
ある言語を別の言語に翻訳するのは難しい作業だ。言語の自動翻訳システムを開発することはコンピュータ処理の目標の中でも非常に困難な部分だ。一つには、取り扱う対象となる語句の数が膨大になるからであり、それらを統べる規則を発見することは非常に難しい。幸いなことに、ニューラルネットワークは膨大かつ複雑なデータの自動的な処理が得意だ。 Googleは機械学習を利用した自動翻訳を長年にわたって開発してきたが、昨日(米国時間9/27)からその第一陣を公式にスタートさせている。
このシステムはGNMT(Googleニューラル機械翻訳=Google Neural Machine Translation)と呼ばれる。GNMTの最初のサービスは、中国語/英語の検索の自動翻訳だ。これは既存の検索システムを基礎としてニューラルネットワークを利用して改良したものだ。以下自動翻訳がどのように発達してきたか、その歴史を歴史を簡単に振り返ってみたい。
語句単位の直接置き換え
子供にせよコンピュターにせよ、いちばん直接的で簡単なのは単語やフレーズを単純に別の言語に置き換えることだろう。この方式ではニュアンスはもちろん、文の意味さえまったく失われることがある。しかしこの単純置き換え方式は対象となる文章が何について述べているか大まかな雰囲気を最小の労力で示してくれる。
言語は語句の組合せで成り立っているので、論理的に考えて、自動翻訳の次のステップはできるかぎり大量の語句とその組合せの簡単なルールを収集し、翻訳作業に適用することだ。しかしそのためには非常に多量のデータを必要必要とする(単なる二ヶ国語辞書ではとうてい足りない)。たとえば同じrunという動詞一つ取ってもrun a mile〔1マイルを走る〕、 run a test〔テストを実施する〕、run a store〔店を運営する〕ではまったく意味が違ってくる。この違いを見分けるためには膨大な例文の統計的処理が必要になる。しかしコンピューターはこうした処理が得意だ。そこで必要なデータとルールが収集されれば語句ベースの自動翻訳を実用化することができる。
もちろん言語ははるかに複雑だ。しかし単純な語句ベースの置き換えの次のステップでは複雑性やニュアンスが飛躍的に増大し、その処理に必要なコンピューティング・パワーも比例して増大する。しかし複雑なルールセットを理解し、それに基づいた予測モデルを作るのはニューラルネットワークの得意とするところだ。自動翻訳ではこの分野が長年研究されてきが、今回のGoogleのGNMTの一般公開は他の研究者に大きなショックを与える進歩だろう。
GNMT(Googleニューラル機械翻訳)は機械学習の翻訳への応用として最新かつ格段に効果的な手法だ。GNMTは文全体を視野に入れながら個々の語句にも細かい注意を払っている。
