
過去数十年間に、警察官に殺された人数が何人かと尋ねてみると、相手によってその結果は大きく異なる可能性がある。地方や連邦当局は、活動家並びに研究グループなどとはまた別のやり方で、それらを計算するかもしれない。そこで、警官の関わる死亡事故を、全国のニュースレポートからAIシステムに抽出させることで、より良い結果を得ようと試みるプロジェクトが登場した。
マサチューセッツ大学アムハースト校のBrendan O’Connorが指摘するのは、 事案の集計方法はところによって異なるものの、報道の曖昧性はとても少ないということだ。発砲の正当性は自体は論争になるかもしれないが、警官が発砲して誰かがを射殺したという基本的な事実を蔽い隠すことは難しい。もしコンピューターがそれらを発見することを学べれば、それは単純ではあるが有効な、全国的情報網として機能することだろう。
O’Connorとその同僚は、まず2016年のGoogle Newsのニュース記事から、警官(例えば “officer” や “cop” という単語が出てくる)または死亡(例えば “shot” や “died”)に言及しているものを抽出した。そしてこの結果から、重複や明らかなミスを取り除き、射殺に直接関連するテキストの部分(例えば「警察官BakerがJohn Doeに向け発砲し、Doeは死亡した」といった文)を特定した。
そして機械学習システムがこれらを用いて、警官に遭遇したことによって死亡した人びとのデータベースを構築しようと試みた。この訓練のための検証用データとして、研究者たちは、ジャーナリストのD. Brian Burghartが手作業で編集した、既存の警察関係の死亡事案データベースであるFatal Encountersを利用した。
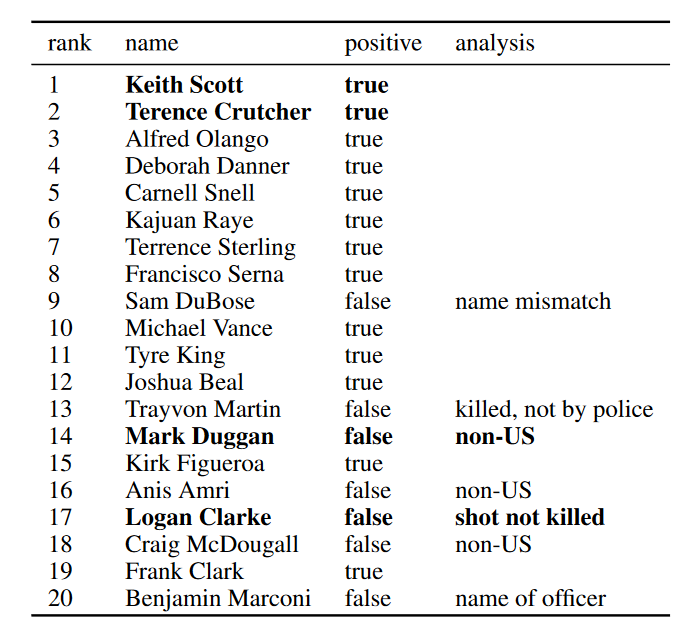
システムが最も自信を持っていた20人の名前。偽陽性は容易に同定された。
結果として得られた学習モデルは、Fatal Encountersが2016年最終四半期に収集していた警官の発砲事案の、57%を発見することができた。その数字だけを聞くと、それほど有効なもののようには思えないかもしれないが、これはこの先有望な技術なのだ。より多くのデータとさらなる訓練によって、この数字はかなり増えて行くだろう。厳密なチェックを行なうBurghartのような人びとは依然として必要だが、現在の状態でもシステムはスピードアップの役に立つ。
実際このAIシステムは、論文の結論に記載されているように、単独での利用を想定されたものではない。
1つの目標は、私たちのモデルを半自動システムの一部として利用することだ。そこでは人間が、候補として挙げられたランキングリストを手動でチェックする。
AIの最高の応用方法は、人間要素を置き換えるのではなく、補完するものでなければならない。研究者たちは、もしこのシステムがもう少し進化したなら、ニュースから別の種類の事案を抽出するように調整することもできるだろうと語っている。例えば警官が命を救ったといったニュースの抽出だ。
著者らはこの論文を、コペンハーゲンで開催された計算言語学会2017で発表した。
[ 原文へ ]
(翻訳:Sako)