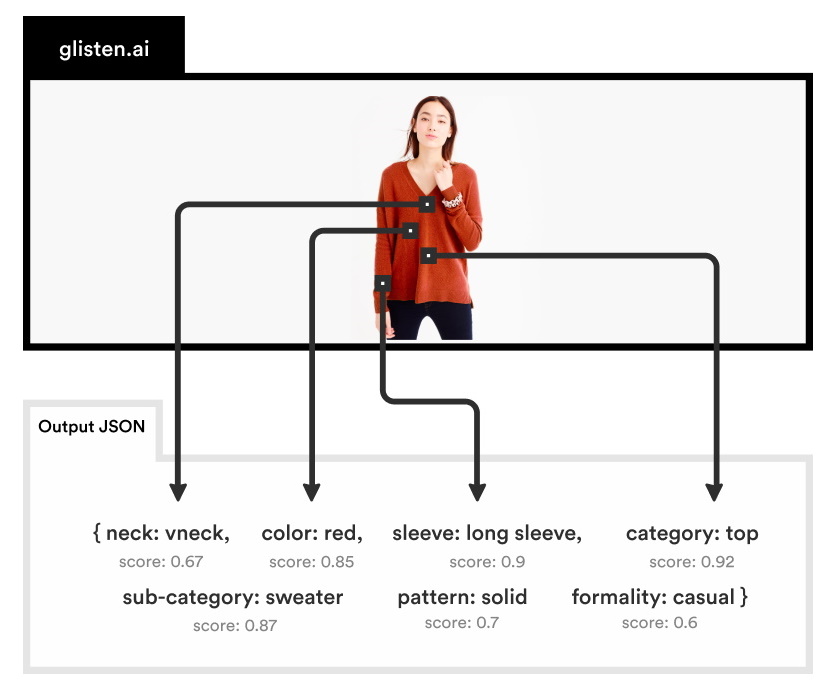
今日この時代になっても、新しい服を探すための最善の方法が、いくつかのチェックボックスをクリックして、果てしなく続く写真をスクロールしていくやり方だというのには驚かされる。どうして「グリーンの模様のスクープネックドレス」と検索して、結果をみることができないのだろうか? Glistenは、まさにこの課題を解決しようとしているスタートアップだ。その技術はコンピュータービジョンを使用してどんな写真からでも、写っている製品の最も重要な属性を理解して抜き出すことができる。
えっ、そんな機能もうあるのではと思ったかもしれない。ある意味それは正しいが、それほど役に立っているとは言えない。共同創業者のSarah Wooders(サラ・ウッダース)氏は、MITに通い自分のファッション検索プロジェクトに取り組んでいる最中に、この問題に遭遇した。
「オンラインショッピングを先延ばしにしていた私は、そのときVネックのクロップシャツを探していたのですが、まず見つかったのは2着だけでした。しかし、ずっとスクロールしていくと、さらに20着ほど見つかりました」と彼女は言う。「そのとき私は商品が極めて一貫性のない方法でタグ付けされていることに気づきました。消費者が見るデータが非常に煩雑な場合、おそらくその裏側はもっと悪い状況になっています」。
明らかになっているように、コンピュータビジョンシステムは、犬種の識別から表情の認識まで、あらゆる種類の画像の特徴を非常に効果的に識別するように訓練されてきている。ファッションやその他の比較的複雑な製品に関しても、似たようなことを行うことができる。画像を見て、信頼レベルを付加された属性のリストを生成することが可能なのだ。
そのため、特定の画像に対して、次のようなタグリストが生成できる。