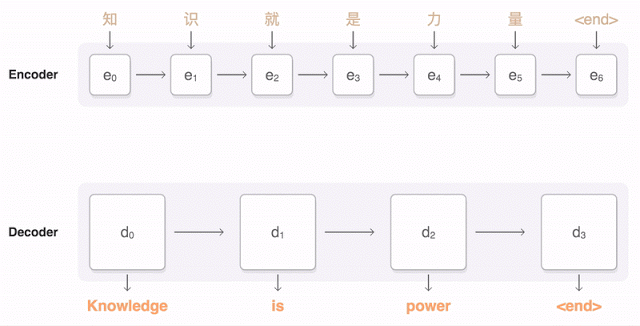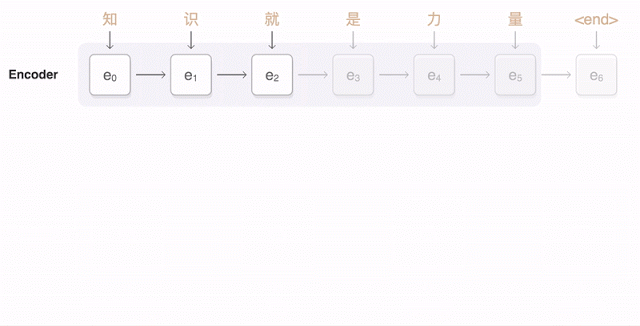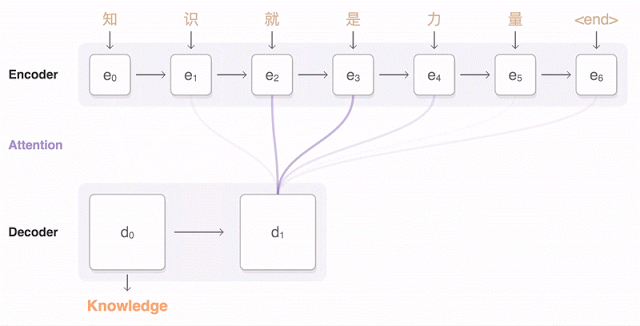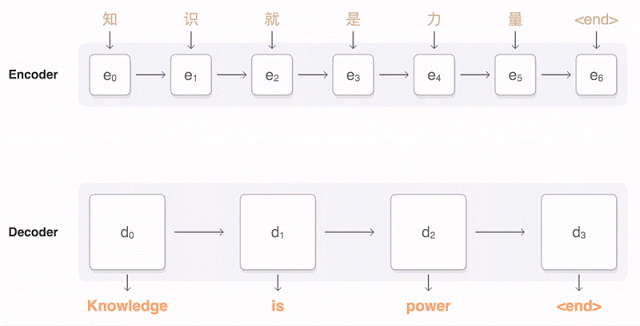
アニメによる中国語の翻訳の説明。中国語の単語が探知されると翻訳されるべき言語との関連で重み付けがなされる(青い線)。
全体を眺めながら細かい部分も意識しているという点で、われわれが画像を認識するときの頭脳の働きに似ている。しかしこれは偶然ではない。ニューラルネットワークは人間の認識のプロセスを模倣して対象が何であるか判別できるよう訓練される。したがって画像をゲシュタルトとして認識することと文の意味を認識することの間には単なる表層的なもの以上の類似点がある。
興味ある点だが、ニューラルネットワークの応用としては、言語のみに特有な点はほとんどない。このシステムは未来完了形と未来進行形の区別はできないし、語句の語源やニュアンスについても知らない。すべては数学モデルであり、統計処理として実行される。いわゆる人間の感性は入って来ない。翻訳という人間的作業をメカニカルな統計処理に分解してしまう手際には感嘆せざるを得ないが、ある種の気味の悪さも感じる。もちろんGNMTはそのようなメカニカルな翻訳で十分であり、それ以上の技巧や深い解釈は必要とされない分野に対応したシステムだという点に注意が必要だろう。
技巧を取り除くことによって技術を進歩させる
GNMTついての論文には、計算処理量の縮減という技術的ではあるが、重要な進歩がいくつか紹介されている。計算量のオーバーヘッドが大きくなり過ぎるというのは言語処理のシステムでよく見られる陥穽だ。
例えば、言語システムはめったに使われない珍しい単語によって窒息することがある。使用頻度の少ない語句は他の語句の文脈の中に適切に位置づけることが難しい。GNMTは珍しい語句をほぼ同じ意味で使用頻度の高い語句に分割し、置き換えることによってこの困難を迂回する。システムは置き換えられた語句を他の語句との関連で組織する。
正確性をある程度犠牲にすることによって実際の計算時間が短縮される。この処理にはニューラルネットワークを訓練することを念頭に置いて設計されたカスタム・ハードウェアであるGoogleテンソル計算ユニットが用いられる。
機械学習におけるインプット・システムとアウトプット・システムは大きく異る。しかし両者が接触するインターフェイスを通じて情報をやり取りし、協調して訓練されるることによって統合的な結果を生成するプロセスだという点は共通だ。ともあれ私が理解できた範囲ではそういうことになる。論文にはさらに詳しい情報が掲載されているので、そういう情報が必要な読者は参照されるとよいだろう。
