
SAPとの提携に引き続きGoogle Cloud Nextからのニュースだ。今日(米国時間3/8)、サンフランシスコでスタートしたカンファレンスでGoogleは新しい機械学習APIを発表した。このAPIはビデオ中の対象を自動的に認識し、検索可能にする。
新しいVideo Intelligence APIを利用するとデベロッパーは ビデオから対象物を自動的に抽出する能力を備えたアプリを開発できる。これまで画像認識APIはクラウド・サービスでのみ利用でき、しかも多くは静止画だけを対象にしていた。しかしGoogleのAPIを使えばデベロッパーはユーザーがビデオを検索して情報を引き出すようなアプリを開発できる。つまりflowerやdogなどのキーワードでビデオを検索できるようになる。
ビデオ中のエンティティの抽出に加えて、このAPIはシーンの転換を認識し自動的なタグづけを可能にする。
ただしビデオそのものはGoogleクラウドに保管されている必要がある。こちらでデモを見ることができる。

Google CloudのAIおよび機械学習担当チーフ・サイエンティストのFei-Fei Liのキーノート講演によれば、画像処理は静止画の先へ進みつつあるという。ビデオは機械学習の開発者にとって長らく困難なターゲットだった。新しいAPIは静止画の画像認識同様んび簡単にビデオから情報を引き出すことを可能にする。
さらにGoogleのクラウド機械学習エンジンはTensorFlowフレームワークを用いてデベロッパーが独自のカスタム機械学習モデルを構築できるようにする。Gogleによればこのエンジンは今日、一般に公開された。
キーノートでLiは、Googleは「社内で開発した機械学習テクノロジーの一般への普及を図っている。 今回もVision APIの公開もその例だ」と述べた。
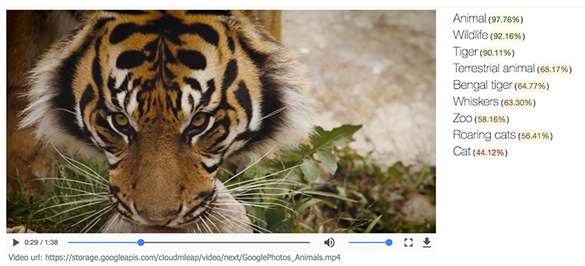
〔日本版〕Googleが用意した説明ページのデモでは動物園、Google本社の自転車などを撮影したサンプルビデオにAPIを適用して処理した結果を見ることができる。APIの利用例のサンプルコードも掲載されている。

[原文へ]
(翻訳:滑川海彦@Facebook Google+)