{kind=link}
Amazon Web Services(AWS)をモニタするサービスStackdriverに、ユーザが処理方針(ポリシー)を設定できる自動化ツールがいくつか加わる。それらは、問題が起きたときアラートするだけでなく、ユーザがあらかじめ指定した対応処理を行う。ユーザがサーバをいちいち手作業で停止/始動しなくてもよい。今日(米国時間11/11)Stackdriverはさらに、WebサイトやサードパーティのAPIなど、エンドポイントをモニタする機能をローンチした。
これらの新しいサービスはStackdriver Proの現ユーザと年内に登録したユーザに提供される。その後は、これらの機能は同社が近く発表する”Elite”プランの一部になる。今年の12月31日までにProのユーザになった者は、この新しいプランに自動的にアップグレードされる。
自動化機能
{kind=link}
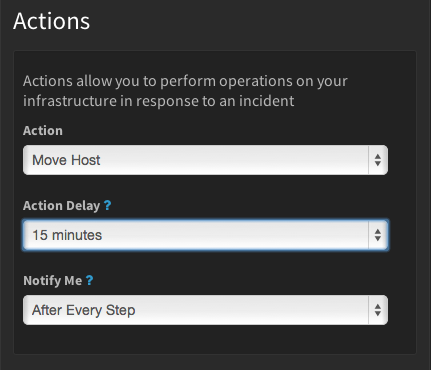
どのモニタサービスにも、異状をアラートしてくれる機能はある。アプリケーションがメモリ不足になったとか、おかしなプロセスがサーバのパフォーマンスの足をひっぱっている、など。関係データベースのインスタンスがメモリ不足になっているので、容量を増やしてやる必要があるかもしれない。これらはいずれも重要な通知だが、担当が午前2時に起こされて対応しなければならないのは、たいへんだ。そこでStackdriverの自動化機能は、ユーザが対応方法をあらかじめ設定しておき、システムのステータスが一定の閾値を超えたらそれらを自動的に実行する。AWSの必要なAPIを呼び出すことも、Stackdriverがユーザに代わってやる。
すなわちユーザが手作業でインスタンスの始動や停止を行うのではなく、パフォーマンスが劣化したらユーザがあらかじめ設定した対策プロセスが自動的に動きだす。また、そのプロセスが終了したら通知を受け取ることもできる(メール、SMS、PagerDutyなどで)。また、放っておけば直る/元に戻るを期待して、対応プロセスの始動時間を遅らせる、という設定もできる。
今このStackdriver Automation機能にできることは、インスタンスのリブート、Elastic Block Store-backedのインスタンスを移動する〔参考〕、RDSのインスタンスの容量を増やす、などだ。同社の協同ファウンダIzzy Azeriによると、そのほかのプロセスも今対応を準備中だ。
エンドポイントモニタリング
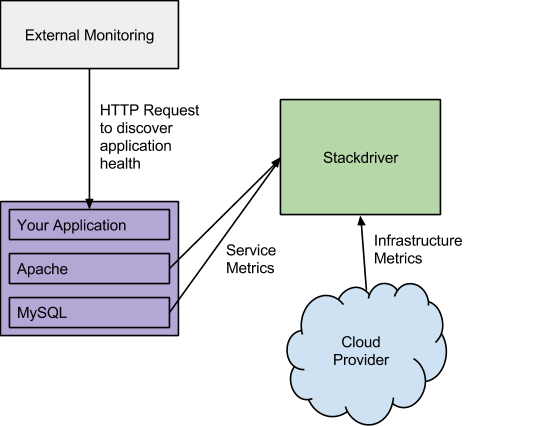{kind=link}
Stackdriverのアラート機能はすべて、新たにできたエンドポイントモニタリングシステムと連係している。同社によればこのシステムは、“アプリケーションモニタリングの最後に残った一切れであるエンドポイントのチェックを、世界中のユーザ環境や場所に対して行う”、というものだ。これによりたとえば、アプリケーションが依存している何らかのAPIの正常動作をチェックすることができる。Stackdriverのモニタリングシステムの詳細はここにある。
[原文へ]
(翻訳:iwatani(a.k.a. hiwa))