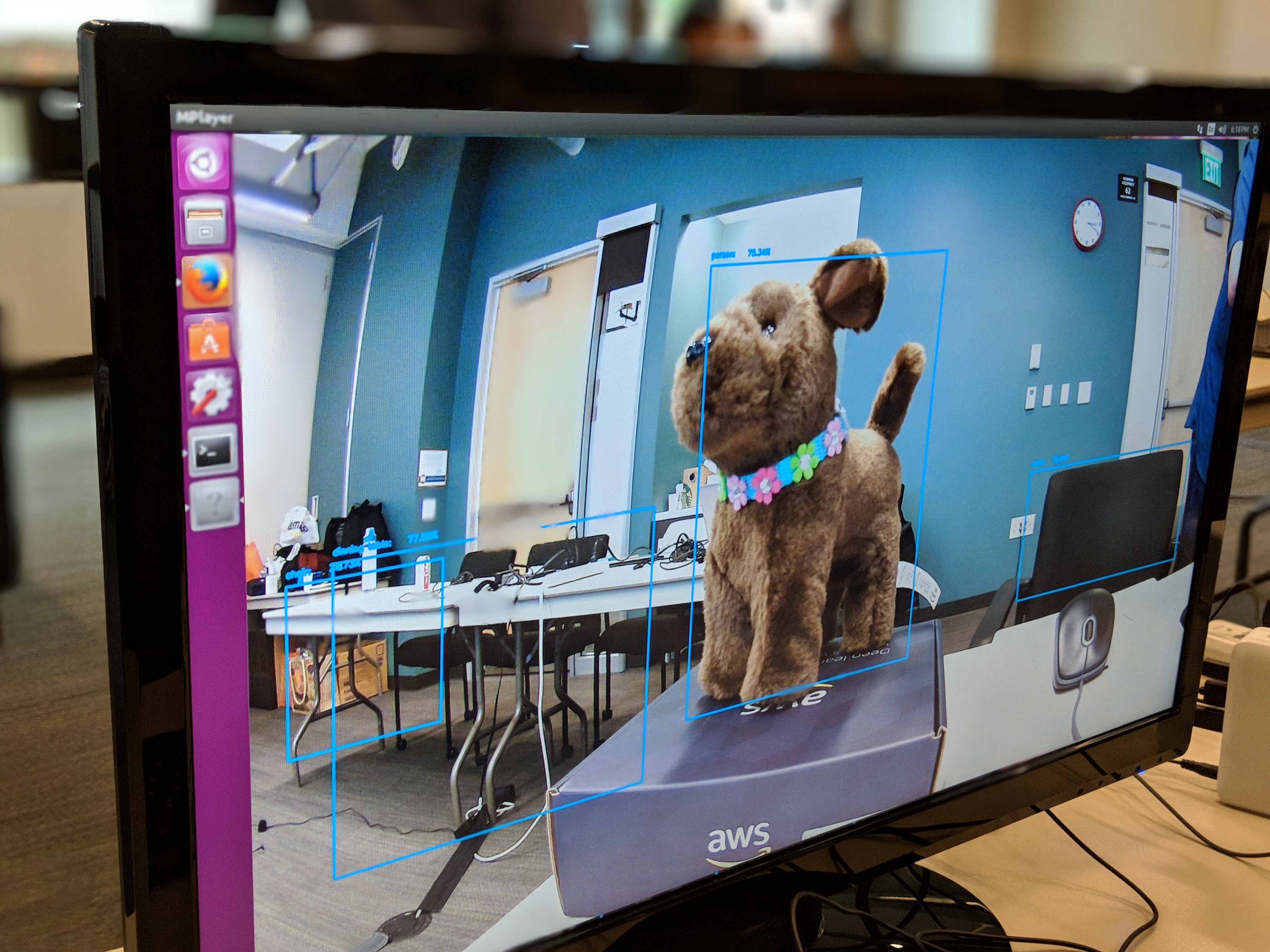
 それだけではない。開発チームはワークショップの中で、機械学習の経験がまったくないデベロッパーでも既存のテンプレートを簡単に拡張できることを強調していた。ひとつには、DeepLensプロジェクトが2つの部分からなっているためだろう。モデルおよびモデルの出力に基づいてモデルのインスタンスをアクションを実行するLambda機能だ。AWSは、ベースにあるインフラストラクチャーを管理することなくモデルを簡単に作るためのツールとしてSageMakerを提供している。
それだけではない。開発チームはワークショップの中で、機械学習の経験がまったくないデベロッパーでも既存のテンプレートを簡単に拡張できることを強調していた。ひとつには、DeepLensプロジェクトが2つの部分からなっているためだろう。モデルおよびモデルの出力に基づいてモデルのインスタンスをアクションを実行するLambda機能だ。AWSは、ベースにあるインフラストラクチャーを管理することなくモデルを簡単に作るためのツールとしてSageMakerを提供している。