先月、私はベテランのセマンティック検索のストラテジストであるバーバラ・スターにインタビューを行った。この記事の中で、エンティティ検索に焦点を絞り、検索の未来を想像してもらいたいと読者の方々にお願いした。スター氏と私は、関連性の高い、コンピュータが認識可能な「エンティティ」を利用して、具体的で、よく絞り込まれたクエリに対する答えを提供する「アンサーエンジン」について議論を行った。
ハミングバード
10月26日、グーグルは、ハミングバードアップデートを実施し、アンサーエンジン化をさらに進めた。ダニー・サリバンは、ハミングバードアルゴリズムに関するライブブログの中で、古いアルゴリズムのパーツを維持しながらも、グーグルが、急速にセマンティックウェブのテクノロジーを採用していると指摘していた。これは、「テキストリンク」から、「答え」に進化するためのグーグルのソリューションである。このシステムは、検索用語ではなく、ユーザーの意図に焦点を絞るセマンティックテクノロジーに重点を置いているため、より正確な結果を、より早く提示することが可能になる。
グーグルのアンサーエンジンへの方針転換を振り返ってみよう。まず、ナレッジグラフを導入し、続いて、音声検索、そして、グーグルナウが登場した。全て答えを提供するための取り組みであり、時には質問を予測することも出来る。答えを提供するため、グーグルは、キーワードではなく、エンティティに頼る。
そもそも「エンティティ」って何?
エンティティとは、人物、場所、そして、物事を指す。エンティティを紹介する上で、グーグルのナレッジグラフがエンティティグラフであり、これは、セマンティック検索(あるいはエンティティ検索)を活用する最初の試みであったことを理解してもらいたい。
それでは、「エンティティ検索」とは何なのだろうか?簡単に言うと、エンティティ検索とは、検索クエリに答えるために、認証された情報源を割り当てつつ、ボットが、ユーザーの意図を正確に理解するためのメソッドである。

非構造化データ vs 構造化データ
過去20年間、インターネット、検索エンジン、そして、ウェブユーザーは、非構造化データに対処しなければならなかった。非構造化データとは、所定のデータモデルによる整理、もしくは、分類を行っていないデータのことである。このように、検索エンジンは、ウェブページ内のパターン(キーワード)を理解することは可能だったものの、ページに対して意味を与えることは出来なかった。
セマンティック検索は、各情報をエンティティとしてラベル付けして、データを分類するためのメソッドを提供する — これが、構造化データと呼ばれるものだ。 大量の非構造化データを含む小売の製品データを例にとって考えてみよう。データの構造化を進めると、小売店やメーカーは、非常に詳細で正確な製品データを検索エンジン(マシン/ボット)に見てもらい、理解してもらい、分類してもらい、そして、認証した情報の文字列として、まとめてもらえるようになる。
セマンティック検索やエンティティ検索が、改善するのは、小売製品のデータだけではない。schema.orgのschemaの種類に注目してもらいたい — このschemaは、構造化されたデータによるウェブ(固有の識別子を持つエンティティ)を作るための技術的な言語であり、機械による認識が可能になっている。機械が理解することが可能な構造化データは、曖昧ではなく、信頼性が高い — ウェブ上のその他のつながりを持つデータソースと比較して、照合を行うことも可能である。
構造化データ、 トリプル & トリプルストア
セマンティック検索は、フェイスブックのオープングラフプロトコルのようなボキャブラリ、もしくは、RDFaやマイクロデータのようなシンタックスを使って、構造化データを作成する。構造化データは、トリプルストアからのインポートおよびエクスポートが可能である。この点を詳しく説明していこう…
トリプルストアとは、トリプルの保存および回収を行うためのデータベースである。トリプルストアには、大量のトリプルを保存することが出来る。
