
音声認識は最近のスマートフォンの標準的機能だ。人工知能を利用した分析は驚くほど正確なこともあればひどい混乱に陥ることもある。しかし最大の問題は、Siri、Alexa、Googleアシスタントなどが返事を返してくるのが遅れることだ。Googleの最新の音声認識は完全にオフラインで動作するため遅延を完全に排除できる。ただし認識失敗はやはりときおり起きる。
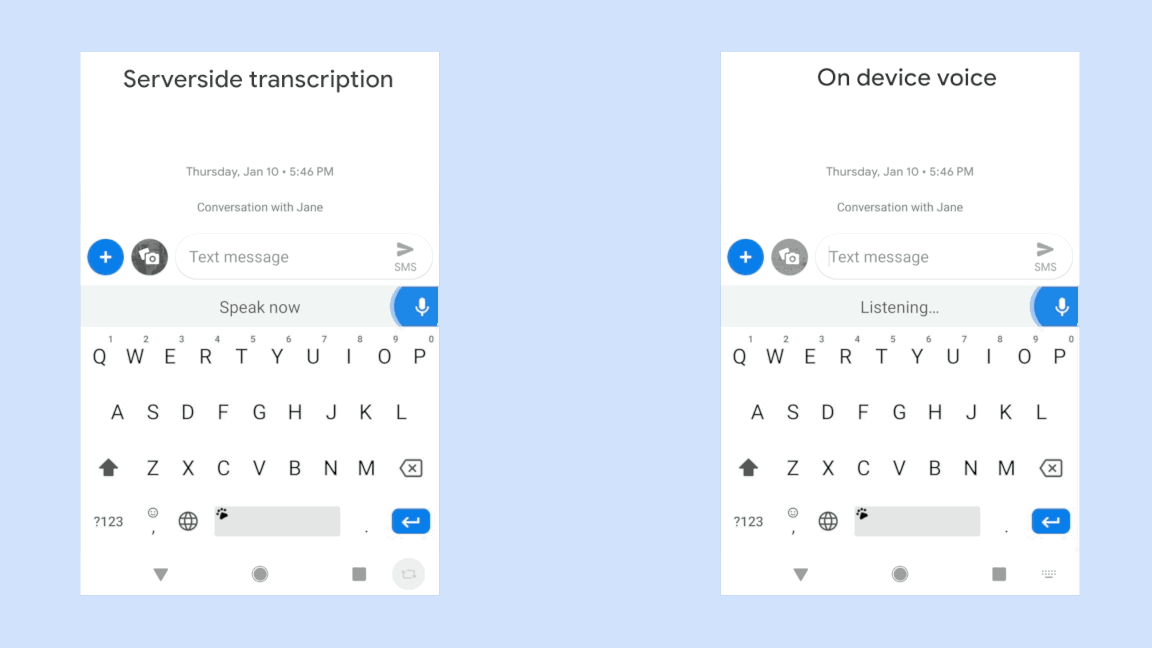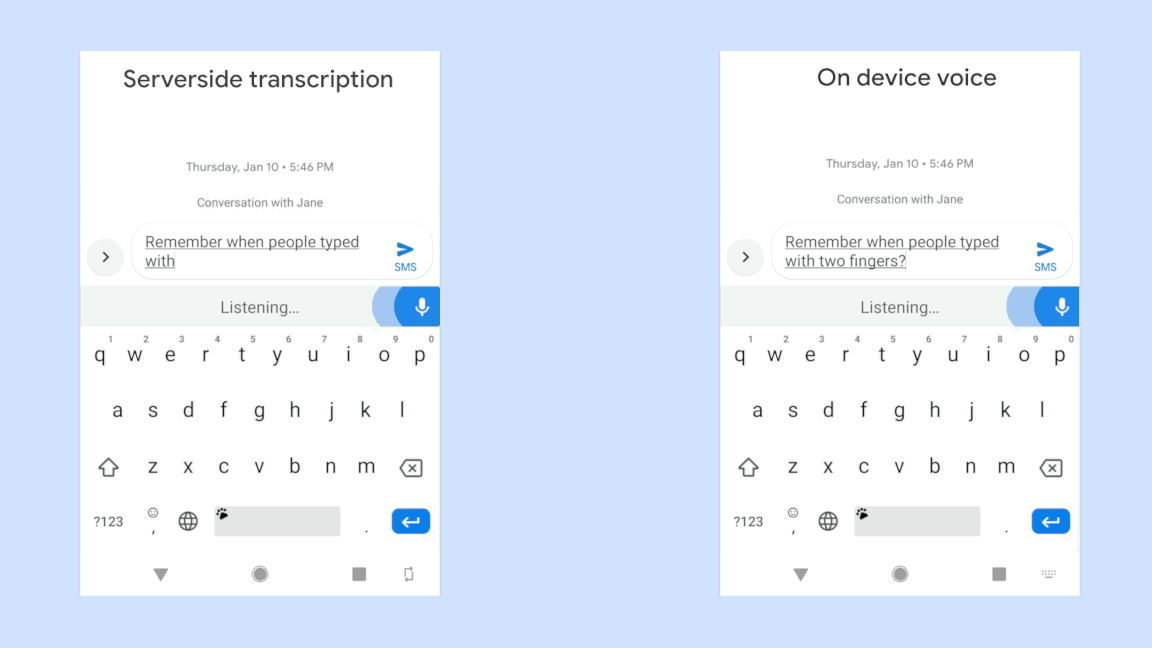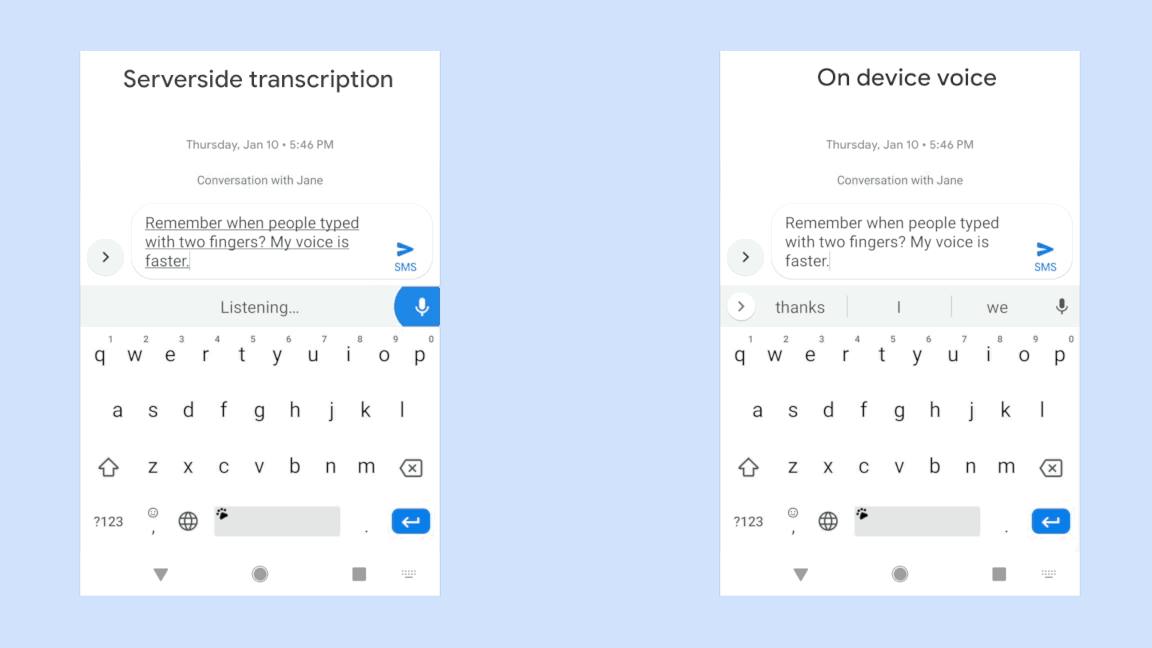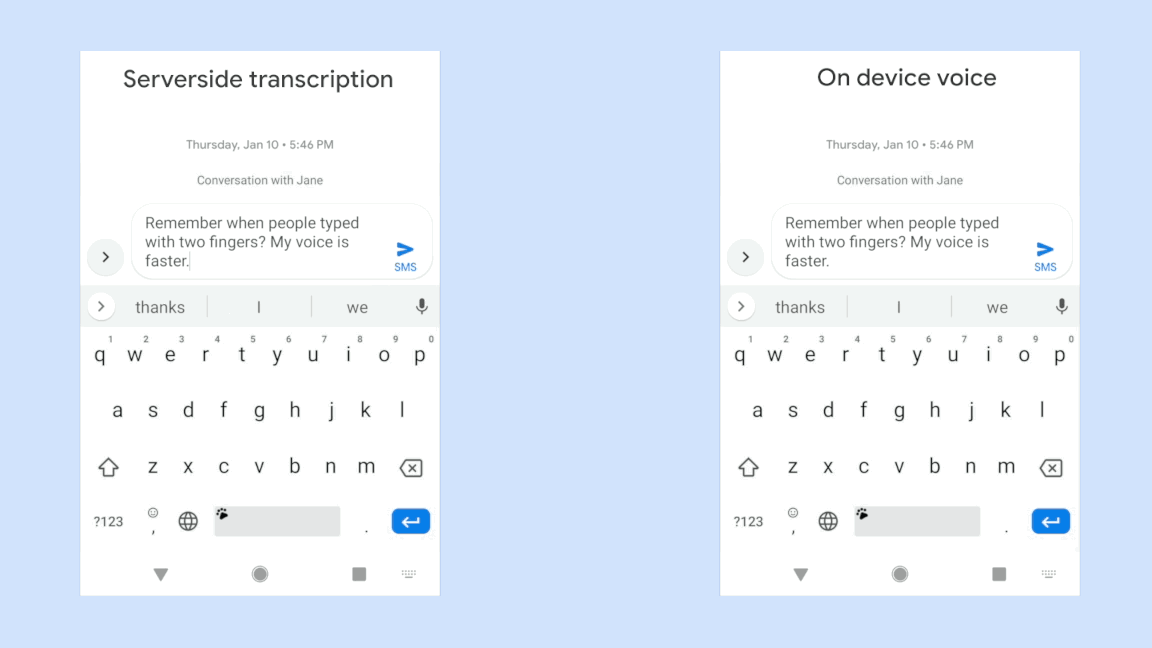
遅延がなぜ起きるのかといえば、ユーザーの音声データはローカルデバイスからネットワークを通じてはるばる音声認識エンジンが存在するサーバーまで旅しなければならないからだ。データはそこで分析されてからユーザーに戻される。当然ながらこれには時間がかかる。応答を待つ時間はミリ秒単位ですむ場合もある。しかしまるまる数秒かかることあり、そうなればユーザーは苛立たしい思いをする。最悪の場合、経路の途中でデータの一部が行方不明になり、まるきり応答が返ってこないこともある。
