Dropboxが今日(米国時間11/14)、Autodeskのユーザーが大きな設計ファイルに、より容易にアクセスし共有できるための、二つのプロダクトを発表した。ひとつはDropboxに保存しているAutodeskのファイルをAutodeskのソフトウェアからオープンしセーブするためのデスクトップアプリケーション、もうひとつはAutodeskがなくても設計ファイルを見ることができるアプリケーションだ。
Dropboxでデベロッパーユーザーのお世話を担当しているRoss Piperによると。今DropboxにはAutodeskのファイルが15億あり、毎月8500万ずつ増えている。数も驚異的だが、設計ファイルはファイルサイズが大きい。大きくて複雑なファイルが毎日たくさん生成されるからこそ、クラウドストレージが何よりもありがたい。だからAutodeskの統合はDropboxにとって、とっくにやっているべき課題だった。
両社は互いにパートナーになることによって、これらのファイルをもっと扱いやすくしよう、と決心した。
Dropboxのデスクトップアプリケーションは今日から可利用になり、ユーザーはAutoCadアプリケーションから直接に、クラウド上(==Dropbox上)の.dwg設計ファイルをオープン/セーブできる。ユーザーはAutoCadの中で直接これらのファイルを開ける。その感覚は通常のファイルと同じで、Dropboxから取り出していることを意識しない。作業を終えたファイルの保存も、自動的にDropbox上へ行われる。
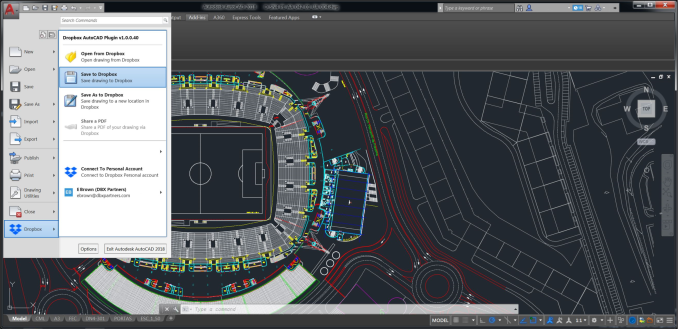
DropboxがAutoDeskを直接統合。写真提供: Dropbox
もうすぐ提供される単独のビューワーアプリケーションは、設計ファイルをAutodeskのないユーザーとも共有できる。しかも、それらの人びとがファイルにコメントできるので、役員や顧客、協力企業などが変更を要望するなど、設計に容易に‘参加共有’できる。
たとえば、設計者が描いた図面を見て、その中のひとつの部屋や領域をセレクトすれば、その部分に関するコメントを見たり書いたりできる。
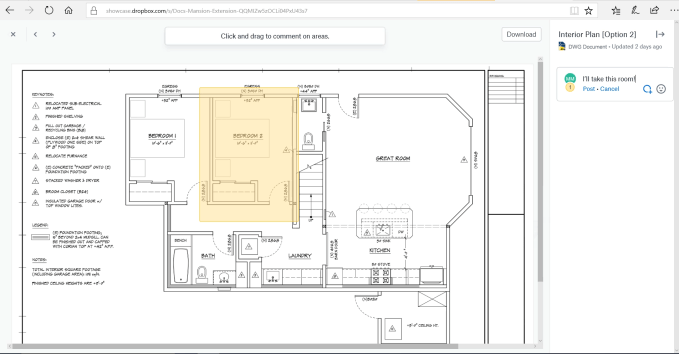
写真提供: Dropbox
Dropboxが提供するこれらのツールは、AutodeskのAutoCad App Storeからダウンロードできる。そして、インストールすればすぐに使える。
今回の発表は、Autodeskのような有力なサードパーティパートナーとDropboxの深い統合が、今後もいろいろありえることを示している。各種ビジネスアプリケーションのユーザーは、いちいちDropboxからファイルをダウンロード/アップロードしなくても、仕事用のメインのソフトウェアを使いながら、その中で、必要なファイルのオープン/セーブがごく自然に、できるようになるのだ。
実はBoxも、Autodeskとのこのようなパートナーシップを、2年前から結んでいる。