AmazonやMicrosoft、Googleなどが提供している非常に大きなクラウドプラットホームは、大学や企業の科学者たちがシミュレーションや分析のために必要とするハイパフォーマンスコンピューティング(high-performance computing, HPC)のプロジェクトを十分に動かせる。なにしろ彼らに課せられる大きなワークロードも、何百何千というマシンで並列処理されるから楽勝だ。しかし、往々にしてチャレンジは、それだけ大量のクラスターをどうやって作り、それらを動かすワークロードをどうやって管理するかだ。

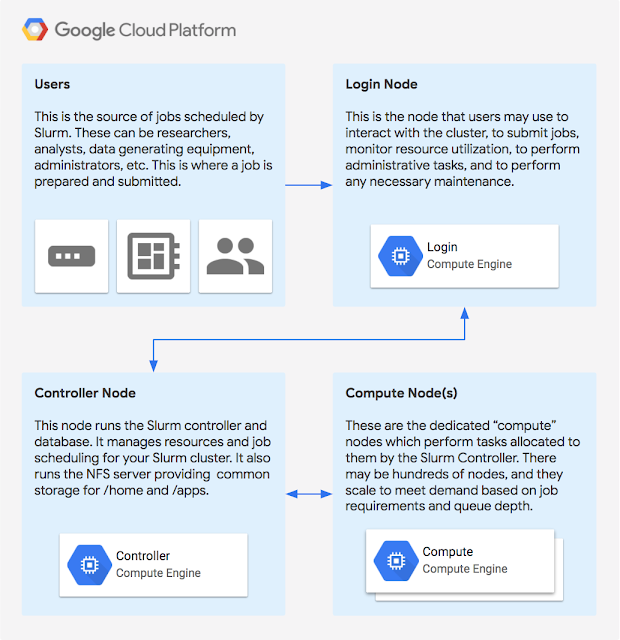
HPCのコミュニティがこのチャレンジを比較的楽にこなせるために、Googleは今日(米国時間3/23)、同社のクラウドプラットホームでオープンソースのHPCワークロードマネージャーSlurmをサポートする、と発表した(このSlurmではない)。それは、上位500のリストに載ってるようなスーパーコンピューターのユーザーの多くが使ってるのと同じようなソフトウェアだ。ちなみに現在最大最速のクラスターは、1000万あまりのコンピューターコアから成るSunway TaihuLightだ。
GoogleはSlurmを作っているSchedMDとチームを組んで、SlurmをGoogleのCompute Engineで簡単に動かせるようにした。この統合努力によりデベロッパーは、自分たちの仕様に基づいて動くCompute Engineで、スケーリングを自動的に行うSlurmを容易にローンチできる。ここでの興味深い機能のひとつは、もうちょっと計算力が欲しいようなときに、ユーザーがオンプレミスのクラスターのジョブをクラウドと連合できることだ。
GoogleのCompute Engineは現在、最大96コア、メモリ624GBまでのマシンを提供しているので、GCP(Google Cloud Platform)の上で必要に応じて大規模な計算力クラスターを構築することも、十分に可能だ。
なお、Microsoft Azureもその上にSlurmをデプロイするためのテンプレートを提供しており、またこのツールはかなり前からAWSをサポートしている。