
遍在するビデオカメラと高度な顔認識技術によって可能になる恐怖の監視国家を心配している人は多い ― しかし最新の研究によると、最高のアルゴリズムでも、百万人以上の顔を区別するとなると絶対確実からはほど遠いようだ。
ワシントン大学のMegaFace Challengeは、昨年末から行われている顔認識アルゴリズムの公開競技だ。狙いは、画像データベースサイズの桁が増えていった時、システムが人間に勝てるかどうかを見ることにある。
多くのシステムが何百万、何億人の写真を使って顔を学習しているが、実際のテストは「Labeled Faces in the Wild」等のセットで行われ、その数は1万3000枚ほどだ。しかし、実世界の状況はそれとは違う。
「顔認識アルゴリズムのテストは『地球規模』で行われるべきだと推奨するのは、われわれが最初だ、と研究チームのリーダー、Ira Kemelmacher-ShlizermanがTechCrunch宛のメールで言った。「多くの人たちがその重要性に同意すると思う。大きな問題は、公共データベースとベンチマークを作ることだ(同じデータを使って競争できる)。ベンチマークの作成は大変な作業だが、研究に大きく貢献する」
研究者らはまず、既存のラベル付けされた人々の画像から始めた ― 様々な分野の有名人のセットや、幅広い年齢の人々のセット等がある。彼らはそこに、FlickrからCreative Commonsライセンス付きの顔写真を入手し、「不正解ノイズ」として加えた。
彼らは、ノイズを10から最大100万まで増やしてテストをした ― 正解の数は変えずノイズだけを増やした。
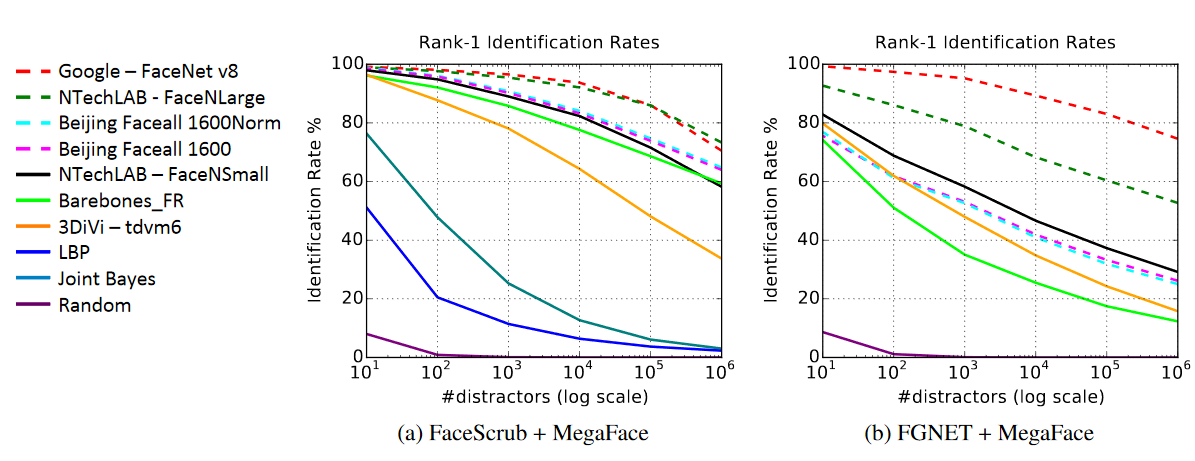
テストの結果、少数の驚くほど頑強なアルゴリズムが浮上した。幅広い年齢セットで圧勝したのは、GoogleのFaceNetで、同システムとロシアのN-TechLabが、有名人データベースでは接戦だった(中国四川省のSIAT MMLabには特別賞)。
有名なところで名前がないのはFacebookのDeepFaceで、間違いなく有力な優勝候補のはずだ。しかし、参加は任意であり、Facebookはシステムを公開していないので、MegaFacesでの成績は謎のままだ。
上位2システムのいずれも、ノイズが増えるにつれ数字は確実に下がっているが、有効性はグラフの対数スケールほどには低下しない。GoogleがFaceNetの論文で主張する超高精度の値は、ノイズが1万件を超えると達成されなくなり、100万になると、他には大差をつけているものの、何かの目的に使えるだけの精度は得られなかった。
それでも、100万件のノイズの中から4人中3人を見つけるのはすばらしい ― ただし、その成功率は法廷やセキュリティー製品では通用しない。どうやら監視国家が現実になるのはまだ先のようだ。
研究成果は、一週間後にラスベガスで行われるConference on Computer Vision and Pattern Recognitionで発表される。
[原文へ]
(翻訳:Nob Takahashi / facebook)