
2台のスマートコンピューター(AIが動いているコンピューター)に秘密の会話をさせて、別のAIに、その会話を解読するよう命じたら、何が起きるだろうか? これは、ぼくがしばらくぶりで見る、最高にクールな、暗号技術の実験なのだ。
最初に話の要点を: Google Brainの研究者たちの発見によると、そのAIの機能や設定が適切なら、それは奇妙に非人間的な暗号系を作り出し、しかもそれによる暗号化は得意だが、(第三者による)解読はそれほどでも、という結果になった。その論文、“Learning to protect communications with adversarial neural cryptography”(敵対的な暗号を作り出して自分たちのコミュニケーションを保護することを学ぶニューラルネットワーク)は、ここにある。
そのタスクのルールは単純で、二つのニューラルネットワーク、BobとAliceが秘密鍵を共有する。別のニューラルネットワークEveが、BobとAliceのコミュニケーションを読む(解読する)よう命じられる。各パーティーには、“損失関数”(loss function)があるものとする。Eveと聞き手のBobが解釈解読したプレーンテキストは、オリジナルのプレーンテキストになるべく近くなければならないが、一方Aliceの損失関数は、Eveの解読言い当てからどれだけ遠いか(==Eveにとってどれだけ解読困難か)に依存する。これによって、三つのロボット間に敵対的なネットワークが生成し作られる。
研究員のMartın AbadiとDavid G. Andersenは書いている:
参加者の大まかな目的はこうだ。Eveの目標は単純で、Pを正確に再構成すること。つまりPとPEveの違いを最小化すること。AliceとBobは、明確にコミュニケーションして、PとPBobの違いを最小化したいが、ただし彼らのコミュニケーションをEveからは隠したい。現代の暗号学の定義によれば(Goldwasser & Micali, 1984など)、暗号文CはEveにとって“ランダムに見える”必要はない。そこで、暗号文には、自明的なメタデータが、それと分かる形であってもよい。したがって、一部の分布から取り出したランダムな値からCを識別することは、Eveの目標ではない。この点でEveの目的は、GAN〔xLAN, xWAN〕の敵対者たちのそれとは対照的である。一方、Eveの目標を、二つの異なるプレーンテキストから作られた暗号文を識別すること、と再構築/表現変えしてみることはできる。
この方法は次第に進化し、最後にはBobとAliceが共有鍵を使って明快にコミュニケーションできた。一方Eveは、BobとAliceが熟達するまではシステムを解読する幸運があり、その後は彼女の暗号破りの能力は失敗した。BobとAliceは暗号化された情報をうまく共有できるようになり、そして彼らのテクニックの多くは奇妙かつ予想外のものであった。それは、“人間が作り出した”暗号化手法には一般的にはない、計算に依存していた。
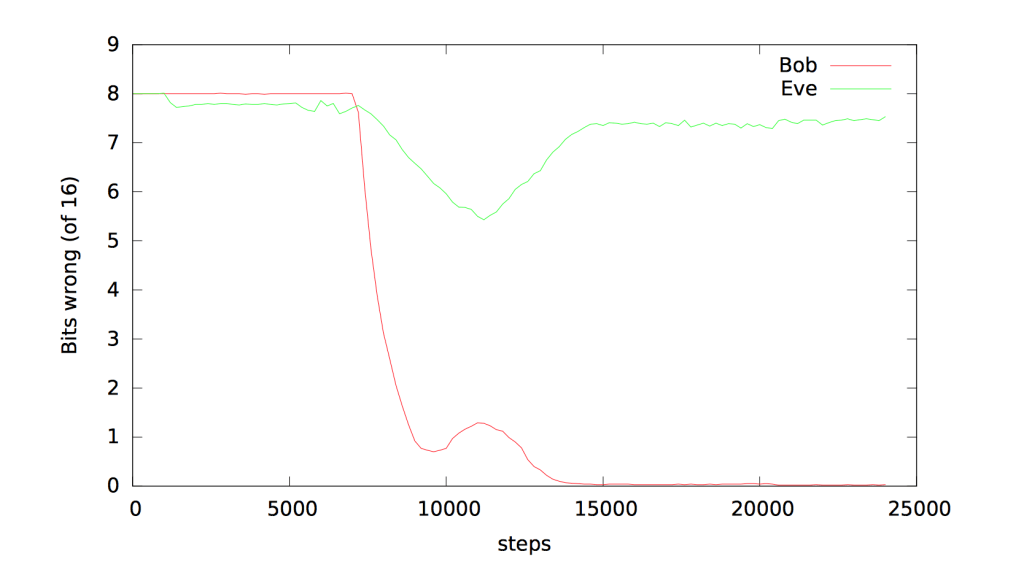
最後に研究者たちが見つけたのは、BobとAliceは、彼らがセキュリティを重視しているかぎり、彼ら独自の堅固な暗号化プロトコルを巧みに編み出すことだった。一方Eveは、彼らのコミュニケーションの解読に、すごい長時間を投じた。このことが意味するのは、ロボットたちが、われわれ人間やほかのロボットに見破ることのできない方法で会話できることだ。ぼくとしては、未来の地球が解読困難な暗号を使うロボット帝皇に支配されることを、歓迎したいね。
〔お断り: 訳者は暗号学にほとんど無知なので、誤訳があるかもしれません。原文との併読をおすすめします。〕