
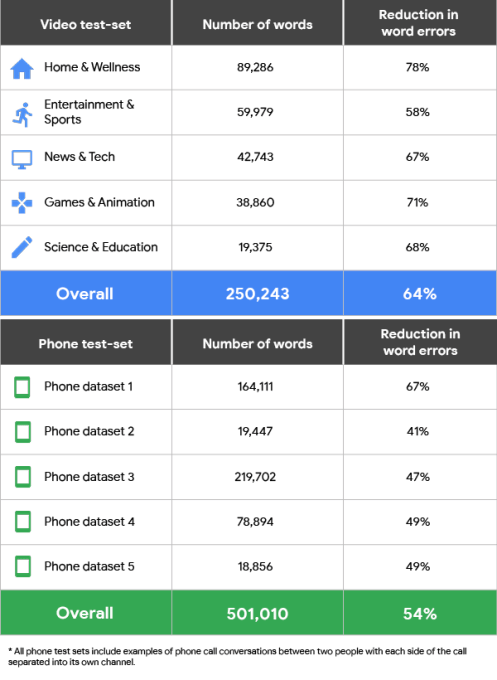
今日(米国時間4/9)、Googleは数週間前に公開したクラウド・テキスト音声変換サービスのAPIにメジャーアップデートを行ったことをを発表した。Googleは同時に逆方向のサービスである音声テキスト変換のクラウド音声認識APIにも大きな改善を行った。Googleのテストによれば、新しいAPIは認識エラーを全体で54%減らしたという。ただし一部のケースでは改善はこれをはるかに上回った。
アップデートされた音声テキスト変換APIを利用するとデベロッパーは 複数のユースケースをベースにした機械学習モデルから適したものを選ぶことができる。新APIは現在4つのモデルを提供している。そのひとつは検索と命令のための短い発話だ。また電話の音声認識、ビデオファイルの音声認識も提供されており、Googleがすべてのデベロッパーにデフォールトとして推薦するのが4番めの新しいモデルだ。
こうした新しい音声テキスト変換モデルに加え、Googleはパンクチュエーション(句読法)のモデルをアップデートした。Googleの開発チーム自身も認めているとおり、音声認識でこれまで最大の問題となってきたのは正しいパンクチュエーションの生成だった。ことに話者が通常と異なる発話の癖を持っている場合、パンクチュエーションを含めたテキスト起こしはきわめて困難になる
