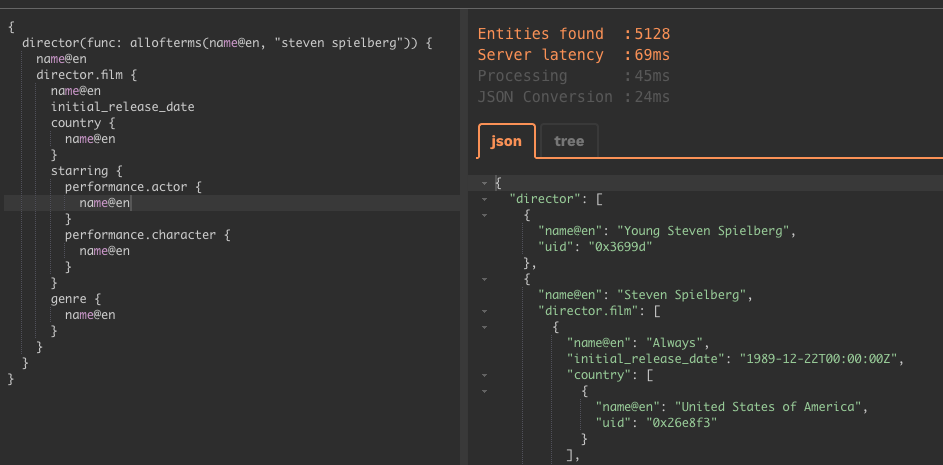
AWSが昨年のre:Inventカンファレンスで紹介したグラフデータベースNeptuneが、今日(米国時間5/30)から一般公開された。それはあのとき発表された数十ものプロジェクトのひとつだから、思い出せない人がいても不思議ではない。
NeptuneはTinkerPop GremlinとSPARQLのグラフAPIをサポートしているので、いろいろなアプリケーションと互換性がある。AWSによるとこのサービスはエラーから30秒以内に復旧し、99.99%の可利用性を約束する。
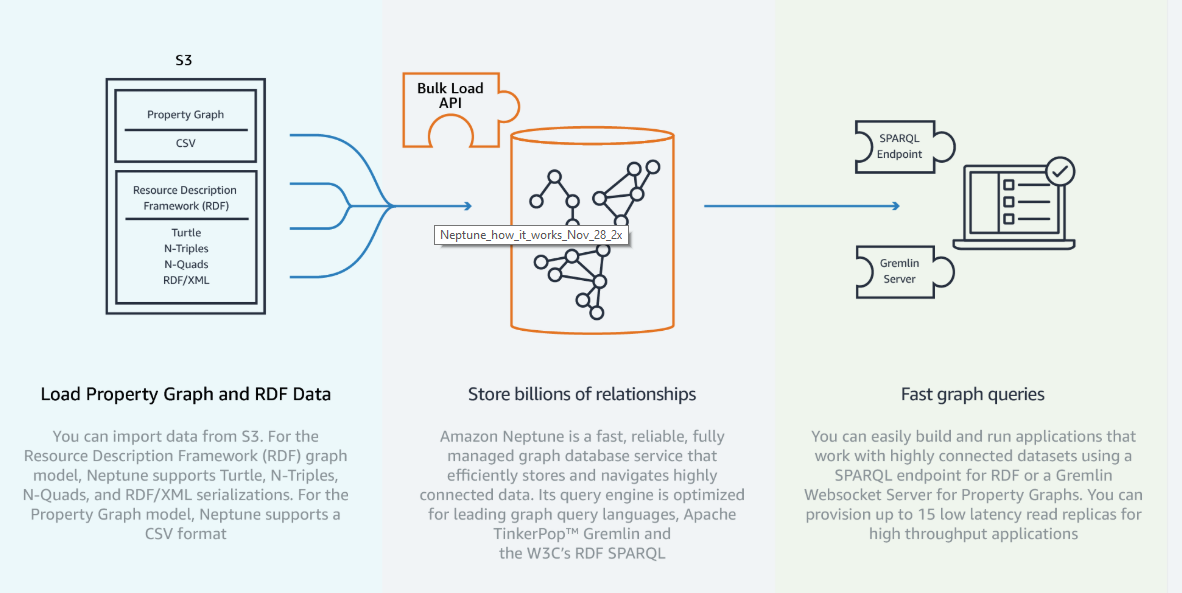
AWSでデータベースとアナリティクスと機械学習を担当しているVP Raju Gulabaniは次のように語る: “世界がますます接続された世界になるに伴い、互いに接続された大きなデータセットをナビゲートするアプリケーションが顧客にとってますます重要になる。そういう時期に、スタンダードなAPIを使って何十億もの関係性を数ミリ秒でクェリできる高性能なグラフデータベースサービスを提供できることは、たいへん喜ばしい。これにより多くのデベロッパーが、高度に接続されたデータセットを扱うアプリケーションを容易に作って動かせるようになるだろう”。
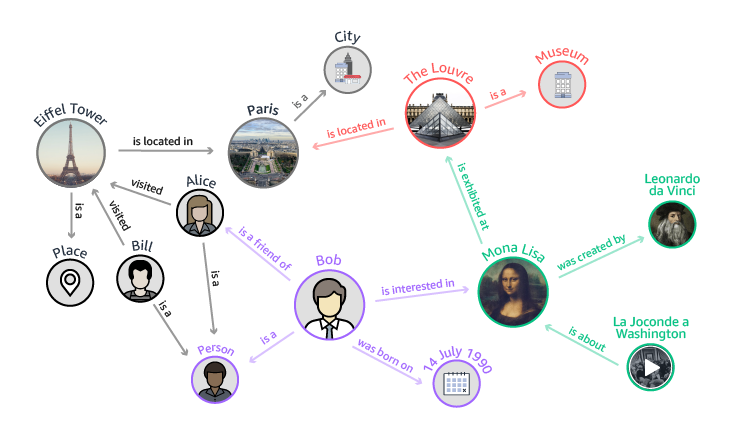
Neptuneに好適なアプリケーションといえば、ソーシャルネットワーク、リコメンデーションエンジン、不正行為検出ツール、エンタープライズのインフラストラクチャの複雑なトポロジーを表現しなければならないネットワーキングアプリケーションなどだ。
Neptuneにはすでに、有名企業のユーザーがいる。それらは、Samsung, AstraZeneca, Intuit, Siemens, Person, Thomson Reuters, そしてAmazon自身のAlexaチームなどだ。AlexaのディレクターDavid Hardcastleが、Neptuneの発表声明の中でこう述べている: “Amazon Neptuneは、Alexaの数千万の顧客のためにAlexaの知識グラフを継続的に拡張していくための欠かせないツールキットだ。今日はその正式スタートの日だが、これからもAWSのチームと協力してさらに良いユーザー体験を顧客に提供していきたい”。
今このサービスは、AWSのU.S. East(N. Virginia), U.S. East(Ohio), U.S. West(Oregon), EU(Ireland)の各リージョンで利用できる。そのほかのリージョンでも、今後随時提供されていく予定だ。