
Googleは米国時間5月7日、Cloud TPU Podsの第2世代と第3世代を発表した。このクラウドベースのスケーラブルなスーパーコンピューターは、最大1000基の同社特製のプロセッサ、Tensor Processing Units(TPU)を使用する。それを本日からは公開ベータで一般に利用できる。
最新世代のv3は特に強力で、プロセッサーは水冷されている。一つ一つのポッドが最大で100ペタFLOPSの演算能力を持ち、Googleによれば、世界のスーパーコンピューターの5位以内に入るそうだ。ただし、このTPUポッドはあまり高い演算精度を望めないだろう。
TPU Podは、その全体を使わなくてもいい。Googleはこれらのマシンのスライスをレンタルで提供している。しかし、いずれにしても極めて強力なマシンであり、ResNet-50の標準的な画像分類モデルをImageNetの(100万を超える)画像データセットで訓練する処理を2分で終える。
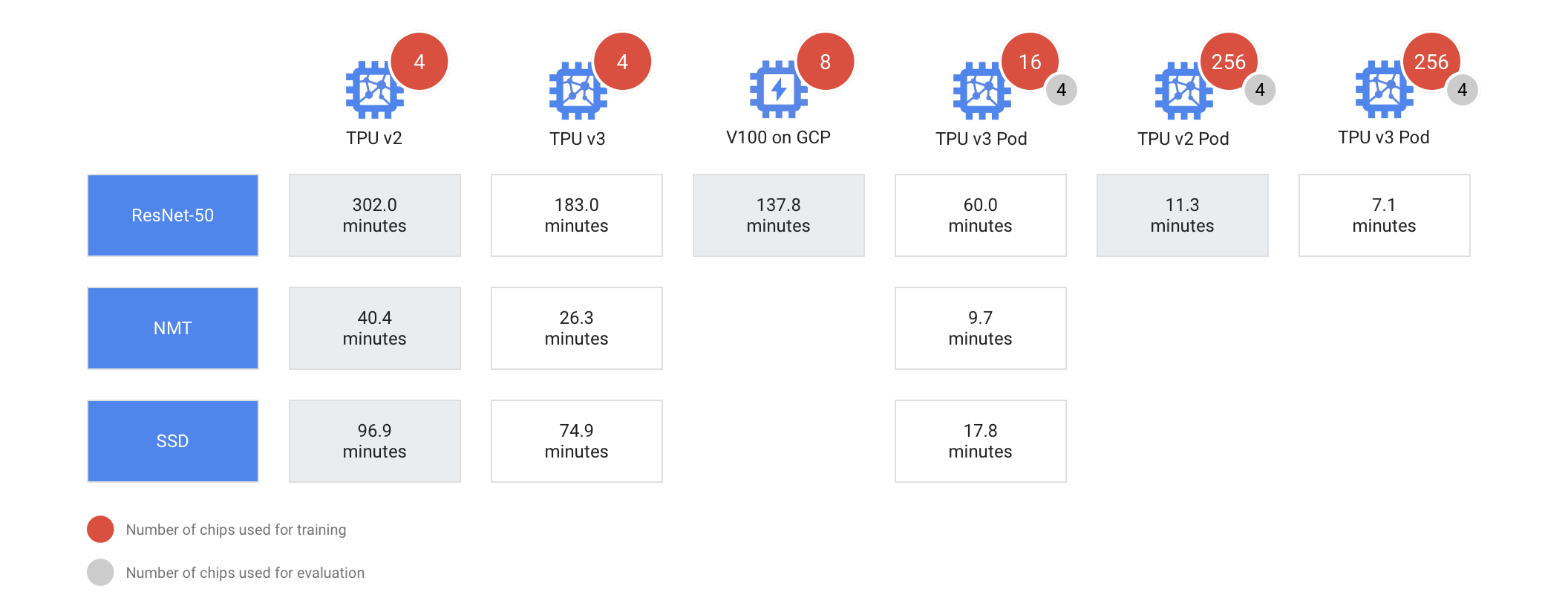
TPU v2のポッドはコア数が最大512で、v3よりやや遅い。例えば、265基のTPUを使用した場合、v2のポッドはResNet-50のモデルを11.3分で訓練するが、v3ならわずか7.1分だ。ちなみにTPUを1個だけ使うと302分かかるだろう。
当然だが、Googleによればポッドは(料金がどんなに高くても)モデルを早く訓練したいときや、ラベル付きの標本が数百万という大きなデータセットで高い正確性が必要、あるいは新しいモデルのプロトタイプを素早く作りたい、といったユースケースに向いている。


[原文へ]
(翻訳:iwatani、a.k.a. hiwa)