先日、Googleは、GoogleBotが間もなくHTTP/2に対応することを明かした。今回はコラムニストのパトリック・ストックス氏の記事を掲載する。HTTP/2とは何か、SEOにどんな影響を与えるか、について解説した内容となっている。

*記事内のリンク先は全て英語となっています。
たった1つの変更を加えるだけで、ウェブサイトの読み込み速度が上がり、サーバーの利用するリソースが減り、サイトスピードを増加させるために開発者が必要とする作業時間が短縮され、その上、ランキングが上がると言ったら、私はうそつき呼ばわりされてしまうだろう。あまりにも出来過ぎた話は、逆に信頼に欠けるものだ。そうだろう?
しかし、今回はその法則が当てはまらない。過去20年間のWebテクロノジー史上、指折りの進歩がついに現実となりつつある。しかし、SEO業界では、あまり議論されていないようだ。
バリー・シュワルツ氏が投稿したGoogle Webmaster Central Hangoutを要約した記事の中で、GoogleBotが、今年の年末、あるいは、来年の年明けまでに、HTTP/2に対応するというGoogleのジョン・ミュラー氏の発言が取り上げられていた。この記事を読んだところ、私はSEO業界全体がざわめき、大々的に報じられることになると確信した。しかし、実際には、それほどの盛り上がりを見せなかった。
HTTP/2への対応を行う理由は多くあるが、スピードの向上はその中でも大きな変化である。また、サイトスピードが上昇することで、ユーザー体験を向上させる効果もある。さらに、潜在的なランキング要素になるとも思えるのだ。
HTTP/2とは?
HTTP/2とは、Internet Engineering Task Force(IETF)が提唱するHTTPプロトコルの最新版である。HTTP/2は、1999年に策定されたHTTP/1.1を引き継ぐものである。Webは時間の経過とともに変化しているため、このプロトコルの更新は以前から切望されていた。今回の更新により、効率、セキュリティー、そして、スピードの面で進歩したのである。
HTTP/2が誕生した経緯
HTTP/2は、Google独自のプロトコルである、SPDY(2016年に廃止予定)をベースとしている。このプロトコルは、HTTP/2と同じ特徴を多く持ち、過去の互換性を保ちつつ、データの転送を改善していた。HTTP/2で用いられている多くのコンセプトは、SPDYで既に証明されている。
HTTP/2における主要な改善点
- シングルコネクション
ウェブサイトを読み込むためにサーバーに接続する回数は、たったの1度だ。また、この接続は、ウェブサイトが開いている限り、開いたままの状態が継続される。その結果、複数のTCPコネクションを張るために必要な、ラウンドトリップの回数を減らすことができる。 - マルチプレックス
同じ接続で、同時期に複数のリクエストを送信することができる。 HTTP/1.1では、データの送信は、別の送信が完了するまで待たなければならなかった。 - サーバープッシュ
今後の利用のために、追加のリソースを(クライアントからのリクエストがなくても)クライアント側に送信することができる。 - 優先順位づけ
サーバーが優先順位の高いリソースを早く提供するため、依存関係のレベル(重み付け)がリクエストに割り振られる。 - バイナリ
サーバーがパースを簡単に行えるようになり、よりコンパクトに、そして、エラーを減らすことができる。テキストから、コンピュータのネイティブの言語であるバイナリーに情報を変換するために、余分な時間を費やす必要はなくなる。 - ヘッダーの圧縮 HTTP/2は、HPACKという圧縮方式を利用しており、オーバーヘッドを減らすことができる。HTTP/1.1では、多くのヘッダーがすべてのリクエストにおいて、同じ値で送信されていた。
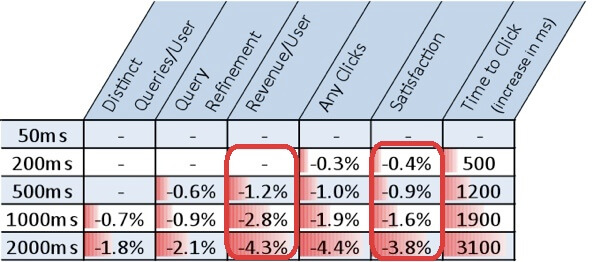
画像の読み込みを例にHTTP/2の動きを確認できるデモがいくつかある。待ち時間が長くなるほど、HTTP/2の速さが際立つようで、これはモバイルユーザーにとっては朗報と言えるだろう。
*上記、HTTP/1.1とHTTP/2の読み込み速度の比較デモのページです。
HTTP/2への対応状況
