今日(米国時間10/19)Googleが、ビデオの中で行われている人間のアクションを集めてそれぞれにラベルをつけたデータセットを発表した。何のことだかよく分からないかもしれないが、実はこれは、コンピュータービジョンの問題解決に今後大きく貢献するデータ集合なのだ。
最近では、人間の第二の目になってくれる製品やサービスが大きく成長している。ビデオの中の特定の映像を見つけるMatroidや、Lighthouseのようなセキュリティシステム、それに自動運転車でさえ、ビデオの中で起きていることが理解できると大いに助かる。そしてその理解は、良質なラベル付きデータによる訓練やテストに負っている。
GoogleのAVAはatomic visual actions(最小単位…不可分…の視覚的アクション集)の頭字語だ。そのほかのデータセットと違ってそれは、アクションデータとして使えるシーンの中に複数の区切りを設けて、それぞれにラベルを付ける。つまりひとつのシーンがマルチラベルだ。これにより複雑なシーンの細部を捕捉でき、機械学習のモデルの精度を上げる。
Googleのブログ記事は、人間のアクションの分類(〜把握理解)が困難である理由を詳細に述べている。アクションは静的オブジェクトではないので、時間の上に繰り広げられる。したがって、不確実性が多くなる。誰かが走っている映像は、さらにその後のフレームを見るとランニングではなくて実はジャンプだったりする。一つのシーンの中に二人の人間のからみがあると、その理解はさらに複雑だ。
AVAには、ビデオの断片が57000あり、人間に付けられたラベルが96000、ラベルの総数は21万になる。ビデオの断片はYouTube上の公開ビデオから取られ、一片の長さが3秒だ。歩く、蹴る、ハグするなどアクションのタイプを80種用意し、手作業でラベルをつけていく。
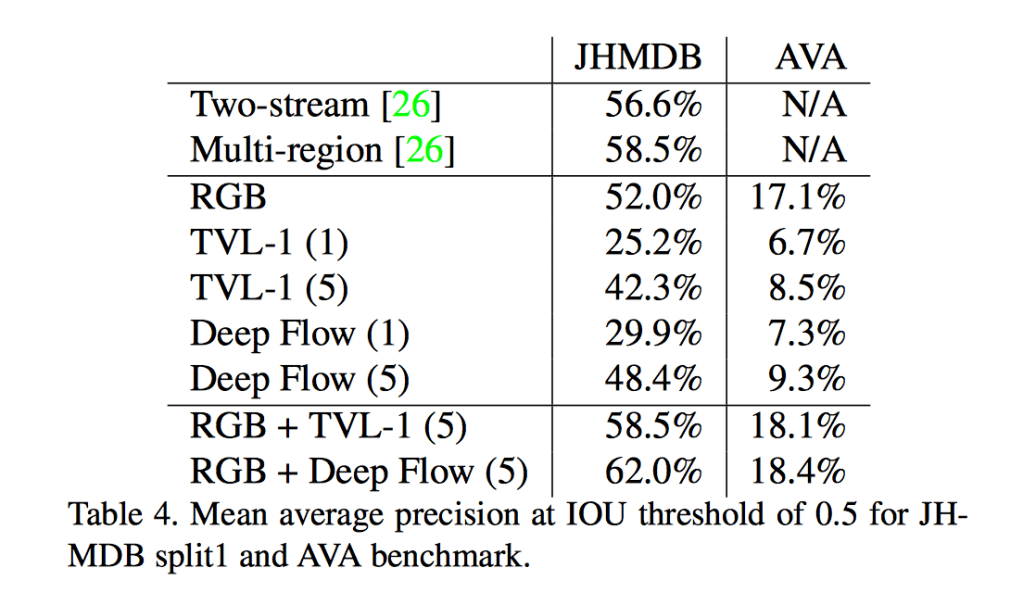
試してみたい人は、完全なデータセットがここにある。AVAに関するペーパーは最初、5月にarXivに発表され、7月にアップデートされた。そこに紹介されている実験では、Googleのデータセットが既存の分類テクニックにとって極めて難しいことが示されている。下表は、前からあるJHMDBデータセットと、新しいAVAデータセットのパフォーマンスを比較している。