多くのフロントエンド フレームワークは、コンテンツの表示に JavaScript を使用しています。そのため、Google がコンテンツをインデックスに登録したり、インデックスに登録されたコンテンツの更新に時間がかかる場合があります。
昨年の Google I/O では、この問題の回避策としてダイナミック レンダリングが議論されました。ダイナミック レンダリングの実装方法はいくつかあります。このブログでは、Rendertron を使用したダイナミック レンダリングの実装例を紹介します。Rendertron は headless Chromium をベースとしたオープンソース ソリューションです。
ダイナミック レンダリングを検討すべきサイト
あなたのサイトにアクセスする検索エンジンやソーシャル メディア ボットが、すべて JavaScript を実行できるわけではありません。Googlebot が JavaScript を実行するのには時間がかかり、こちらに示すようにいくつかの制限が存在します。
ダイナミック レンダリングは、変更頻度が高く、表示に JavaScript を必要とするコンテンツに対して有用です。
また、ハイブリッド レンダリング(Angular Universal など)を検討することで、あなたのサイトのユーザー エクスペリエンス(特に first meaningful paint までの時間)を向上できる可能性があります。
ダイナミック レンダリングの仕組み
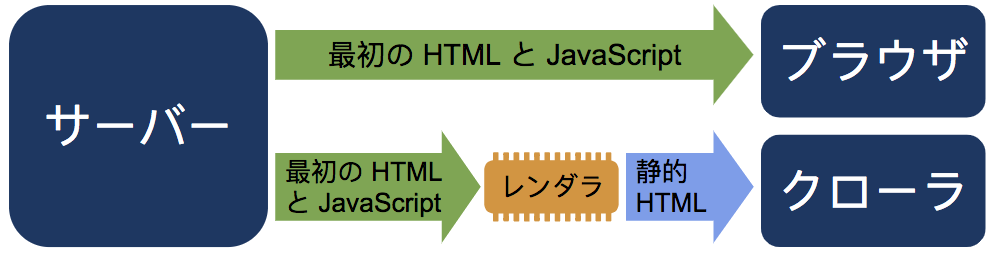
ダイナミック レンダリングとは、特定のユーザー エージェントに応じて、クライアント側でレンダリングされるコンテンツとプリレンダリングしたコンテンツを切り替えることを指します。