Can I useによると、アメリカのユーザーが用いるブラウザの76.62%、そして、世界全体のユーザーが用いるブラウザの67.89%が、HTTP/2に対応している。ただし、Internet Explorer 11はWindows 10でのみHTTP/2に対応し、また、Chrome、Firefox、そして、OperaではHTTPSの利用が前提となっている。
ブラウザによって対応が変わるわけだが、各ブラウザからのあなたのサイトへの流入の比較は、Googleアナリティクスで確認することができる。ユーザー>ユーザーの環境>ブラウザとOS、で表示される画面で確認しよう。
また、Apache、Nginx、IISなどの大半のサーバーソフトウェアや、AkamaiなどのメジャーなCDNも、HTTP/2を既にサポートしている。
HTTPSとHTTP/2
HTTP/2は、セキュアな接続もセキュアでない接続にも対応しているが、MozillaのFirefoxもGoogleのChromeもHTTPSでのみ、HTTP/2をサポートしている。残念ながら、これはHTTP/2の利用を望む多くのサイトが、HTTPSにも対応しなければならないことを意味している。
しかし、幸いにも、Let’s Encrypt(2015年12月3日にパブリックベータをリリース予定)などの新しい取り組みが存在している。Let’s Encryptは、セキュリティ証明書をウェブサイトに無料で発行する新たな認証機関である。より安全なウェブを目指した、素晴らしい取り組みだと言える。
*日本時間の12月4日にパブリックベータとなりました。
HTTP/2の利用によるユーザーのための改善
何といっても最大のメリットはスピードだ。そして、早ければ早いほど、ユーザー体験は良くなる。時間の経過とともに、そして、新しいプロトコルの力をユーザーが悟るにつれ、HTTP/2の接続でのスピードの増加を実感するはずだ。
HTTP/2が開発者に与える影響
HTTP/1.1の時代に使用されていた、Webの速度を改善するための多くの手法は、HTTP/2では不要となる。こうした最適化への取り組みには多くの開発時間がかかり、また、スピードとファイルの読み込みにおける性質的な問題を隠す取り組みでもあったが、同時に別の問題も引き起こしていた。
- ドメイン・シャーディング
複数のサブドメインからファイルを読み込むため、より多くの接続が行われてしまう。並列に行うファイル通信が増加すると、サーバー接続のオーバーヘッドが増えてしまう。 - イメージスプライト
画像ファイルを組み合わせることで、リクエスト回数を減らす。画像ファイルが表示される前に、ファイルの読み込みが行われる必要があり、大きなファイルは、RAMを独占してしまう。 - ファイルの組み合わせ
CSSとJavaScriptのファイルを、リクエストを減らす目的で、組み合わせること。その結果、リクエストを実施する前にユーザーはファイルを待つ必要があり、RAMを余計に食ってしまうデメリットもある。 - インライン化
CSSとJavaScriptのコードや画像をHTMLに直接埋め込み、接続を減らす。しかし、RAMに負荷をかけ、HTMLのダウンロードが完了するまで、ページの読み込みを送らせてしまう。 - クッキーなしのドメイン
画像、CSS、JavaScriptのファイルなどの静的なリソースは、クッキーを必要としない。そのため、開発者は、クッキーなしのドメインから、こうしたリソースを送り、帯域幅と時間を節約するようにした。HTTP/2では、(クッキーを含む)ヘッダーは圧縮されるため、リクエストのサイズは、HTTP/1.1と比較すると、大幅に小さくなる。
最後に、REST APIを使用する私と同類のマニアックな人達には、今後は、リクエストをバッチ処理する必要がなくなったと伝えておく。
HTTP/2の利用によるサーバーのための改善
上記で紹介した手法の多くは、ブラウザーによって開かれた接続が増えるために、サーバーに余計な負荷をかけてしまう。このような接続に関連する手法は、HTTP/2では行う必要がない。つまり、必要な帯域幅は低くなり、ネットワークのオーバーヘッドは減り、サーバーのメモリの利用も少なくなるのだ。
モバイルでは、複数のTCPの接続は、モバイルネットワークの問題を起こす可能性があり、その場合、パケットを落とし、再びリクエストを送信することになる。そして、リクエストが増えると、サーバーの負荷も増えてしまう。
HTTP/2自体もサーバーにメリットをもたらす。まず、先程も触れたとおり、必要とされるTCPの接続は減る。また、HTTP/2はパースがより簡単であり、よりコンパクトで、エラーが少ないのだ。
