Slackは有料の企業ユーザーが増えているので、彼らの仕事に役に立つような他サービスの統合が、容易にできるための方法を模索している。
今日(米国時間7/17)同社は、Robots and PencilsのMissionsを買収したことを発表した。これによりSlackのユーザーは、コードを書かなくても、毎日の仕事の単純なルーチンを自動化できるようになる。買収の条件は、公表されていない。
有料ユーザーは、Slackにいろんなものを統合することが好きだ。Slackのアプリケーションディレクトリを見ると、今すでに1500あまりのアプリ/アプリケーションをSlackの中から使える。同社によると、企業ユーザーの94%がほかのアプリとそれらの統合を利用し、64%は独自のアプリを作っている。しかし、非技術系の部署にとって、統合は簡単な仕事ではない。そこでMissionsは、ビジュアルな流れによってその過程を単純化する。
これまでユーザーの多くは、Slackのチャットの中で「××を使って○○しよう」という会話をし、Slackをいったん終了してから××を立ち上げていた。Missionsを使うと、何度も同じことをやるプロセスをSlackの中からできるための、ワークフローを作れる。
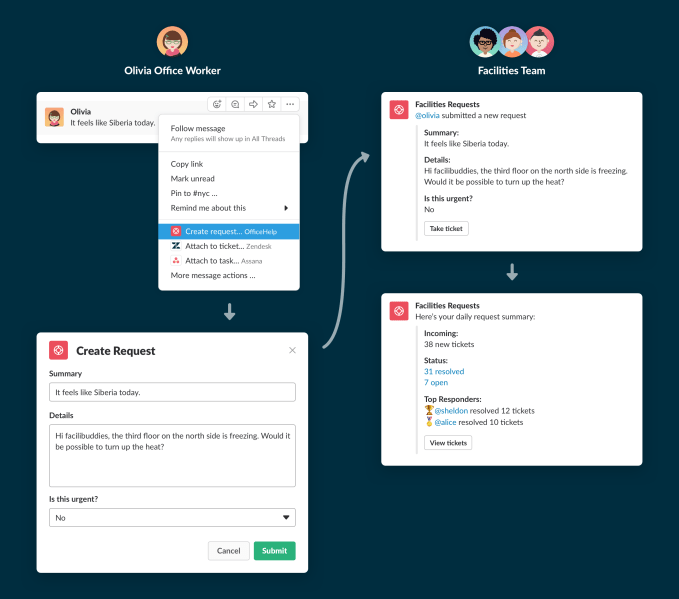
よくやるタスクといえば、たとえば新人のオリエンテーションだ。新入社員に記入すべきフォームを教え、彼らが会うべき人を教え、彼らがその日その週内に完了すべき仕事を教える。また人事などでは、人の採否決定〜通知のプロセスを頻繁に繰り返すことが多い。頻繁に繰り返すといえば、社内的なチケット発行なんかもそうだ。
Missionsの現在のユーザーは向こう数か月は無料で利用できる。その後SlackはMissionsを本格的に統合する。では、Slackの中でMissionsを使えるようになるのはいつか? 同社によると、詳細がはっきりするのは“今年の終わりごろ”、という。