JavaScript を実行して静的 HTML を生成するにはレンダラが必要になります。Rendertron はオープンソース プロジェクトであり、headless Chromium を使用してレンダリングを行います。シングルページ アプリでは、頻繁にバックグラウンドでデータを読み込んだり、コンテンツをレンダリングするための作業で遅延が発生したりすることがあります。Rendertron には、ウェブサイトでレンダリングが完了したタイミングを判定するメカニズムがあります。Rendertron は、すべてのネットワーク リクエストが完了し、未処理の作業がなくなるまで待機します。
このブログ投稿で扱う内容
- サンプルのウェブアプリを確認する
- 小規模の express.js サーバーを設定して、ウェブアプリを配信する
- ダイナミック レンダリング用のミドルウェアとして Rendertron をインストールして構成する
サンプルのウェブアプリ
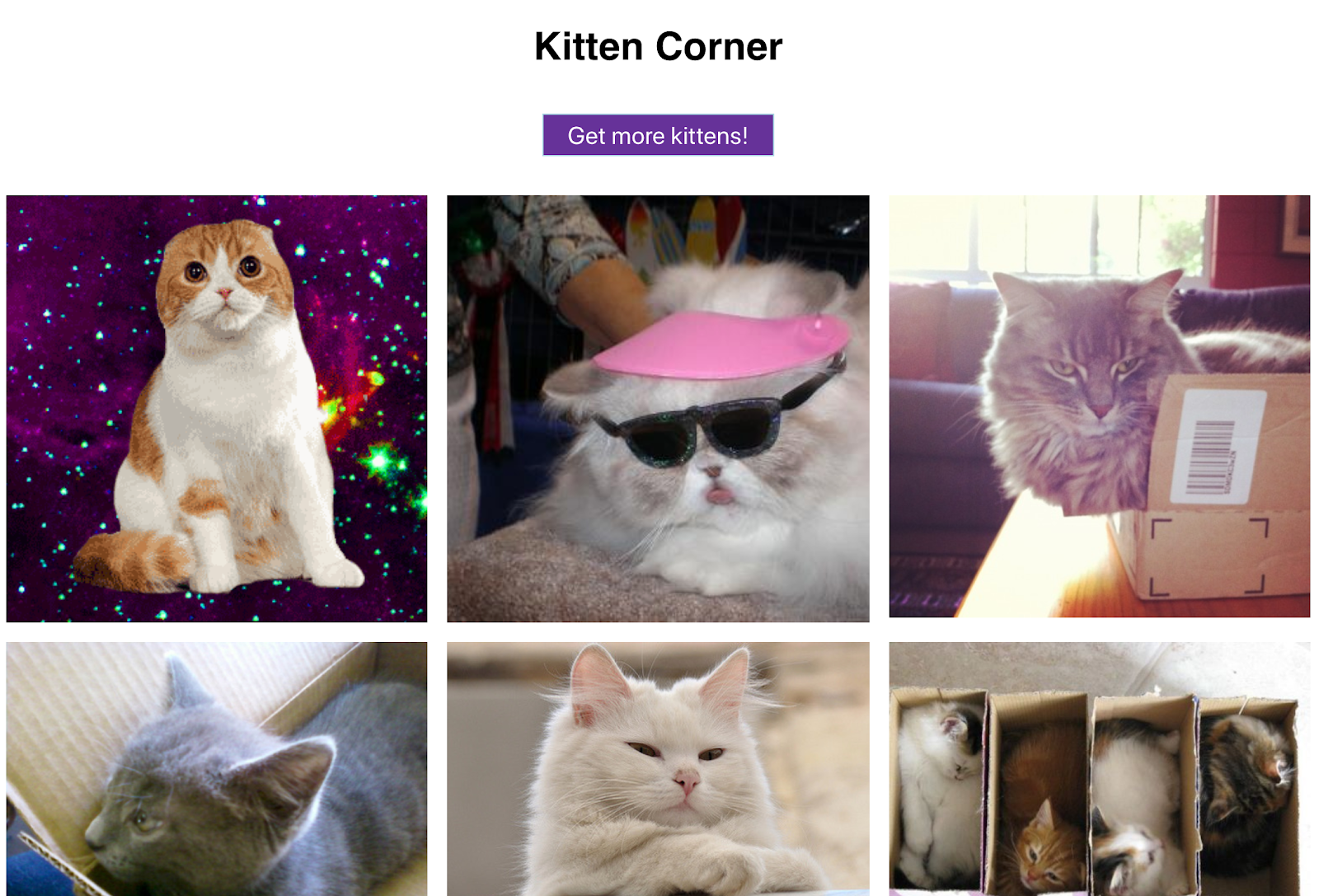
「kitten corner」ウェブアプリは JavaScript を使用して、さまざまな猫の画像を API から読み込み、グリッド形式で表示します。
グリッド形式で猫の画像が表示され、ボタンでさらに画像を表示できます。可愛いと思いませんか?
以下がこのウェブアプリの JavaScript です。
const apiUrl = 'https://api.thecatapi.com/v1/images/search?limit=50';
const tpl = document.querySelector('template').content;
const container = document.querySelector('ul');
function init () {
fetch(apiUrl)
.then(response => response.json())
.then(cats => {
container.innerHTML = '';
cats
.map(cat => {
const li = document.importNode(tpl, true);