想像できるとおり、これは実際とても便利だ。しかし、それはまだ多くの望ましい結果を置き去りにしたままなのだ。システムは「maroon」(栗色)や「sleeve」(袖)が、この画像に存在していることは認識しているが、それが実際に何を意味するのかは理解していない。システムにシャツの色をたずねてみても、人間が属性のリストを手作業で整理して、タグのうち2つは色の名前、これらはスタイルの名前、そしてこちらはスタイルのバリエーションのことといった具合に教えてやらない限り、システムはうまく答えることはできないだろう。
1つの画像だけならそうした作業を手で行うのは難しくないものの、衣料品の小売業者は膨大な製品を扱い、それぞれに複数の写真が関連し、毎週新しいものが入荷してくる状況なのだ。そうしたタグをコピー&ペーストで延々と整理し続けるインターンに、あなたはなりたいだろうか? そんなことはまっぴらだろうし、実際誰もやろうとはしないだろう。この点こそが、Glistenが解決しようとしている問題だ。コンピュータービジョンエンジンのコンテキスト認識を大幅に向上させて、その出力をはるかに便利にするのだ。
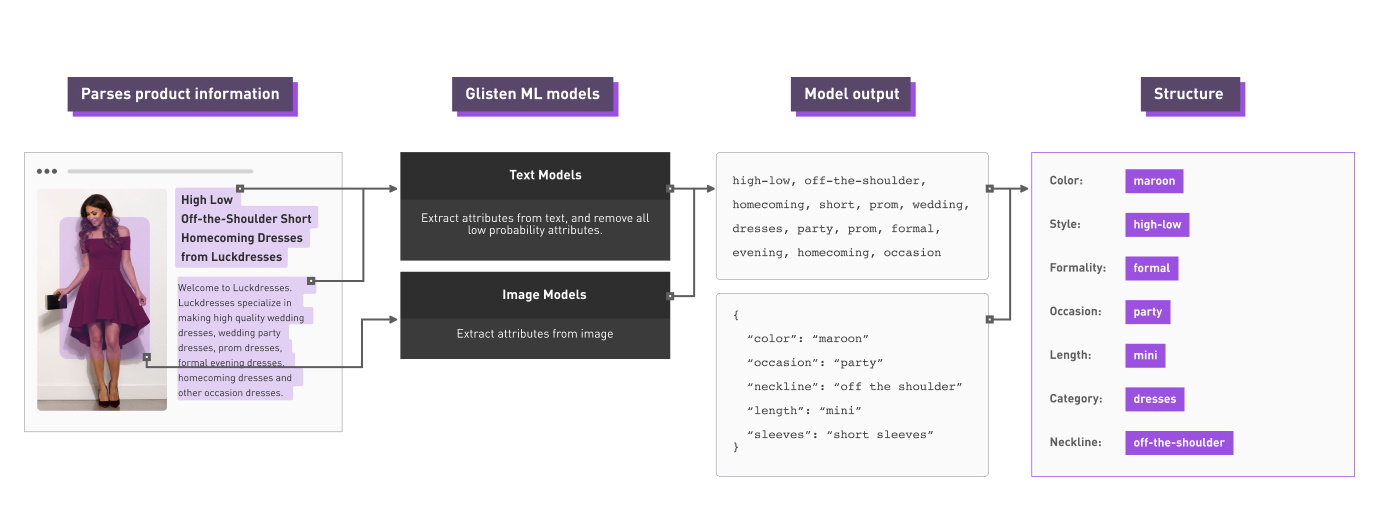
同じ画像をGlistenのシステムで処理すると、以下のような結果になるだろう。
 ずいぶん改善されていないだろうか。
ずいぶん改善されていないだろうか。
「私たちのAPIのレスポンスは実際に、ネックラインはこれ、色はこれ、パターンはこれという形式で返されるのです」とウッダース氏は説明する。
この種の構造化データは、データベースに容易に挿入することができ、高い信頼性とともに問い合わせを行うことができる。ユーザー(ウッダース氏が後ほど説明したように、必ずしも消費者である必要はない)は、「長袖」(long sleeves)と指定すれば、システムが実際に衣服の「袖」(sleeves)を見て、それが「長い」(long)ものを選ぶことを知っているので、組み合わせてマッチングを行うことができるのだ。
今回のシステムは、成長を続ける約1100万種類の製品イメージと、それに対応した説明文ライブラリでトレーニングされた。システムは自然言語処理を使用してそれらの説明文を解析し、何が何を参照しているかを把握する。こうすることで、学習モデルが「formal」を色のことだと思ったり、「cute」が利用されるシーンのことだと思ったりすることを防ぐための、重要なコンテキスト上の手がかりが与えられる。だが、データを単に投入してモデルにそれを判断させれば良いといえるほど、物事は単純ではないのではと考えるあなたは正しい。
以下に示したのは、説明のために理想化されたバージョンの概要だ。
「ファッション用語には多くのあいまいさがあって、それは間違いなく問題です」とウッダーズ氏は認めるものの、それは克服できない種類のものではない。「顧客に出力を提供するときには、各属性にスコアを付けています。そのため、それがクルーネックなのか、それともスクープネックなのかがあいまいな場合には、正しくアルゴリズムが機能している限り、双方にスコアとして大きな重みを付加します。確信が持てない場合には、信頼性スコアが低くなります。私たちのモデルは、現場の人たちがどのように製品にラベル付けしたか、その結果の集合で訓練されていますので、みんなの意見の平均値を得られることになります」。
当初のモデルは、ファッションと衣類全般を対象としていたが、適切なトレーニングデータを使用すれば、他の多くのカテゴリーに適用することもできる。同じアルゴリズムで、自動車や美容製品などの特徴を見つけることができるのだ。例えばシャンプーボトルを探す場合な、袖(sleeves)の代わりに適用シーン、容量、髪質、そしてパラベン(防腐剤であるパラオキシ安息香酸エステル)含有の有無などを指定できる。

普通の買い物客たちは放っておいてもGlistenの技術のメリットを理解してくれるだろうが、同社は自分たちの顧客が、販売の現場の手前にいることに気がづいた。
「時間が経つにつれて私たちが気づいたのは、私たちにとって理想的な顧客とは、乱雑で信頼性の低い製品データを持っていることに、苦痛を感じているような人たちだということでした」とウッダース氏は説明する。「それは主に、小売業者たちと協力しているハイテク企業なのです。実際、私たちの最初の顧客は価格の最適化を行う会社で、また別の顧客はデジタルマーケティング会社でした。これらは、アプリケーションとして当初私たちが考えていたものよりも、かなり外れた場所にある応用なのです」。
ちょっと考えてみれば、その理由が理解できるだろう。製品についてよく知れば知るほど、消費者の行動や傾向などと関連づける必要があるデータが増えていく。単に夏のドレスの売上が戻ってきていることを知っているよりも、七分袖の青と緑の花柄のデザインの売上が戻ってきていることを知っている方が良い。

Glistenの共同創業者サラ・ウッダース氏(左)とAlice Deng(アリス・デング)氏
競争相手は主に、企業内のタギングチーム(私たちが誰もしたくないような手作業のレビューを行う)や、Glistenが生成するような構造化データの生成を行わない汎用コンピュータービジョンアルゴリズムである。
来週行われるY Combinator のデモデー前にも関わらず、同社はすでに月々5桁(数万ドル、数百万円)の定常収益を得ているが、現時点では彼らの販売プロセスは、彼らが役に立つと思った人々への個別のコンタクトに限定されている。「ここ数週間で、非常に多くの売り上げがありました」とウッダーズ氏は語る。
ほどなくGlistenは多くのオンライン製品検索エンジンに組み込まれることになるだろうが、理想的には利用者がそれに直接気がつくことはないだろう。ただ単に探しものがはるかに見つかりやすくなったように思えるようになるだけだ。
関連記事:いまさら聞けないコンピュータービジョン入門
[原文へ]
(翻訳:sako)