
Googleのグローバルな分散リレーショナルデータベースCloud Spannerが今日(米国時間12/19)、新しいリージョンと、複数のリージョンにまたがる構成をセットアップする方法により、さらにその分散性を高めた。またデベロッパーがリソースをもっとも消費するクエリを調べる方法も、加わった。
このアップデートでCloud Spannerの最新のデータセンターとしてHong Kong(asia-east2)が加わる。これによりCloud Spannerを、Google Cloud Platform(GCP)の18のリージョンのうち14で使えるようになる。そのうち7つは、今年加えたリージョンだ。今後の新しいGCPのリージョンでも、それらがオンラインになり次第、Cloud Spannerを可利用にしていく予定だ。
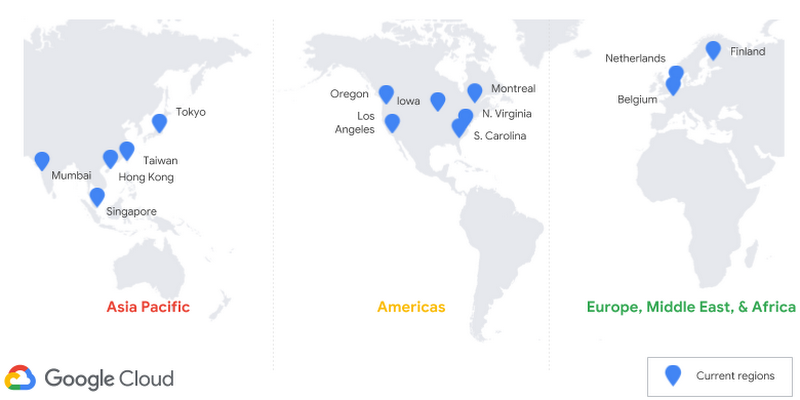
リージョンに関連したそのほかのニュースとして、マルチリージョンをカバーするための二つの新しい構成がある。ひとつはeur3と呼ばれ、欧州連合(European Union, EU)を対象とする。言うまでもなくこの地域の顧客にサービスを提供するユーザーが対象だ。もうひとつはnam6と呼ばれ、北米(North America)が対象で、データセンターはオレゴン、ロサンゼルス、サウスカロライナ、アイオワに置かれる。これまでのマルチリージョン構成は、三つのリージョンにまたがる北米地区と、北米、ヨーロッパ、アジアにまたがるグローバルな構成だけだった。
Cloud Spannerはもちろんグローバルなデプロイメントを想定しているが、これらの新たな構成により、特定の市場だけを対象とするサービス用にも利用できる
クエリに関する新しい機能としては、Cloud Spannerはデベロッパーがクエリを見る、調べる、そしてデバッグできるようになる。その目的は主に、デベロッパーが頻度の高い高価なクエリ詳しく調べられるようになることだ。その結果、それらをもっと安価なクエリに変えられるかもしれない。
Cloud Spanner以外のニュースでは、Google Cloudは今日、Cloud Dataproc Hadoop とSparkサービスが新たにR言語をサポートすることを発表した。ほかにはApp Engineが前から、Python 3.7をサポートしている。