li.querySelector('img').src = cat.url;
return li;
}).forEach(li => container.appendChild(li));
})
}
init();
document.querySelector('button').addEventListener('click', init); このウェブアプリでは、Googlebot でまだサポートされていない最新の JavaScript(ES6)が使用されています。Googlebot がコンテンツを認識できるかは、モバイル フレンドリー テストを使用することで確認できます。
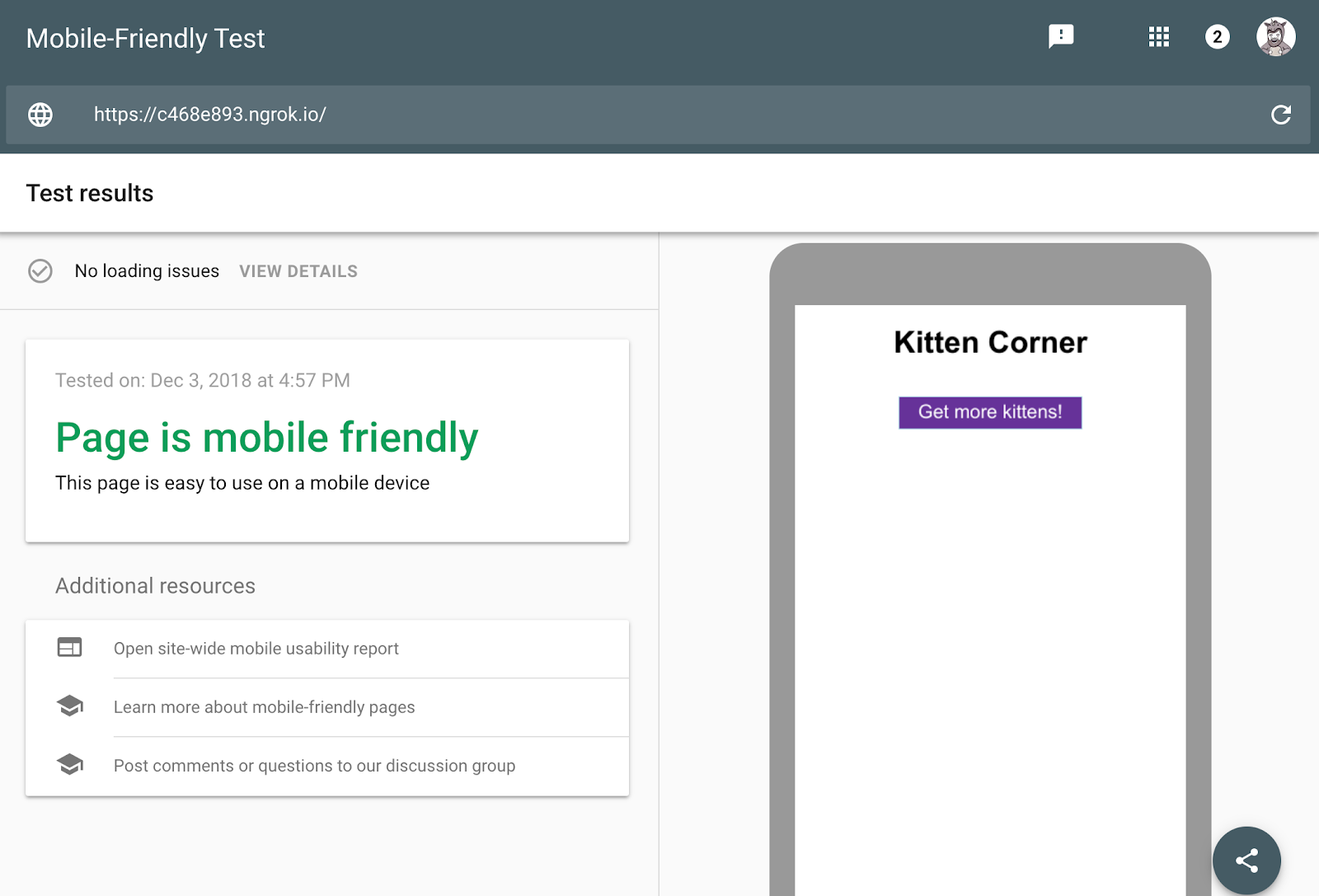
モバイル フレンドリー テストより、このページがモバイル フレンドリーであることがわかりますが、スクリーンショットには猫が一切見当たりません。見出しとボタンは表示されていますが、猫の画像がまったく表示されていません。
この問題は簡単に修正できます。こうした修正は、ダイナミック レンダリングを設定する方法を学習するための良い練習となるでしょう。ダイナミック レンダリングにより、ウェブアプリのコードを変更せずに Googlebot に猫の画像を認識させることができます。
サーバーの設定
ウェブアプリを配信するために、node.js ライブラリの express を使用してウェブサーバーを構築します。
サーバーのコードは以下のようになります(プロジェクトの完全なソースコードはこちらをご覧ください)。
const express = require('express');
const app = express();
const DIST_FOLDER = process.cwd() + '/docs';
const PORT = process.env.PORT || 8080;
// Serve static assets (images, css, etc.)
