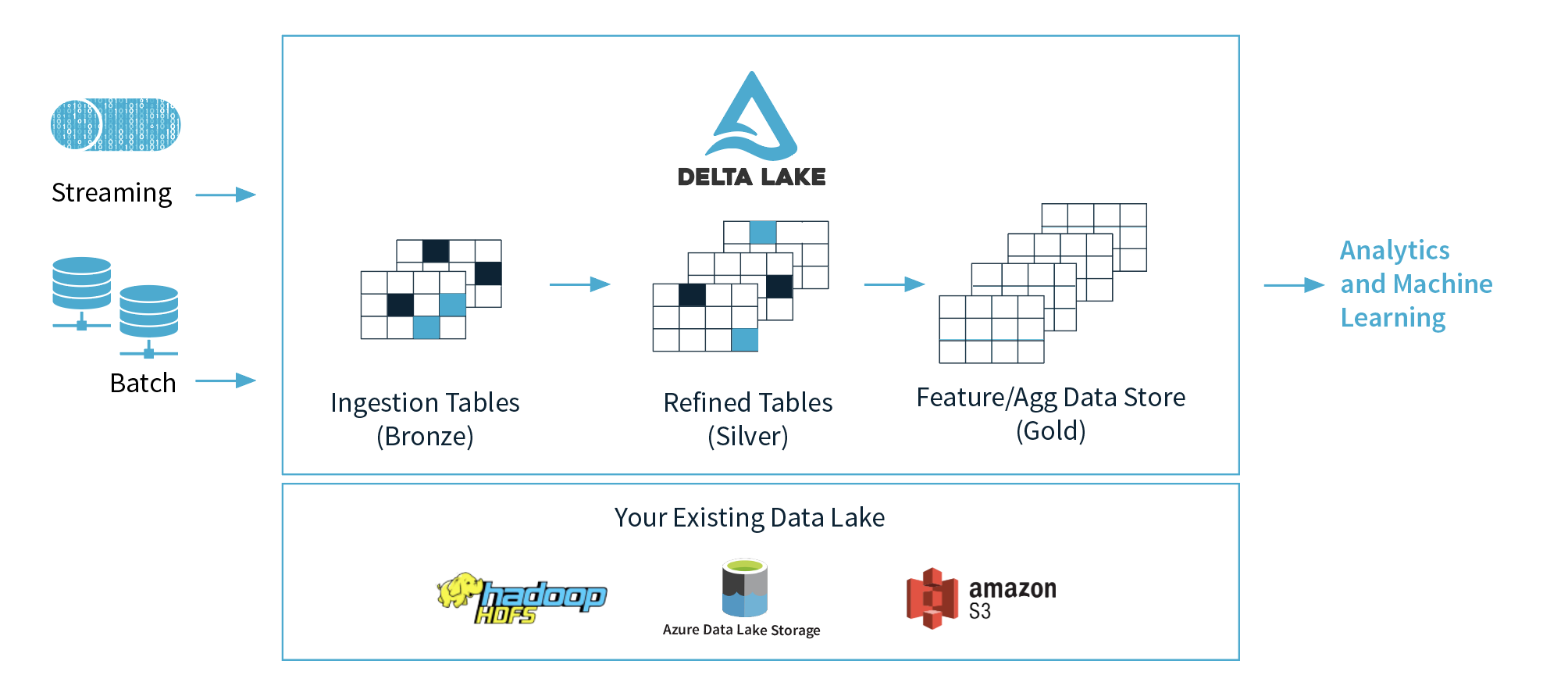
Databricksが米国時間2月24日、パートナーたちによるData Ingestion NetworkとそのDatabricks Ingestサービスの立ち上げを発表した。目的は、企業が最高のデータウェアハウスと最高のデータレイクを1つのプラットホームに結合することで、Databricksはそのコンセプトを「lakehouse(レイクハウス)」と呼んでいる。
同社のレイクハウスのコアにあるものはDelta Lakeで、これはLinux Foundationが管理するDatabricksのオープンソースのプロジェクトであり、データレイクにストレージの層を導入してユーザーがデータのライフサイクルを管理できるようにする。そして、スキーマの強制やログの記録などでデータのクオリティを確保する。DatabricksのユーザーはこれからはIngestion Networkの最初の5つのパートナーであるFivetranとQlik、Infoworks、StreamSets、Syncsortらと共同で自分たちのデータをDelta Lakeに自動的にロードできる。Databricksの顧客は、トリガーやスケジュールに関して何もセットアップしなくてよい。データが自動的にDelta Lakeに入っていく。
Databricksの共同創業者でCEOのAli Ghodsi(アリ・ゴッシ)氏は、次のように説明する。 「これまで企業は、自分のデータを伝統的な構造化データ(定型データ)やビッグデータに分割することを強いられ、それらを別々にBI(ビジネスインテリジェンス)やML(マシンラーニング)のユースケースに使っていた。これではデータがデータレイクやデータウェアハウスの中でサイロに入れられることになり、処理が遅くなるだけでなく部分的な結果ばかりになり、有効な利用ができないほど遅い、または不完全なデータになっていた。Lakehouseパラダイムへの移行にはさまざまな動機があるが、これもその1つだ。つまり、データウェアハウスの信頼性をデータレイクのスケールと結びつけて、あらゆるユースケースをサポートしたいのだ。このアーキテクチャが有効に働くためには、いろんなタイプのデータの取り入れが容易でなければならない。Databricks Ingestは、それを可能にする重要なステップだ」
Databricksのマーケティング担当副社長Bharath Gowda(バラス・ゴウダ)氏も、これによって企業が自分たちの最新のデータを分析することが容易になり、新しい情報が得られたときの反応性も良くなる、という。彼によると、ユーザーは彼らの定型データや非定型データをもっと上手に利用できるようになり、機械学習の良質なモデルを構築したり、データウェアハウスにある部分的なデータでなくすべてのデータに対する従来的な分析も可能になる。
[原文へ]
(翻訳:iwatani、a.k.a. hiwa)