結果としてニューラルネットワーク機械学習システムはは語句ベースの置き換えシステムをはるかにしのぐきわめて正確な結果をもたらす。翻訳品質は人間の作業のレベルに近づく。自らのビジネスの本質に関わる検索という分野でGoogleがウェブとアプリで動作するシステムを一般公開するのであれば高品質でなければならないというのはよく理解できる点だ。しかもターゲットは中国と英語という変換作業が非常に困難な組合せだ。
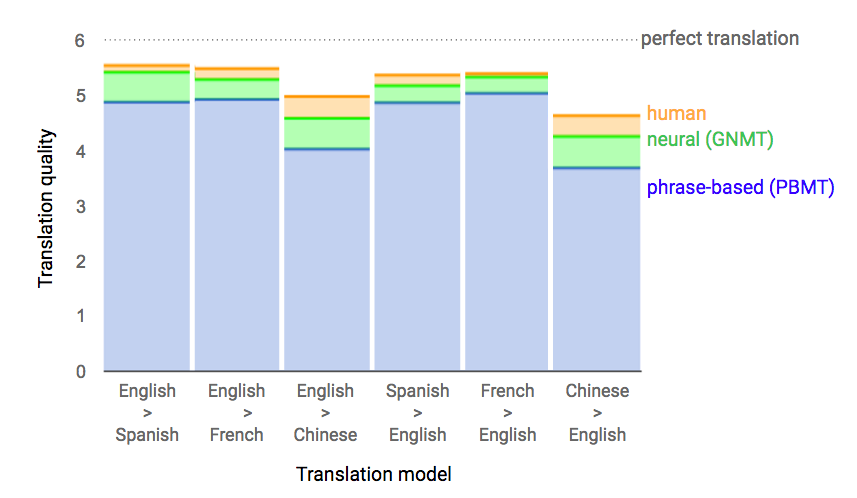
スペイン語とフランス語についても良好なテスト結果が得られているという。おそらくここ数ヶ月のうちにGNMTはそれらの言語に拡張されるはずだ。
ブラックボックス化というトレードオフ
こうした手法のデメリットの一つは、機械学習を利用した予測モデルに往々にして生じる問題だが、内部でどのような処理が行われているのか実際のところ誰も確かめることが出来ないという点だ。
GoogleのCharina ChoiはTechCrunchの取材に対して「GNMTは他の大規模なニューラルモデル同様、膨大なパラメーターの集合であり、訓練の成果がどのような内部処理となっているのか見通すことが難しい」と述べた。
もちろんこれはGNMTをデザインしたエンジニアがこのシステムが何をしているのか理解できないという意味ではない。しかし語句ベースの置き換え型翻訳は、結局のところ人間が個別パーツをプログラムしている。したがってある部分が間違っていたり時代遅れになっていることが判明すれば、そのパーツをまるごと削除したりアップデートしたりできる。ところがニューラルネットワーク利用システムの場合、何百万回もの訓練セッションを通じてシステム自身が自らをデザインするため、何かがうまく行っていないことに気付いても、簡単にその部分を置き換えることができない。訓練によって新しいシステムを作り出すのは困難を伴う作業となる。もちろんそれは実行可能だし、場合によっては短時間しかかからないはずだ(また、そのように構築できるなら新たな課題が発見されるたびに自らを改善していくシステムとなっているだろう)。
Googleは機械学習に同社の将来の大きな部分を賭けている。今回公開されたウェブおよびモバイルでの自動翻訳検索はGoogleのニューラルネットワーク応用システムの最新かつもっとも目立つ一例だ。ニューラルネットワークはきわめて複雑、難解でいく分か不気味でもある。しかしこの上なく効果的であることを否定するのは難しい。
画像: razum/Shutterstock
〔日本版〕原論文はコーネル大学のアーカイブ・サイトにアップされたPDFファイル。誰でも無料でダウンロード可能。名前から判断すると研究者のうち3人は日本人(日系人)らしい。ただし日本語については音声認識における語句切り分け問題に関して言及があるだけで、日本語のGNMT翻訳については特に触れられていない。しかし従来の例から考えて日本語のGNMT応用についても研究は進んでいるはず。近い将来何らかの発表があるものと思われる。
[原文へ]
(翻訳:滑川海彦@Facebook Google+)