
【編集部注】執筆者のSimon ChanはSalesforce Einsteinのプロダクト管理担当シニアディレクターを務めており、以前はPredictionIOの共同ファウンダー兼CEOでもあった。
AIが私たちの生活やビジネスをより良くしているという、うきうきするようなニュースを毎日耳にする。AIは既にX線写真を解析し、モノのインターネットを動かし、営業・マーケティングチームの次の一手を考え出すほどまでになった。その可能性は無限大に広がっているようにさえ見える。
しかし全てのサクセスストーリーの背景には、研究段階から抜け出せずに終わった無数のプロジェクトが存在する。というのも、機械学習の研究の成果を製品化し、顧客にとって本当に価値のあるものへと転換することは、理論上うまくいくアルゴリズムを組むよりもよっぽど難しいことが多いのだ。私が過去数年間に出会った企業の多くは同じ問題に直面しており、私はこれを「AIの溝」と呼んでいる。
最近行われたApacheConで、私はこの問題に関する考察を発表した。本記事では、AIを扱う企業が直面するであろう技術・プロダクト面での溝を越えるために必要な上位4つのポイントを紹介したい。
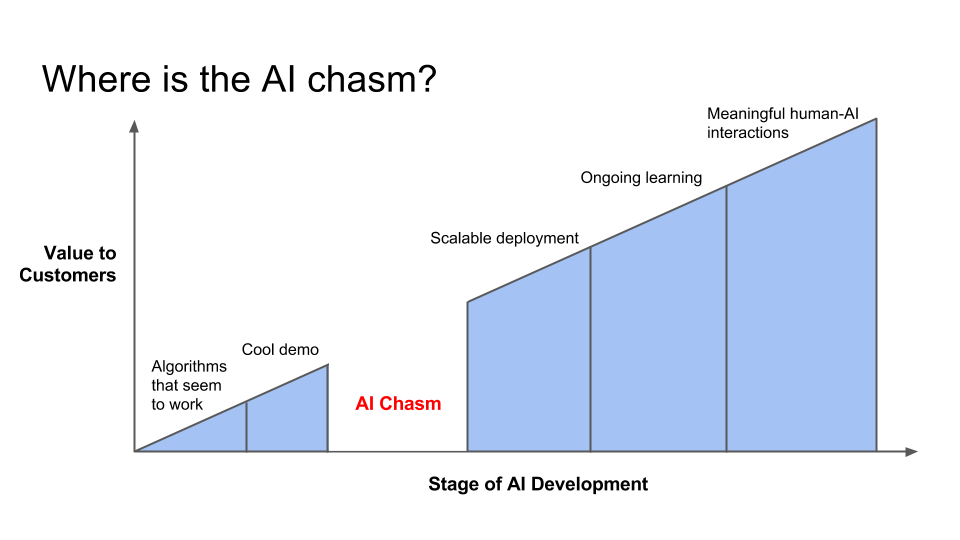
技術面におけるAIの溝
新しいデータ AIとデータは切っても切れない関係にある。例えばチャットボットをトレーニングするためには、顧客からのリクエストとそれに対する正しい回答例をアルゴリズムに読み込ませなければならない。通常そのようなデータはCSVのように、きれいに整えられた静的なフォーマットで準備されることが多い。
静的データを使って、上手く機能するAIデモを開発することはできるが、実際に使っていくうちに賢くなっていくような、自動学習タイプのAIには常に新しいデータが必要だ。そのため各企業は機械学習モデル開発の早い段階で、新しいデータをもとに定期的にAIモデルがアップデートされるような仕組みを構築しなければならない。
一方でライブデータを利用するためには無数の技術的な問題を解決しなければならない。スケジューリングやアップデート時にダウンしない仕組み、プロダクトの安定性やパフォーマンスモニタリングなどがその一例だ。さらに新しく取り入れたデータのせいで何かが起きてしまったときのために、問題が起きる以前の状態へプロダクトを復元できるような仕組みも必要だ。これが次の論点にもつながってくる。
トレーニング用データの品質管理 AI企業は製品開発当初からデータ品質に気をつけなければならない。特にユーザーから集めたデータを利用する場合にはなおさらだ。機械学習のプロセスが自動化されること自体は素晴らしいことだが、それが仇となる場合もある。最近Twitter上で問題を起こしたチャットボットは、自動化が誤った方向に進んでしまった典型例だ。
実際のところ、AIの溝とはそこまで恐ろしいものではない。
件のチャットボットは自由に会話できるようになる前に、不要なモノを省いてモデル化された公なデータをもとにトレーニングされていた。しかしその後、現実世界のユーザーとの不適切な会話からデータを読み込み始めると、ツイート内容が急激に悪質なものに変化していった。ガーベッジ・イン・ガーベッジ・アウトは機械学習の基礎的な法則であり、優秀なAIシステムは問題の芽を発見すると、人間の手が加えられるように管理者へアラートを発するようになっている。
プロダクト面におけるAIの溝
正しいゴールに向けた最適化 どのような回答をAIに求めているかを明確にすることにAIの成功はかかっている。トレーニング開始当初から、インプットされる問題とその回答、そして何を良い・悪い回答とするかということをハッキリと決めておかなければならない。データサイエンティストは、このような基準をもとにAIモデルの正確性を見極めていくのだ。
まずはゴールの設定だ。AIを使う目的は売上の最大化なのか、ユーザーエクスペリエンスの向上なのか、手作業で行われているタスクの自動化なのか、それともまた別の目的があるのか?AIプロダクトが成功をおさめるためには、ビジネス上のゴールがきちんと反映された評価基準を利用しなければならない。
この点に関し、Netflixのアルゴリズムコンテストからは学ぶべきことが間違いなくある。Netflixは新しい映画レーティング・アルゴリズムの開発者に100万ドルを授与したものの、DVDレンタルから動画ストリーミングへサービス内容が移行したことから、当初のゴールが当時の状況にマッチせず、結局そのアルゴリズムを現実で利用することができなかったのだ。
評価基準を設定するときには、以下のポイントを抑えておく必要がある。1)本当に意味がある数値を計測する 2)新しいライブデータを使って評価を行う 3)関係者が理解でき、かつ重要だと思えるように評価結果を説明する。そして3点目は人間とAIの交流という重要なポイントにつながってくる。
人間とAIの交流 人間というのは複雑な生き物だ。そのため、人間とAIが関わり合いはじめると、研究所でデータだけを相手にしていたときには浮かんでこなかったような問題が生まれてくる。消費者は信用できないようなAIプロダクトは利用しない。そして企業は予測モデルがどれほど正確か見せることで信用を勝ち取ろうとするが、ほとんどの消費者はいくら素晴らしい数値を見せられても専門的な内容を理解することができない。
結果的に企業は、プロダクトのUXやUIを利用して消費者の信用を築いていかなければならなくなる。例えばAppleはバーチャルアシスタントのSiriを最初にリリースしたとき、ユーザーのいる国に応じてデフォルト設定の声の性別を変えていた。さらにGoogleの自動運転車では、可愛らしいフレンドリーな顔が表示され、安全性に不安を感じている利用者の気持ちを落ち着けるようになっている。アルゴリズムの見せ方は、問題だけでなく解決策にもつながっているということを覚えておいてほしい。
実際のところ、AIの溝を越えるということはそこまで恐ろしいことではない。よく練られた計画と共に、下ではなく前を見ながら進んでいけば良いだけなのだ。そしてAI第一の企業になるためには、顧客第一でなければならないということをお忘れないように。
[原文へ]
(翻訳:Atsushi Yukutake/ Twitter)