
機械学習についての沢山の記事を目にして、何やら深遠なものが発見されつつあると思う人もいるかもしれないが、実際はその技術はコンピューティングと同じくらい古いものだ。
歴史上最も影響力のある計算機科学者のひとりであるアラン・チューリングが1950年に、コンピューティングに関する彼の論文の中で「機械は考えることはできるか?」という問いかけを始めたことは偶然ではない。空想科学小説から研究室に至るまで、私たちは長い間、自分自身を人工的な複製が、私たちに自分自身の意識の原点、より広義には、私たちの地上での役割、を見出すことの役にたつのだろうかと問いかけてきた。残念ながら、AIの学習曲線は本当に急峻だ。歴史を少しばかり辿ってみることによって、機械学習が一体全体何物であるのかに関しての、基本概念位は見出してみたい。
もし「十分に大きな」ビッグデータを持っていれば、知性を生み出すことができるのか?
自分自身を複製しようとする最初の試みには、機械に情報をギチギチに詰め込んで、上手くいくことを期待するようなやり方もあった。真面目な話、ただ膨大な情報を繋ぎ合わせすれば意識が発生するといった、意識の理論が優勢を占めていた時もあった。Googleはある意味このビジョンの集大成のように見做すこともできるが、同社がすでに30兆ページのウェブを収集したにも関わらず、この検索エンジンが私たちに神の実在について問いかけ始めることを期待するものはいない。
むしろ、機械学習の美しさは、コンピューターに人間のふりをさせて、単に知識を流し込むことではなく、コンピューターに推論させ、学んだことを一般化させて、新しい情報へ対応させるところにある。
世の中ではよく理解されていないが、ニューラルネットワーク、ディープラーニング、そして強化学習は、すべて機械学習である。それらはいずれも、新しいデータに対する分析を行うことのできる一般化されたシステムを作り出す方法である。別の言い方をすれば、機械学習は多くの人工知能技術の1つであり、ニューラルネットワークとディープラーニングといったものは、より広範なアプリケーションのための優れたフレームワークを構築するために使用できるツールだというだけのことだ。
1950年代のコンピューティングパワーは限られていて、ビッグデータへのアクセスもなく、アルゴリズムは初歩的だった。これが意味することは、機械学習の研究を進めるための私たちの能力は、極めて限られていたということだ。しかし、それは人びとの研究の意欲を削いだりはしなかった。
1952年のこと、Arthur Samuelはアルファ・ベータ法と呼ばれるAIの非常に基本的な形式を利用して、チェッカープログラムを作った。これは、データを表す探索木上で作業する場合に、計算負荷を減らす方法の1つであるが、全ての問題に対する最善の戦略を常に与えてくれるわけではない。ニューラルネットワークでさえ、Frank Rosenblattの懐かしのパーセプトロンが現れたものである。
いずれにせよ読む必要のある、複雑で大げさなモデル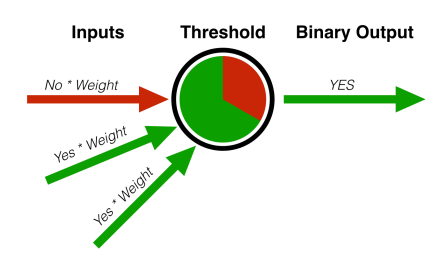
パーセプトロンは随分と時代に先行したものだった、機械学習を進めるために神経科学を利用したのだ。紙の上で、そのアイデアは右に示したスケッチのようなものだった。
それがやっていることを理解するために、まず大部分の機械学習問題は、分類(classification)もしくは回帰(regression)の問題に分解できることを理解しなければならない。分類はデータをカテゴリ分けするために用いられ、一方回帰モデルは傾向からの外挿を行い、予測を行う。
パーセプトロンは、分類装置の1例である – それはデータの集合を受け取り、複数の集合に分割する。この図の例では、それぞれの重みの付いた2つの特徴量の存在が、このオブジェクトを「緑」カテゴリーだと分類するために十分であることが示されている。こうした分類装置は、現在は受信ボックスからスパムを分離したり、銀行における不正を探知するために使われている。
Rosenblattのモデルは一連の入力を使うものだ。長さ、重さ、色といった特徴にそれぞれ重みのついたものを考えてみるとよい。モデルは、許容誤差以内に出力が収まるまで、連続的に重みを調整していく。
例えば、ある物体(それはたまたまリンゴであるとする)の重量が100グラムであると入力することができる。コンピュータは、それがリンゴであることを知らないが、パーセプトロンはその物体を、既知のトレーニングデータに関する分類装置の重みを調整することによって、「リンゴのような物体」あるいは「リンゴではないような物体」に分類することができる。そして分類装置が調整されると、それは理想的には、これまで分類されたことのない未知のデータセットに対して再利用することができる。
まあ仕方がない、AI研究者たちでさえ、こうしたことには混乱しているのだ
