
Google CloudのText-to-SpeechとSpeech-to-Text APIが今日(米国時間8/29)、大量のアップデートを行い、サポートする言語を増やし、いろんなスピーカーからの自動生成音声を聴きやすくし、スピーカーの音声認識ツールを改良してテキスト書き起こしの精度を上げる、などの機能向上を導入した。
このアップデートにより、Cloud Text-to-Speech APIが一般的に可利用になった。
多くのデベロッパーにとっていちばん魅力的なのは、17の新しいWaveNetベースの音声が複数の新しい言語でローンチしたことだろう。WaveNetはGoogle自身の技術で、機械学習を使ってテキスト読み上げのオーディオファイルを作る。その結果、より自然に聞こえる音声になった。
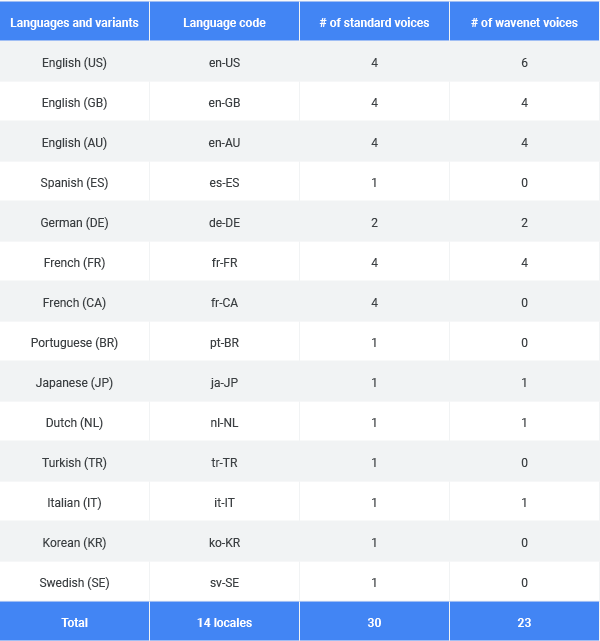
このアップデートで、Text-to-Speech API(テキスト読み上げAPI)は今や14の言語とそれらの変種をサポートし、標準音声30とWaveNetの音声26を揃えている。
ここへ行くと、今回加わった新しい音声も含め、自分のテキストでGoogleのデモを試すことができる。
新しい機能の中では、オーディオプロフィールもおもしろい。これは、再生するメディアに合わせてオーディオファイルを最適化する機能だ。たとえば、スマートフォンのスピーカーとテレビの下にあるサウンドバーでは、音が違うだろう。オーディオプロフィールを使うと、音声を、電話の通話やヘッドフォンやスピーカーなどなどに合わせて最適化できる。
[元の音声と最適化の結果]

Speech-to-Text(書き起こしAPI)の方では、複数のスピーカーからの音声をより正しく書き起こせるようになった。機械学習を使っていろんなスピーカーを認識し、ひとつひとつの語にスピーカー番号のタグをつける(スピーカーの数は人間が指定する)。たとえばスピーカー2つのステレオファイルなら、それぞれの言葉の出どころを区別できるし、怒った顧客がカスタマーサポートに電話をしている音声なら、やはり各語の話者を識別できる。
複数言語のサポートも、新しい。検索には前からあったが、これからはそれをデベロッパーが利用できる。この書き起こしAPIに対しては、最大で4つの言語を指定できる。するとAPIは、今どの言語が喋られているかを、自動的に聞き分ける。
さらに、Speech-to-Text APIは、単語のレベルでの自信点を返す。すでに個々の談話レベルの自信点はあったが、今度からはデベロッパーは単語レベルのアプリ構築ができる。たとえば、“please set up a meeting with John for tomorrow at 2PM”(明日の午後2時にジョンとのミーティングをセットアップしてくれ)に対して‘John’や‘2PM’の自信度が低ければ、ユーザーにそれらを二度繰り返させるアプリを書けばよい。‘please’の自信度が低くても、それは重要でない単語だから、そのままでよい。Googleのチームは、そう説明している。