トリプルとは何だろうか?簡潔にまとめると、Subject(主語)、Predicate(述語)、そして、Object(目的語)を含む、あらゆる文を構成する3つのパーツの組み合わせである。トリプルとは、基本的に、主語-述語-目的語で構成された、リンクで結ばれたエンティティのことである。主語は、人物/物事であり、動詞が示す行動を遂行する。述語は、主語が実行する行動である。そして、目的語 は、行動の対象となる人物/物事である。
トリプルの例を挙げる: ケラー夫人は、代数を教えている。
ケラー夫人 → 主語 → エンティティ
代数 → 目的語 → エンティティ
教えている → 述語または関係 → エンティティを結びつける
トリプルは、Uniform Resource Identifier(URI: 情報資源の場所を示す記述方式)として表現される。アンサーエンジンは、トリプルストアの大規模なデータベースにアクセスし、無数の主語、目的語、そして、述語を結び、関係を形成する。その結果、内部で認証されたデータ、そして、信頼された文書(構造化データ)を結ぶ関係を確認して、クエリに対する正確な答えが提供されるようになる
リンクから答えへ
グーグル、ビング、ヤフー!等の機械が理解することが可能なschemaのタイプを使って、この論理とテクノロジーを拡大していくと、IBMのワトソンコンピュータのような、キーワードやアンカーテキストリンクを利用することなく、質問に答えることが可能な「アンサーエンジン」が生まれる。
構造化データは、ページのコンテンツの意味に関する詳細な情報を、容易に処理して、ユーザーに提示することが可能な方法で、検索エンジンに提供する力を持つ。
データの理解 vs データのインデックス
ここで、再び、「エンティティとは何か?」と言う質問に戻ろう。グーグルのナレッジグラフにおいて、エンティティとは、セマンティックデータのオブジェクトであり(schemaのタイプ)、それぞれのエンティティが固有の識別子を持つ。また、意味を表す現実の世界のトピックの属性に基づいた、特性の集合体であり、当該のトピック、そして、その他のエンティティとの関係を現すリンクでもある。
2010年7月、グーグルがメタウェブを買収した時、データベース「フリーベース」には、1200万点のエンティティが存在した。2012年6月の時点で、グーグルのナレッジグラフは、5億点のエンティティを記録し、エンティティ間の関係は35億点に達していた。その後の16ヶ月間で、大幅にボリュームはアップしているはずだ。
機械が認識することが可能な構造化データをウェブに加えることで、データを「インデックス」する能力に対して、データを「理解」する検索エンジンの能力は大幅に高まり、アンサーエンジンを介して、質問に対してより正確な答えを獲得する上で、2つの大きな進歩をもたらすようになる:
- ユーザーの意図を理解する上で、遥かに優れたメソッドを用いることが出来るようになる
- 巨大な構造化データのデータベースから、ユーザーに対して最も信頼性が高く、最も正確な答えにマッチする、認証された構造化データを引き出すことが出来るようになる。
キーワードのインデックス vs 自然な言語の理解
SEOのエキスパート、セマンティックのストラテジスト、そして、検索エンジンは、– 「ウェブサイトを支援して、非構造化データをインデックスさせる」取り組みから「機械が認証することが可能な構造化データをウェブ上で提供して、ウェブサイトを支援する」取り組みへと移ろうとしている。
エンティティの抽出
例を挙げるため、そして、少し深く掘り下げるため、以下にイメージを掲載する。このイメージから、「Place」(場所)に対するschemaのタイプの階層、そして、そのバリエーションを多少見ることが出来る — Courthouse(裁判所) vs. Embassy(大使館) vs. Apartment Complex(アパート) vs. Canal(運河)。このように、エンティティの抽出が、セマンティック検索を動かす中心的な取り組みであることが、このイメージには鮮明に表れている。そのため、エンティティこそが、検索のビジビティの未来そのものだと言っても過言ではない。オーソリティ、信頼性、ファインダビリティ等もその中に含まれる。
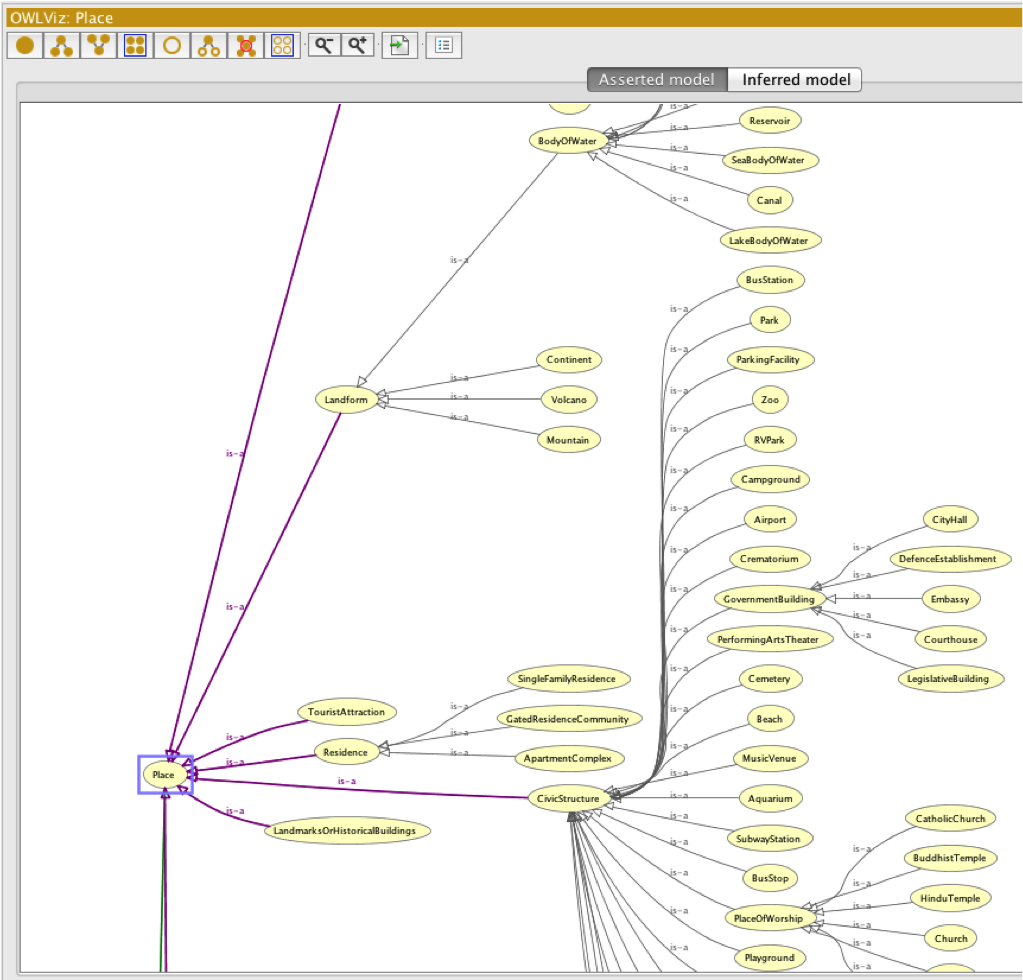
schema.org “Place” 階層 – Protege