 パーセプトロンは、機械学習の分野で行われた多くの初期の進歩の、ほんの1例に過ぎない。ニューラルネットワークは、協力して働くパーセプトロンの大きな集まりのようなものである。私たちの脳や神経の働き方により似通っていて、それが名前の由来にもなっている。
パーセプトロンは、機械学習の分野で行われた多くの初期の進歩の、ほんの1例に過ぎない。ニューラルネットワークは、協力して働くパーセプトロンの大きな集まりのようなものである。私たちの脳や神経の働き方により似通っていて、それが名前の由来にもなっている。
数十年が過ぎて、AIの最先端では、単に私たちが理解した内容を複製しようとするのではなく、心の仕組みを複製する努力を続けている。基本的な(または「浅い」)ニューラルネットワークは、今日まだ利用されているものの、ディープラーニングが次の重要事項として人気を博している。ディープラーニングモデルとは、より多くの層を持つニューラルネットワークである。この信じられないほど満足感の得られない説明に対する、完全に合理的な反応は、その層とは何を意味するのかと問うことだ。
これを理解するためには、コンピューターが猫と人間を2つのグループに分類できるからといって、コンピューター自身はその仕事を人間と同じようには行っていないことを認識しておかなければならない。機械学習フレームワークは、タスクを達成するために抽象化のアイデアを活用する。
人間にとっては、顔には目があるものである。コンピュータにとっては、顔には線の抽象を構成する明暗のピクセルがあるものだ。ディープラーニングの各層は、コンピュータに同じオブジェクトに対して、違うレベルの抽象を行わせるものである。ピクセルから線、それから2Dそして3Dへ。
圧倒的な愚かさにもかかわらず、コンピューターは既にチューリングテストに合格した
人間とコンピュータが世界を評価する方法の根本的な違いは、真の人工知能を作成するための重大な挑戦を表している。チューリングテストは、AIの進捗状況を評価するために概念化されたものだが、この事実は無視してきた。チューリングテストは、人間の反応をエミュレートするコンピュータの能力を評価することに焦点を当てた、行動主義のテストである。
しかし模倣と確率的推論は、せいぜい知性と意識の謎の一部でしかない。2014年の時点で私たちはチューリングテストに合格したと考える者もいる、5分間のキーボードによる対話の間、30人の科学者のうち10人を、人間を相手にしているものだと信じさせることができたからだ(にもかかわらずSiriは質問の3件に1つはGoogleを検索しようとする)。
それで、「AIの冬」のためにジャケットを用意する必要はあるのか?
こうした進歩状況にもかかわらず、科学者や起業家を問わず、AIの能力への過剰な約束は迅速だった。この結果引き起こされた騒ぎと破綻は一般的に「AIの冬」(AI winters)と呼ばれている。
私たちは、機械学習によっていくつもの信じがたいことができるようになってきた、例えば自動運転車のためのビデオ映像内の物体の分類をしたり、衛星写真から収穫の予測をしたりといったことだ。持続する短期記憶は、私たちの機械に、ビデオ中の感情分析のような時系列への対処をさせることを可能にしている。ゲーム理論からのアイデアを取り込んだ強化学習は、学習を報酬を通じて支援するための機構を備えている。強化学習は、Alpha GoがLee Sodolを追い詰めることができた、重要な要因の1つだった。
とは言うものの、こうした進歩にもかかわらず、機械学習の大いなる秘密は、通常私たちは与えられた問題の入力と出力を知っていて、それらを仲介する明示的なコードをプログラムするものなのに、機械学習のモデルでは入力から出力を得るための道筋を特定することが常にできるわけではない、ということなのだ。研究者はこの挑戦を、機械学習のブラックボックス問題と呼んでいる。
ひどくがっかりする前に指摘しておくならば、人間の脳自身もブラックボックスだということを忘れてはならない。私たちはそれがどのように動作しているかを本当に知らず、抽象の全てのレベルでそれを調べることもできない。もし誰かに、脳を解剖してその中に保持されている記憶を探させてくれと頼んだら、即座にクレイジーというレッテルを貼られてしまうだろう。しかし、何かを理解できないということはゲームオーバーを意味しない。ゲームは続くのだ。
この記事では、機械学習を支える多くの基本的な概念を紹介したが、将来の「いまさら聞けない(WTF is …?)」シリーズのための沢山のネタがテーブル上に残されている。ディープラーニング、強化学習、そしてニューラルネットは、それぞれより深い議論に進むことが可能だが、願わくばこの記事を読んだ後、読者のこの分野への見通しが良くなって、日々私たちがTechCrunchで取り上げている沢山の企業間の関連が理解しやすくなることを期待している。
他の「いまさら聞けない(WTF is)」シリーズ
[ 原文へ ]
(翻訳:Sako)