
今日(米国時間11/1)はMicrosoft Researchが、自然言語処理における“知識”という問題の、解へ向かう努力の一環を公開した。同社によると、言葉に対する人間の理解とコンピューターの理解を分かつ最大の要因が、背景的知識とその正しい活用方法の有無だ、という。
Microsoftがこれまで年月をかけて開発してきた知識データベースProbaseが、今度一般公開されるMicrosoft Concept Graphのベースになっている。Probaseは540万の概念を擁し、12万の概念を擁するCycなど、他の知識データベースを圧している。
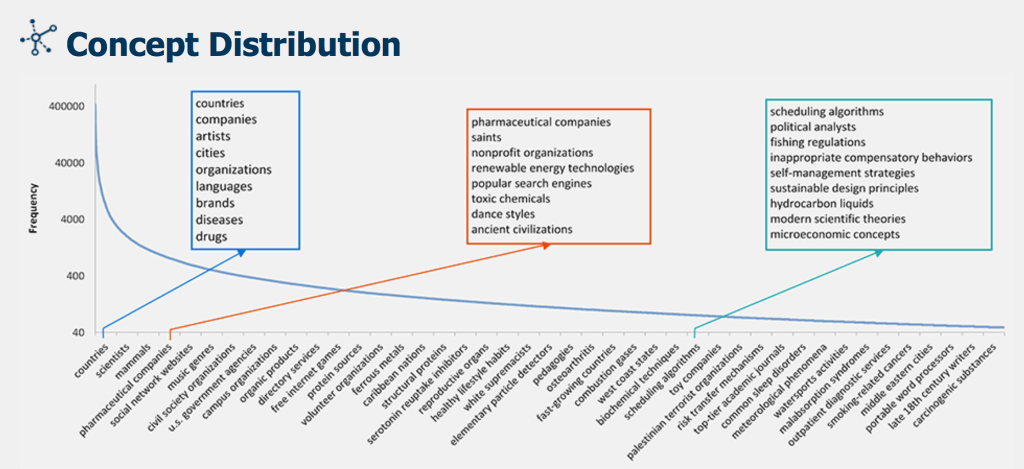
Microsoft ResearchのConcept Graphにおける概念の分布
情報が上図のようにすべて結び付けられ、それが、確率付きの解釈と共にテキストの分析を支える。複数の解釈を確率により排除していくやり方は、人間が、「これはないな、あれはないな」と素早く排除しながら自分の結論に達するやり方と、非常によく似ている。
たとえば私が“the man ran from the stranger with the knife”と言えば、あなたなら、男が武装した見知らぬ人から走って逃げている、と解釈するだろう。でもこの文には、男がナイフを手に持って見知らぬ人から走って逃げている、解釈もありうる。しかしながら、(1)〜〜から走って逃げる、は恐怖を含意し、(2)ナイフは恐怖に結びついている、という知識(カテゴリー知識)があれば、あなたの最初の、もっとも単純でストレートな解釈が、いちばん優勢(高確率)になるだろう。それが間違っていた可能性も、あるにはあるけど。
MicrosoftのConcept Tagging Model(概念にタグ付けする方式)は、このことを利用して、テキストのカテゴリーをそれと同じ確率の考えに結びつける。上の例では、ナイフは家庭用品や武器も指すが、しかし文脈としては武器である確率が高く、博物館から盗まれた17世紀のバターナイフではないだろう。
家庭用品や武器は、比較的よくあるカテゴリーだが、博物館の美術工芸品はかなりロングテールだ。Microsoftの大規模なモデルでは、確率の高いものと、極端にありえないものの両方を検討し、その際、属性や下位の文脈、関係などを考慮に入れていく。
今日リリースされたバージョンは、入力されたテキストのありうるカテゴリーのランク(確率ランク)を作る。Microsoftのそういう、初等レベルの概念化能力は、MI, PMI, PMIk, 典型性(Typicality)など他の方法とともに、選好ランクの生成や、適切なカテゴリー付けに利用されるだろう。
今後のバージョンは、彼らの言う“単一インスタンスの文脈付き概念化”の能力を持つだろう。それは、“見知らぬ人”と“ナイフ”を結びつけて、意味を示す。さらに将来的には、チームは“短文の概念化”能力を実現したい、と考えている。それにより、検索や広告やAIにおいて、アプリケーションの視界をさらに拡大するだろう。