HTTP/2がSEO担当者に与える影響
GoogleBotがHTTP/2に対するサポートを加えるため、このプロトコルに対応するウェブサイトは、スピードアップの恩恵を受け、ランキングが上がる可能性がある。その上、ChromeとFirefoxがHTTPSでのみHTTP/2をサポートするため、まだHTTPSに対応していないウェブサイトは、さらにランキングが上がるかもしれない。
ただし、HTTPSに関しては注意点がある。HTTPSでは多くの技術的なアイテムを正しく実施しなければならず、この作業に失敗すると、HTTPから切り換えた際、少なくとも一時的に、ランキングが落ちてしまう可能性がある。
HTTPSに切り換える際に、一番多く発生している問題は、リダイレクトにかかわるものだ。301の代わりに302を利用する問題だけでなく、リダイレクトの配置や作成、リダイレクトへのホップやチェーンの追加、過去のリダイレクトの処理忘れなどをよく見る。他にも、内部リンク、(可能な場合は)外部リンク、混合したコンテンツ、重複するコンテンツの問題、canonicalタグ、サイトマップ、トラッキングシステムなど、対処しなければ問題が山積みとなっている。
以下の、ゲイリー・イリーズ氏の発言を肝に銘じておきたいところだ。
【ツイートの翻訳】
あなたがSEOを担当者であり、HTTPSへの移行に反対する意見を推奨しているのであれば、あなたの考えは誤っており、反省するべきだ。
Googleのランキングシグナルに指定されている以外にも、ウェブサイトの安全性を高めるべき理由は他にもある。セキュリティ対策が実施されたサイトから、されていないサイトに移ると、ヘッダー内のリファラーのデータが失われてしまう問題は、あまり知られていない。
Google Analyticsでは、本来ならば、リファラーのウェブサイトにトラフィックの出所が認められるべきところが、ダイレクトに指定されてしまうことになる。また、AT&Tが無料Wi-Fiのホットスポットで広告を挿入していたことが明らかになったが、HTTPSを使っていれば、ウェブサイトに広告を挿入される試みを防ぐことができる。
読み込みに時間がかかると、コンバージョンにマイナスの影響を与えてしまうことや、ユーザーに見捨てられてしまうことがよく言われている。反対に、スピードアップがセールスとコンバージョン率を増やすこともよく言われている。HTTP/2は、より早く、より優れたユーザー体験を提供することを覚えておいてもらいたい。
Googleは、理由があって、スピードをランキング要素に加えている。HTTP/2自体がランキング要素になるのかどうか、そして、Googleが、さらなるスピードアップに対してどれだけ点数を加えてくれるのか、興味深いところだ。
SEOの担当者、開発者、サーバーの管理者、営業チームはもちろん、その他の大勢の人達もHTTP/2への取り組みに参加するべきだ。HTTP/2への対応が原因で、デメリットが発生することはない。HTTP/2でサイトを読み込むことが出来ない場合、今まで通りの方法で読み込むことになるだけである。そこで、私とともに屋上から、または、Twitterを使って叫ぼうではないか。
「Everyone should be making the move to #http2!(みんなHTTP/2に対応すべきだ!)」
最後になるが、ここで、先日、Internet Summitでビル・ハーツァー氏と交わした会話で浮かんだ、面白い考えを紹介しよう。それは、実は、GoogleがHTTPSを推奨し、HTTPS上でのみHTTP/2をサポートするのは、競合する広告ネットワークの一部を排除することになるためではないか、という考えだ。
ハーツァー氏は、このアイデアに対する根拠はないと言っていたが、筋は通っている。小規模な広告ネットワークの多くは、HTTPSに対応しておらず、HTTPSを薦め、HTTPS上でのみHTTP/2をサポートすることで、Googleの広告のマーケットシェアが増える可能性が高くなる、という考えである。
この記事の中で述べられている意見はゲストライターの意見であり、必ずしもSearch Engine Landを代表しているわけではない。
この記事は、Search Engine Landに掲載された「Why Everyone Should Be Moving To HTTP/2」を翻訳した内容です。