新型コロナウイルス(COVID-19)の感染拡大に対する懸念が高まる中、Y Combinator(Yコンビネーター)はこれまで慣れ親しんできた2日間にわたる米国サンフランシスコでの会合からイベントの開催方式を切り替え 、デモデーのウェブサイトを通じて、招待された投資家とメディアにクラス全体を同時公開する方法で開催することを決定した。
さらに驚きなのが、投資家の動きが加速してきた事実を受け 、YCがデモデー開催日を1週間前倒しにしたことだ。このため、デモデーのウェブサイトに録画したプレゼンを掲載するというプランは変更せざるをえなくなり、各事業は代わりにスライドに事業概要、今後の見通し、チームの経歴などの説明をまとめてプレゼンを行った。急速に進化する投資環境と相まって、この新たなスタイルがこのクラスにどのように影響するかは今のところはわからない。
プレゼンやウェブサイトのほか、場合によっては以前の記事から収集した情報をもとに、我々が集めたそれぞれのクラスの各事業のメモをまとめてみた。
読みやすさを優先し、全事業をすべて羅列するのではなくカテゴリー別にまとめている。これらの企業は、ハードウェア、ロボット工学、AI、機械学習、開発者用のツールを手掛けている企業である。そのほかのカテゴリー(バイオテック、コンシューマー、フィンテックなど)に関してはこちら から読むことができる。
