
まあ、パニックになる必要もないけど、今やコンピューターが自分たちの秘密の言語を作って、たぶんまさに今、われわれについて話しているんだ。ちょっと話を単純化しすぎたし、最後の部分はまったくのフィクションだけど、GoogleのAI研究者たちが最近、おもしろそうで、しかも人間にとって脅威になるかもしれない、事態の進展に、遭遇しているんだ。
憶えておられると思うが、Googleは9月に、同社のNeural Machine Translation(ニューラルネットワークによる機械翻訳)システムが稼働を開始したと発表した。それは、ディープラーニングを利用して複数の言語間の翻訳を改良し、より自然な翻訳にする、というものだ。そのこと自体はクールだが…。
これの成功のあと、その翻訳システムの作者たちは、あることが気になった。翻訳システムに、英語と韓国語双方向と、英語と日本語双方向の翻訳を教育したら、それは韓国語を日本語へ、あいだに英語を介さずに翻訳できるのではないか? 下のGIF画像を見ていただきたい。彼らはこのような翻訳方式を、“zero-shot translation”(ゼロショット翻訳、分枝のない翻訳)と呼んだ(オレンジ色のライン):
そして — その結果は!、明示的なリンクのない二つの言語でありながら、まあまあの(“reasonable”)翻訳を作り出したのだ。つまり、英語はまったく使っていない。
しかしこれは、第二の疑問を喚起した。形の上では互いにリンクのない複数の概念や語のあいだの結びつきをコンピューターが作れるのなら、それは、それら複数の語で共有される意味、という概念をコンピューターが作ったからではないのか? 一つの語や句が他のそれらと同じ、という単純なレベルではなく、もっと深いレベルで。
言い換えると、コンピューターは、言語間の翻訳に自分が用いる概念(共有される意味概念)を表現する独自の内部的言語を開発したのではないのか? ニューラルネットワークの記憶空間の中では、さまざまなセンテンスがお互いに関連し合っているのだから、その関連の様相から見て、言語とAIを専門とするGoogleの研究者たちは、そうだ、と結論した。
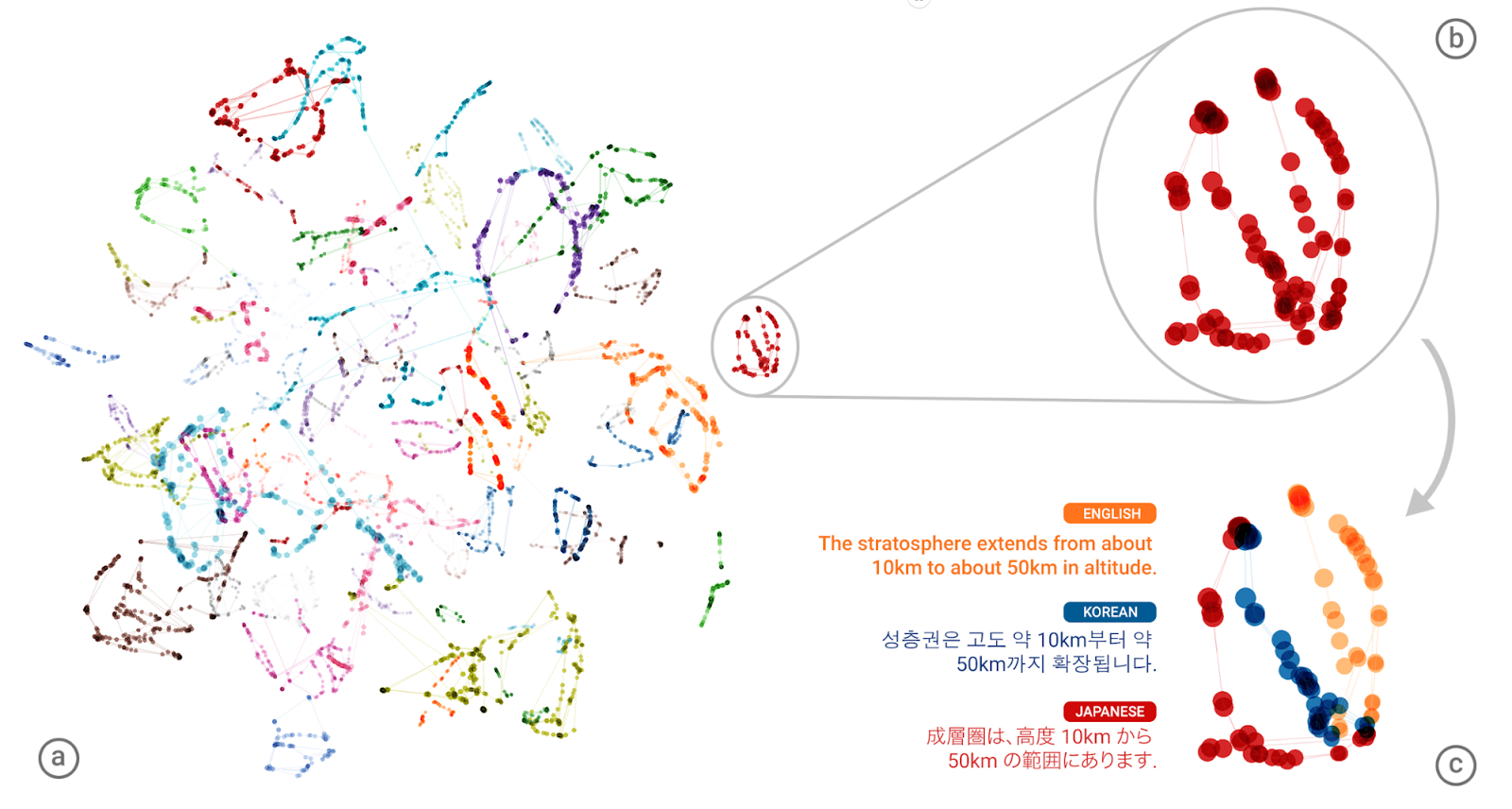
翻訳システムの記憶の視覚化: 一つのセンテンスを複数方向へ翻訳している
この中間言語(“interlingua”)は、日・韓・英の三言語の文や語の類似性を表している表現の、ずっと深いレベルに存在しているようだ。複雑なニューラルネットワークの内部的処理を説明することはおそろしく難しいから、今これ以上のことを言うのは困難だ。
非常に高度なことをやってるのかもしれないし、あるいは、すごく単純なことかもしれない。でも、それがとにもかくにもある、という事実…システムが独自に作ったものを補助具として使って、まだ理解を訓練されていない概念を理解しようとしている…もしもそうなら、哲学的に言ってもそれは、すごく強力な‘才能’だ。
その研究論文は、Arxivで読める(効率的な複数言語翻訳に関する論文だが、謎のような中間言語にも触れている)。システムが本当にディープな概念を作ってそれを利用しているのか?、この疑問への答は今後の調査研究の課題だ。それまでは、最悪を想定していよう。