それなら音声認識をローカルデバイス上で実行すればいいではないか?プロバイダーもそれが理想的な解決法だと考えている。しかし音声をミリ秒単位でテキストデータに変換する処理は膨大なコンピューティングパワーを食う。つまりマイクが拾うのは単なる「音」であって「発話」ではない。音声をテキスト化するためには言語と発話が行われたコンテキストに関する膨大な情報が必要だ。
もちろんローカルデバイス上で実行することはできる。しかしユーザーのデバイスの限られたリソースを考えるとクラウドに往復させるより速くはならなかった(しかもデバイスのバッテリーをひどく食う)。だがこれは急速に進歩を続けている分野であり、Googleはそれを可能にした。ただしPixelを持っている必要がある。
 Googleの最新のテクノロジーについてはこちらの論文が詳しいが、簡単に要約すれば、Googleはこれまでの音声認識で蓄積された経験を生かして音声分析システムをスマートフォンで高速に作動するくらいいにコンパクト(正確には80MB)にまとめることに成功した。これによりユーザーはほとんd遅延を感じずに発話をテキスト化できるようになった。「their」と「there」などの同音異義表現も新しいシステムは発話終了を待たず、その場で判断できるという。
Googleの最新のテクノロジーについてはこちらの論文が詳しいが、簡単に要約すれば、Googleはこれまでの音声認識で蓄積された経験を生かして音声分析システムをスマートフォンで高速に作動するくらいいにコンパクト(正確には80MB)にまとめることに成功した。これによりユーザーはほとんd遅延を感じずに発話をテキスト化できるようになった。「their」と「there」などの同音異義表現も新しいシステムは発話終了を待たず、その場で判断できるという。
ただしテクノロジーには今のところ大きな制限がある。まずGoogleのPixelスマートフォン上のGboardアプリでしか作動しない。またサポートする言語は米英語に限られる。つまり実機によるベータテストに近い。Googleでは世界の各言語へのローカライゼーションの必要性を強調して次のように述べている。
ハードウェアコンポーネントの標準化とアルゴリズムの進歩という業界のトレンドを考えれば われわれが実現したテクノロジーが広く採用され、多くの言語、アプリが近くサポートされるようになるものと期待している。
しかし考えてみるとGoogleの他のアプリは大部分クラウド接続を必要とする。できた文書を共有したりメールで送信したりするのはもちろん、摂氏温度を華氏温度に換算するのでさえネットワーク接続が必要だ。接続状態が貧弱な場合オンラインでは音声認識が不可能な場合がある。またオフラインであればデータ伝送量を食わないですむ。こうした点は大進歩だ。
画像:Bryce Durbin/TechCrunch
(原文へ)
(翻訳:滑川海彦@Facebook Google+)