
[筆者: Josh Klahr](Atscaleのプロダクト担当VP)
今年もまたStrata + Hadoop Worldが始まる。それはいつも、一歩引いてセッションの内容を一望し、ビッグデータの最新の動向を理解するための、良い機会だ。
これまで毎年のようにこのカンファレンス参加してきた人は、このイベントがオープンソースの技術を実験するソフトウェアデベロッパーのための催しから、重要なエンタープライズソフトウェアの大会に変わってきたことを、目撃されただろう。今ではデベロッパーだけでなく、企業の役員たちや、ベンダー、プロフェッショナルなサービスのプロバイダーたちが一堂に会して、この分野の最新の開発について共有し、学習している。
サンノゼで行われる今年の大会の、もっともホットな話題を知るために、この週全体にわたるコンテンツ(教育訓練クラス、キーノート、プレゼンテーションなど)のタイトルに登場する言葉の頻度を数えてみた。当たり前のような言葉(Hadoop, data, analytics, Apacheなど)を取り除いて集計すると、上位の語彙は下図のようになる:
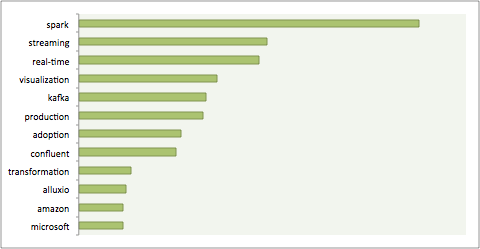
このデータをじっくり見ると、ビッグデータ界隈における、いくつかの重要なトレンドが浮かび上がってくるのではないだろうか。
Sparkの採用と関心が成長を続けている: 採用の絶対数では依然としてHadoopがトップだが、このところ、ビッグデータのエコシステムにおけるSparkの成長が著しい。HadoopとSparkは二頭の王座、と言えるかもしれない。とりわけSparkはユースケースの幅が広くて、データのパイプライン処理や、データサイエンスワークロードの並列処理といった分野でも利用されている。
ストリーミングとリアルタイムが“次の大物”: 上図では、“streaming”や“real-time”と並んで、“kafka”、そしてKafkaの商用ディストリビューションである“confluent”が上位に来ている。今企業は、Hadoopのクラスタにデータをバッチでロードし処理することには成功し、次の段階として、リアルタイムのデータ取り入れ、処理、そして分析へと関心を移しつつある。
視覚化は依然として重要: AtScaleのHadoop Maturity Surveyによると、最近の企業はますます、Hadoop上のビジネスインテリジェンスユースケースの展開に力を入れつつある。その関心は、データサイエンスへの投資を上回っている(メディアは今でもデータサイエンスを“セクシー(ナウい!)と持ち上げているけど)。データの視覚化とセルフサービスは、Hadoopの世界においても、今後も重要な投資対象であり続ける。
SQL-on-Hadoopが脇役から主役に昇進: 上図のHadoop World上位語彙のリストにはSQL-on-Hadoopが見当たらない。前年までは、Hiveに始まりImpalaやSparkSQL(そしてそのほかの商用SQL-on-Hadoop製品の数々)に至るまで、これらの技術に対する熱い関心があった。しかしSQL-on-Hadoopは勢いが衰えたのではなくて、Hadoopツールキットにおける“必須品目(must have)”になり、メインストリームの一員になったのだ。Hadoop上のビジネスインテリジェンスに関する最近のベンチマークが示しているように、今ではこれらのSQLエンジンが大規模で分析的なSQLワークロードをサポートしている。
インメモリサブストレート…それは次の最適化か?: 語彙リストの上位に登場している“alluxio”とは、なんだろうか? Alluxioは、最近Tachyonから改名された仮想分散ストレージシステムだ。それはメモリ基板(サブストレート)を利用するストレージなので、クラスタ間のデータ共有がメモリのスピードで行われる。SQL-on-Hadoopエンジンの場合ならそれによってクェリの時間が速くなりパフォーマンスが上がる。Alluxioを採用したBaiduの経験でも、確かに彼らの分析的データ処理がスピードアップしている。
Hadoopの採用が最大の関心: “adoption”と“production”がリストの上位: 今では多くのIT組織が、次世代のデータプラットホームとしてHadoopに大きな期待を寄せ、ワークロードをTeradataのようなレガシーシステムから、もっとローコストでスケーラブルな環境へ移行させつつある。これらの組織にとって重要なのは、彼らのHadoopへの投資が、ビジネスインテリジェンスなどの中核的なビジネス機能によってプロダクションクラスタ(実用・現用システムで使われるクラスタ)の形で採用され、現実にコスト低減に貢献している、と実証することだ。“production”へのこだわりは、試用やパイロットの段階を超えた実践実用レベルへの関心の強さを表している。
クラウド上のビッグデータを忘れるな: AmazonとMicrosoftの二社がリストに登場している。Hadoopへの取り組みが遅かったMicrosoftも、今ではビッグデータの分野で大きな成功を収め、HDInsightのようなサービスを提供している(WindowsではなくLinux上で動く!)。そしてAmazonは前から一貫して、ビッグデータの分野に大きな貢献を果たしている。中でもとくにRedshiftは、S3やEMR(Elastic MapReduce)などの人気サービスを補完するサービスとして、採用が引き続き増加している。