AIおよび機械学習
Datasaur
1build
Zumo Labs
VIDEO
Teleo
Turing Labs Inc. こちら 。
Segmed
Ardis AI
Agnoris
Froglabs
PillarPlus
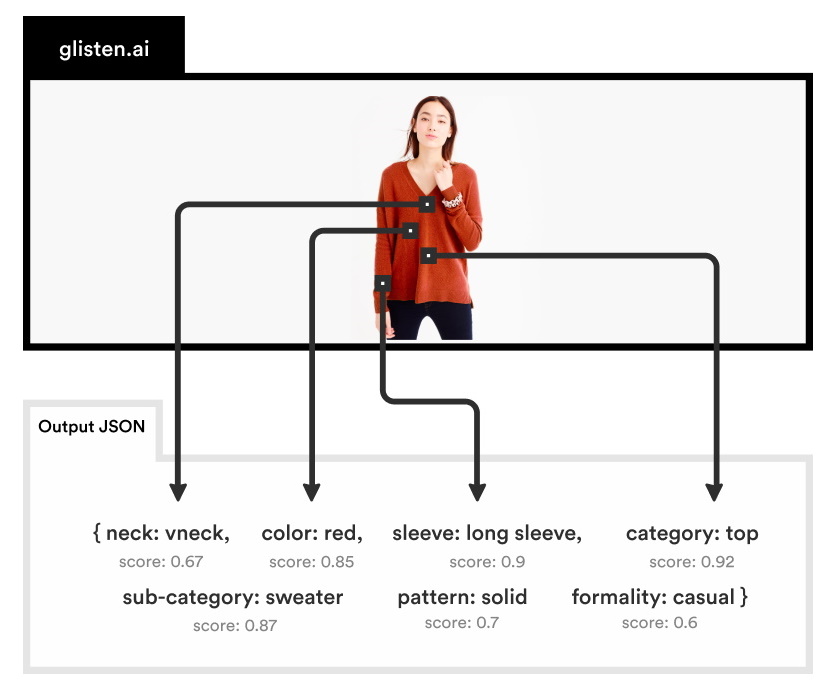
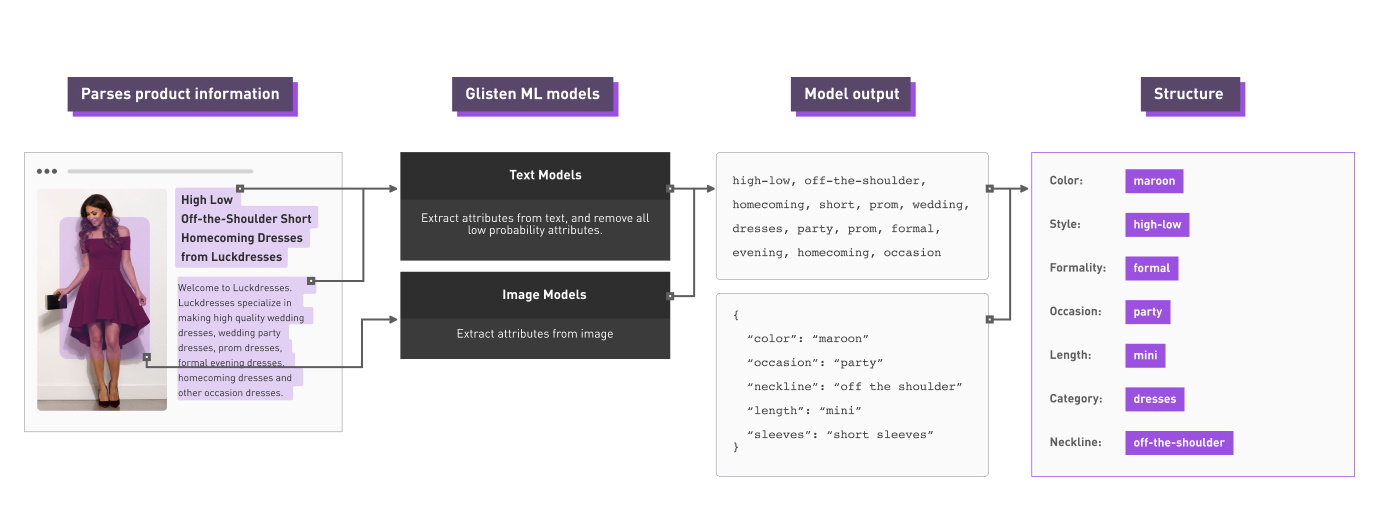
Glisten こちら 。
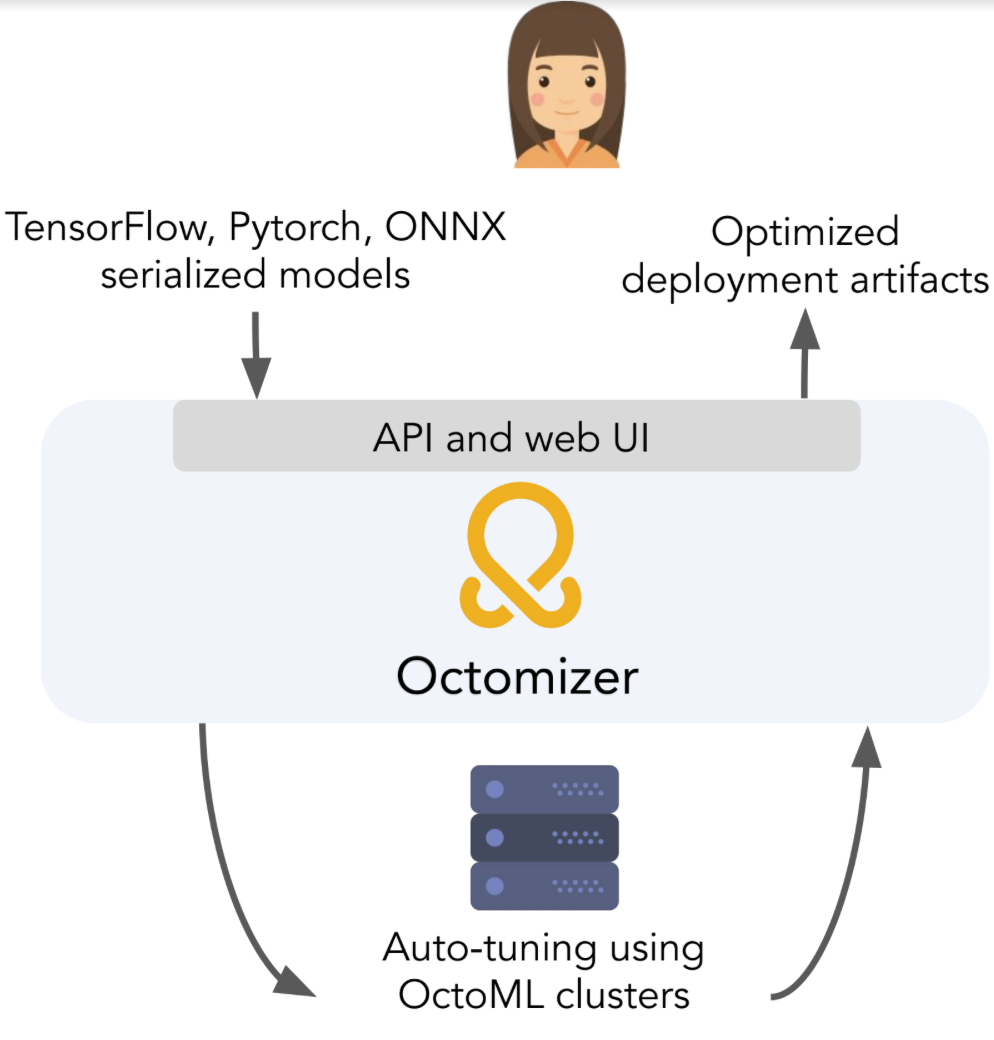
nextmv
Visual One こちら 。
PostEra
ハードウェアおよびロボット工学
Cyberdontics
Avion
SOMATIC こちら 。
RoboTire こちら 。
Morphle
Daedalus
Exosonic
Nimbus
UrbanKisaan
Talyn Air
開発者向けツール
BuildBuddy
Dataline
Cortex
apitracker
Freshpaint
Datree こちら 。
fly.io
Sweeps
Orbiter
Release
Signadot
Raycast
Cotter
ditto
Scout
ToDesktop
DeepSource
Flowbot
PostHog