LinkedInが今日(米国時間3/3)、WhereHowsをオープンソース化した。WhereHowsは主に同社の社員が、同社が生成するデータを見つけ、また同社のさまざまな内部的ツールやサービスで使われているデータ集合の出自を調べるために使っている、メタデータツールだ。
今では多くの企業が毎日のように大量のデータを作り出しているから、それらの情報のフローを全社的に管理することがほとんど不可能になっている。データウエアハウスに保存するのはいいけれども、結局のところ、同じようなデータ集合が大量に集積したり、元のデータ集合のいろんなバージョンが散乱したり、いろんなツールで使うためにデータ集合がさまざまに変形されていたりする。まったく同じデータが、名前やバージョンを変えて複数のシステムにあることもある。だからたとえば新製品開発をこれから始める、というとき、あるいは単純に役員が見るためのレポートを作ろうとするとき、どのデータ集合を使えばよいのか、よく分からないことが多い。
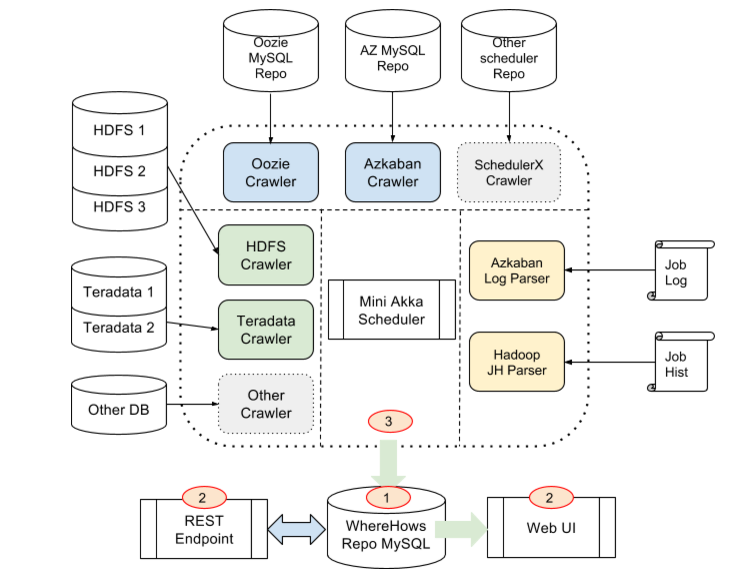
LinkedInのShirshanka DasとEric Sunによると、同社もまさしく、この問題に直面していた。そこで彼らは、WhereHowsを開発した。それは、LinkedInのような大きな企業で、データに何が起こっているかを常時追跡するための、中央的リポジトリ兼Webベースのポータルだ。今では中小企業ですら、大量かつ雑多なデータの整理や管理に悩まされているだろう。LinkedInでは、WhereHowsが現在、約5万のデータ集合と14000のコメントと3500万のジョブ実行の、ステータスに関するデータを保存している。それらのステータスデータは、約15ペタバイトもの情報に対応している。
LinkedInはHadoopの大ユーザーだが、このツールはほかのシステムのデータも追跡できる(Oracleデータベース、Informatica、などなど)。
WhereHowsはAPIとWebの両方でアクセスできるから、社員たちはデータ集合の出自や由来を視覚化したり、注釈を加えたり、いろんなことができる。
DasとSunによると、LinkedInは、そのサービス本体に属していないプロダクトをこれまでも長年、オープンソース化してきた。その基本的なねらいは、会話を喚起することだ。ビッグデータの大きなエコシステムがあれこれのツールを採用すると、同社もそのことで結果的に得をする。これまでぼくが取材してきた多くの企業と同様に、LinkedInでも、オープンソースが同社の技術のブランドイメージを高め、すぐれた人材の獲得を容易にするのだ。