
【抄訳】
Webは、脆(もろ)い場所だということがわかってきた。企業や政府機関や教育機関や個人や団体が、しょっちゅう、サイトを立てたり下ろしたりしている。でも問題は、Webが記録のシステムになってることだ。だからページが存在せずリンクが切れていたら、その記録が得られない。そこで、多くのWebページを永久保存しているボランティアサイトInternet ArchiveとWikipediaが協力して、900万の壊れたリンクを生き返らせ、わずかひとつのナレッジベースではあるけれども、この問題を解決した。
Internet Archiveは、できるかぎり多くのWebサイトのコピーを作り保存して、Webのアーカイブ(‘文書館’)を作っている。なくなったページのリンク(URL)が分かっているときは、Internet ArchiveのアーカイブWayback Machineで3380億ページのWebページを検索できる。そこには、World Wide Webの草創期からのページがある。ただし問題は、現状ではリンクのURLが正確に分かってないと探せないことだ。
しかしWikipediaのページ上の壊れたリンクは、ページのソースにそのリンクのURLが当然ある。WikipediaのコントリビューターMaximilian Doerrが、ソフトウェアの力で、その壊れたリンクの問題を解決した。彼は、Internet Archive botを略したIAbotというプログラムを作った。Internet Archiveがもう一人クレジットしているStephen Balbachは、DoerrとInternet Archiveに協力して、Wikipediaのアーカイブを調べ、データエラーを修復するプログラムを書いた。
まず、IAbotが壊れたリンクを見つけた。そういうページは、404 “page not found”、というエラーを返す。見つかった壊れたリンクをBalbachのプログラムがInternet Archiveで検索し、それがアーカイブにあったら、アーカイブのリンクに置き換える。物理的には同じページではないが、コピーだから内容は同じ…コピーを作った時点のまま…だ。
これで、死んだリンクが生き返る。
これまでの3年間で彼らのソフトウェアは、22のWikipediaサイトの600万のリンクを蘇生した。またWikipediaのボランティアたちは、手作業で300万のリンクを修復した。驚異的な作業量だが、おかげでWebのWebらしさが維持され、監査証跡も得られる。
このプロジェクトの結果を発表するブログ記事でInternet Archiveは、Wikipediaのユーザーが最近10日間にクリックしたリンクについて報告している。それによると、クリックの相当数がInternet Archiveのページだった(下図)。Wikipediaの壊れたリンクを直したことには、大きな効果があったのだ。
〔クリック数のグラフ: グラフのいちばん下の圧倒的に長い棒がアーカイブ、そのすぐ上はbooks.google.com〕
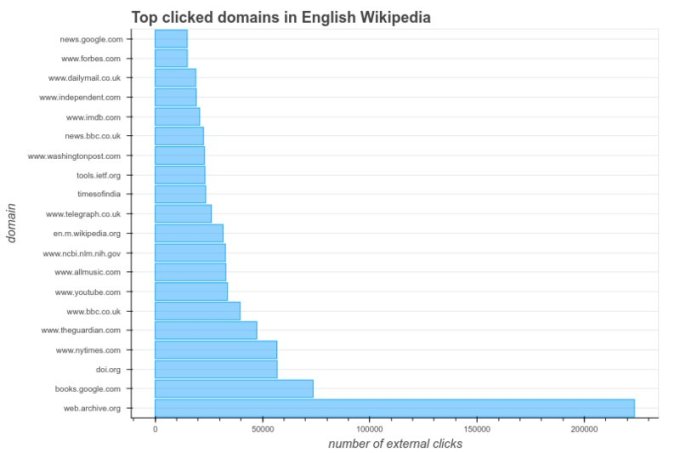
グラフ提供: Internet Archive
【後略】