app.get('*.*', express.static(DIST_FOLDER));
// Point all other URLs to index.html for our single page app
app.get('*', (req, res) => {
res.sendFile(DIST_FOLDER + '/index.html');
});
// Start Express Server
app.listen(PORT, () => {
console.log(`Node Express server listening on http://localhost:${PORT} from ${DIST_FOLDER}`);
});
こちらで実際の例を試すことができます。最新のブラウザを使用しているのであれば、複数の猫の画像が表示されるはずです。パソコンからプロジェクトを実行するには、node.js で次のコマンドを実行する必要があります。
npm install express rendertron-middleware
node server.js
次に、使用しているブラウザで http://localhost:8080 を指定します。ここからはダイナミック レンダリングを設定します。
Rendertron インスタンスのデプロイ
Rendertron は、URL を取得して、headless Chromium によってその URL の静的 HTML を返すサーバーを実行します。Rendertron プロジェクトの推奨事項に沿って、Google Cloud Platform を使用します。
新しい Google Cloud Platform プロジェクトを作成するためのフォーム
新しい Google Cloud Platform プロジェクトを作成するためのフォームに関しては、無料枠でプロジェクトを作成できる点に注意してください。また、この設定を本番環境で使用すると、Google Cloud Platform の料金体系に応じた課金が発生する点にも注意してください。
- Google Cloud Console で新しいプロジェクトを作成します。入力フィールドにある「プロジェクト ID」をメモします。
- Google Cloud SDK をドキュメントに説明されているとおりにインストールしてログインします。
- 以下のコマンドで、GitHub にある Rendertron リポジトリのクローンを作成します。
git clone https://github.com/GoogleChrome/rendertron.git
cd rendertron - 次のコマンドを実行して依存関係をインストールし、パソコンに Rendertron を構築します。
npm install && npm run build - 次の内容の config.json という新しいファイルを rendertron ディレクトリに作成して、Rendertron キャッシュを有効化します。
{ "datastoreCache": true } - rendertron ディレクトリから次のコマンドを実行します。「YOUR_PROJECT_ID」は、手順 1 でメモしたプロジェクト ID に置き換えます。
gcloud app deploy app.yaml --project EURE_PROJEKT_ID - 任意のリージョンを選択して、デプロイを確定します。デプロイが完了するまで待ちます。
- YOUR_PROJECT_ID.appspot.com(「YOUR_PROJECT_ID」は、手順 1 でメモしたプロジェクト ID に置き換えます)をブラウザに入力します。入力フィールドといくつかのボタンがある Rendertron のインターフェースが表示されるはずです。
Google Cloud Platform に導入した後の Rendertron の UI
Rendertron のウェブ インターフェースが表示されたら、Rendertron インスタンスが正常にデプロイされたことを意味します。次の手順で必要になるため、プロジェクトの URL(YOUR_PROJECT_ID.appspot.com)をメモします。
サーバーへの Rendertron の追加
ウェブサーバーは express.js を使用しており、Rendertron には express.js ミドルウェアがあります。server.js ファイルのディレクトリで、次のコマンドを実行します。
npm install --save rendertron-middleware
このコマンドにより、npm から rendertron-middleware がインストールされます。これで、rendertron-middleware をサーバーに追加できます。
const express = require('express');
const app = express();
const rendertron = require('rendertron-middleware');
bot リストの構成
Rendertron は、ユーザー エージェントの HTTP ヘッダーを使用して、リクエストが bot からのものなのか、ユーザーのブラウザからのものなのかを判断します。Rendertron には、比較に使用できる、適切に整理された bot ユーザー エージェントのリストがあります。Googlebot は JavaScript を実行できるため、デフォルトではこのリストに Googlebot は含まれません。Rendertron に Googlebot リクエストもレンダリングさせるには、ユーザー エージェントのリストに Googlebot を追加します。
const BOTS = rendertron.botUserAgents.concat('googlebot');
const BOT_UA_PATTERN = new RegExp(BOTS.join('|'), 'i');
Rendertron は後でこの正規表現とユーザー エージェントのヘッダーを比較します。
ミドルウェアの追加
bot リクエストを Rendertron インスタンスに送信するには、express.js サーバーにミドルウェアを追加する必要があります。ミドルウェアはリクエストしているユーザー エージェントを確認し、既知のボットからのリクエストを Rendertron インスタンスに転送します。次のコードを server.js に追加します。必ず「YOUR_PROJECT_ID」を Google Cloud Platform プロジェクト ID に置き換えてください。
app.use(rendertron.makeMiddleware({
proxyUrl: 'https://YOUR_PROJECT_ID.appspot.com/render',
userAgentPattern: BOT_UA_PATTERN
}));
サンプル ウェブサイトをリクエストする bot は Rendertron から静的 HTML を受け取るので、コンテンツを表示するために JavaScript を実行する必要がありません。
設定のテスト
Rendertron の設定に成功したかどうかをテストするには、もう一度モバイル フレンドリー テストを実行します。
最初のテストとは違い、猫の画像が表示されます。HTML タブには、JavaScript コードが生成したすべての HTML が表示され、コンテンツを表示するための JavaScript が Rendertron によって不要になったことがわかります。
まとめ
ウェブアプリに変更を加えずに、ダイナミック レンダリングを設定しました。このような設定により、ウェブアプリの静的バージョンの HTML をクローラに提供できます。
Posted by Martin Splitt、Open Web Unicorn
Original version: Google Webmaster-Zentrale Blog: Dynamisches Rendering mit Rendertron