セマンティックコミュニティ、学界、W3C、情報学者、グーグル、ビング、ヤフー!、企業の優れたウェブサイト、SEOのエキスパート、ウェブディベロッパー、ウェブデザイナー、インタラクティブエージェンシー等は、セマンティックテクノロジーを使ってツールを作り、セマンティックマークアップをウェブに実装して、セマンティック検索の改善に既に着手している。
- サンドロ・ホーク氏によるリンクトデータの紹介(動画: 38分): リンクトデータ配信の概念と手法
- GoodRelations: ウェブのeコマースサイトにアノテーションを作成するためのオントロジー
- グーグルがschema.orgを導入: グーグル、ビング、ヤフー!がウェブページの構造化データに対応
- schema.org: htmlタグ等、schemaの集まり
- ティム・バーナーズリー氏が語るウェブの未来(動画: 16分)データの力とは
- LinkedData.org: 構造化データの配信および接続
- Europeana Linked Open Data: リンクトオープンデータ
- W3C リンクトデータ: リンクトデータとは?
- Protege: 無料のオープンソースのオントロジエディタ
セマンティックマークアップを使ってデータとコンテンツを見えるようにする
過去3年の間に口を酸っぱくして言ってきたことだが、セマンティックマークアップを使って、全てのビジネスのデータとデジタルコンテンツに検索エンジンが容易にアクセスすることが可能な環境を作るべきである。
ビジネスのデータは、リッチメディアの動画コンテンツ、製品のレビューや評価、場所や連絡先情報、専門分野の詳細、特売、製品の情報等で構成されている。繰り返すが、schema.orgのschemaのタイプをチェックしてもらいたい。
セマンティックマークアップをサイトに実装すると、ビジネスのデータを検索エンジン、ウェブアプリ、カーナビ、タブレット、モバイルデバイス、アップルの地図アプリ、Siri、イェルプの地図、リンクトオープンデータ等のマシンが読めるようになるためだ。
セマンティックマークアップは、ビジネスのデータをまるでチョコレートのように検索エンジンに提示する — 検索エンジンは、大いに気に入り、最後まで食べきる。検索エンジンは、データを隅から隅まで理解し、SERPでのユーザー体験を向上させるため、データを集める情報を心得ている。また、検索エンジンが、構造化データを使って、より関連性の高い検索結果を提供する一方で、CTRが上がるため、ウェブマスターもまたメリットを得ることが出来る。
最後に
セマンティック検索が、浸透するにつれ、セマンティックマークアップを利用することで、グーグルがナレッジグラフに対して必要とするエンティティの情報をグーグルに与えることが出来るようになり、その結果、検索エンジンは、様々なデバイスでユーザーのクエリに、より適切な答えを提供するようになる。セマンティックマークアップの採用が増加しても、キーワードに焦点を絞ることは可能だ。ただし、未来のSERPでビジビリティを確立するには、セマンティック検索を理解し、そして、受け入れて、正しく構造化データを利用する能力を高めていく必要がある。
検索エンジンは、ユーザーのクエリに対して、より正確な答えを提供するため、機械が読むことが可能なコンテンツを求めている。 ユーザーは、デスクトップ/ラップトップよりもスマートフォン/タブレットを優先し、パーソナライズドされた答えを求めている(Monetate – 2013年第一四半期 ショッピングサイト)。
そのため、SEOの関係者は、セマンティックテクノロジーおよびエンティティ検索のコンセプトを理解しなければならない。まずは、バーバラ・スターが投稿した「検索が台頭する10の理由」を参考にして、すぐに実行に移せる10点の作業に取り掛かってもらいたい。
この記事の中で述べられている意見はゲストライターの意見であり、必ずしもサーチ・エンジン・ランドを代表しているわけではない。
この記事は、Search Engine Landに掲載された「Future SEO: Understanding Entity Search」を翻訳した内容です。