これはトランプ大統領の発言をパンクチュエーションを含めてテキスト起こししようと試みたデベロッパーなら同意するだろう。アップデートされたモデルははるかに読みやすいテキストを生成できるという。センテンスの切れ目を認識することに失敗するケースが減少し、ピリオド、コンマ、クエスチョンマークなどを正しく挿入できるとGoogleは述べている。
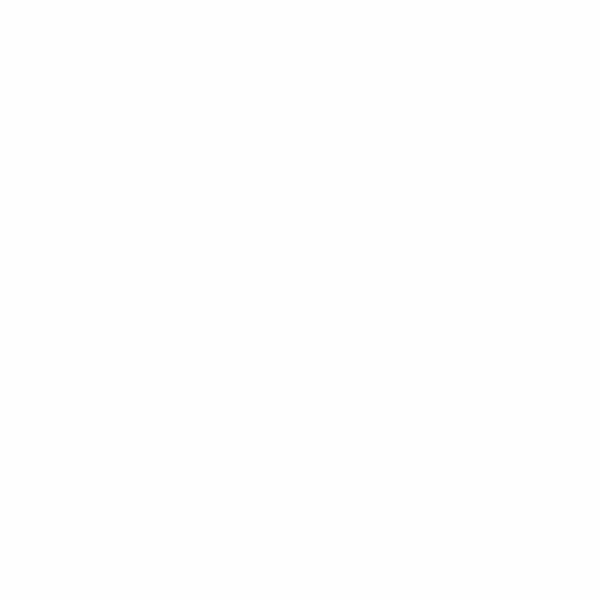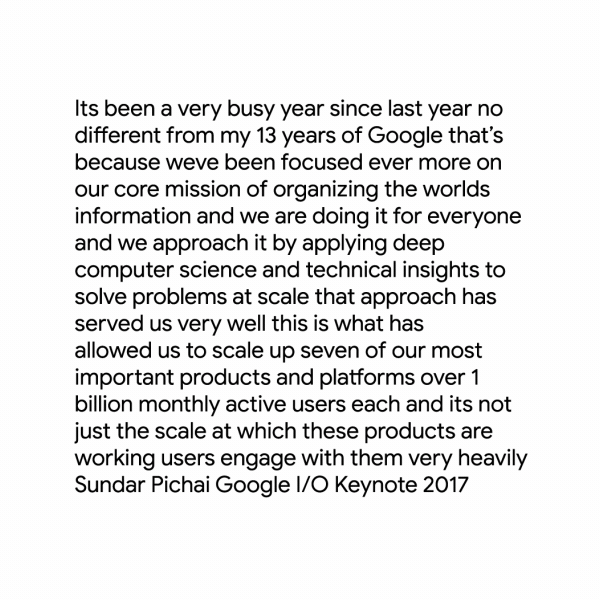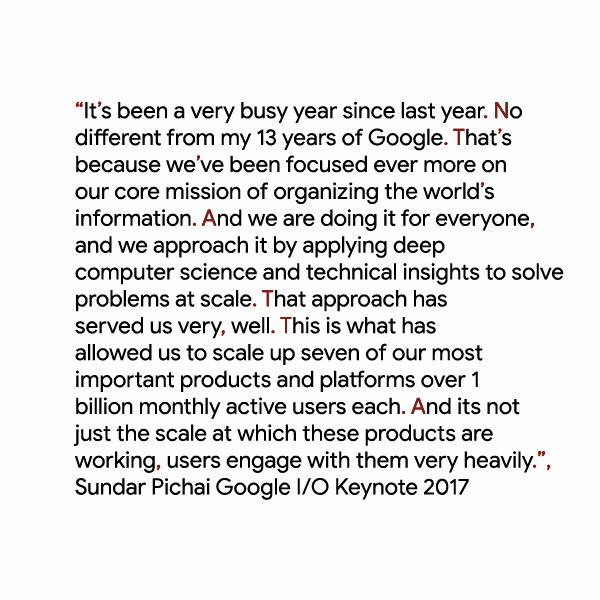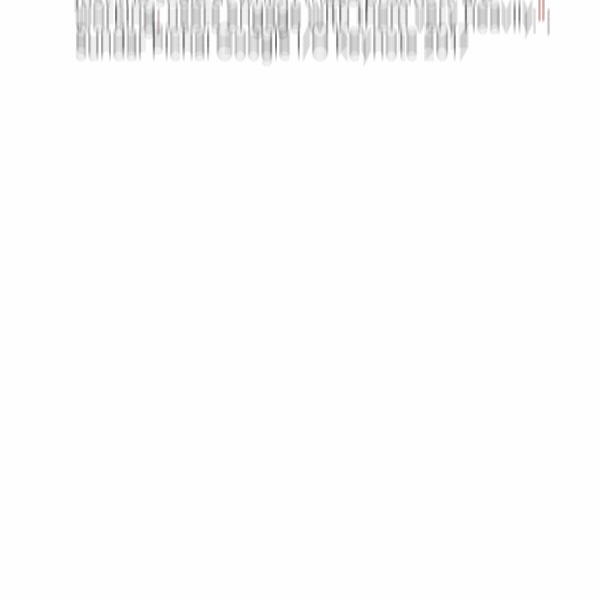
今回のAPIのアップデートにより、デベロッパーはテキスト起こしを行うことにより、音声ファイルないしビデオファイルにタグ付けなど基本的なメタデータを付与できるようになった。Googleではユーザーの各種機能の利用状況を総合的に勘案して、次のアップデート開発の優先順位を決めていくという。
Googleはサービスの料金体系も多少変更した。従来どおり、音声ファイルのテキスト変換は15秒ごとに0.006ドルで、ビデオはその2倍の15秒ごとに0.012ドルとなる。ただし5月31日まで新モデルの利用料金は15秒ごとに$0.006ドルに抑えられる。
〔日本版〕上にエンベッドされた例ではセンテンスの切れ目が正しく認識されピリオドが挿入されている。No、That’sなどの冒頭が赤文字で強調表示されている。
[原文へ]
(翻訳:滑川海彦@Facebook Google+)