毎日、多くのユーザーが Google を利用して企業について検索しています。カスタマー サービス用の電話番号や、住所、営業時間などがよく検索されるものです。
このような情報は、通常、会社のウェブサイトの「お問い合わせ」ページに記載されています。Google が正確にそれらの「お問い合わせ」ページを発見し、適切な情報を抽出することができた場合、その情報がユーザーに伝えられる可能性は高まります。 この情報を Google に理解させ、表示させるために推奨される方法を今日は紹介します。
現在、様々な企業の電話番号が Google 検索結果に大きく表示されています。例えば、Nest Labs のカスタマー サービス用電話番号を検索すると、以下のように表示されます(現在のところ google.com でのみご確認いただけます)。

本日、あなたのサイトに埋め込む構造化データ マークアップを利用して、表示させたい電話番号を指定する schema.org マークアップのサポートを開始しました。サポートされる電話番号の種類は、以下のようなものです:
多くのユーザーが、Google を利用してさまざまな店舗を検索しています。多くの場合、最良の情報はウェブサイトのお問い合わせページや、支店リスト ページで見つかります。これらのページには、住所や電話番号、営業時間などが含まれています。

このようなページをユーザーにとっても Googlebot にとっても理解しやすいものにするために推奨される方法 (英語) も本日発表いたします。ここには、クローリング、インデックス登録、デザインに関する推奨事項、そして Google により正確にそのページをインデックスさせるための新しい構造化データ マークアップに関するガイドラインが掲載されています。
また、Google Maps やナレッジグラフ、AdWords キャンペーンなどの Google のサービスに対して店舗の情報をアップデートするためのツールであるビジネス オーナー向けプレイスを利用することも引き続き推奨されています。
なにかご質問がありましたら、ウェブマスター ヘルプ フォーラムをご利用ください。
このような情報は、通常、会社のウェブサイトの「お問い合わせ」ページに記載されています。Google が正確にそれらの「お問い合わせ」ページを発見し、適切な情報を抽出することができた場合、その情報がユーザーに伝えられる可能性は高まります。 この情報を Google に理解させ、表示させるために推奨される方法を今日は紹介します。
企業の電話番号
現在、様々な企業の電話番号が Google 検索結果に大きく表示されています。例えば、Nest Labs のカスタマー サービス用電話番号を検索すると、以下のように表示されます(現在のところ google.com でのみご確認いただけます)。
本日、あなたのサイトに埋め込む構造化データ マークアップを利用して、表示させたい電話番号を指定する schema.org マークアップのサポートを開始しました。サポートされる電話番号の種類は、以下のようなものです:
- カスタマー サービス
- テクニカル サポート
- 決済サポート
- 支払い
店舗サイト向けの推奨
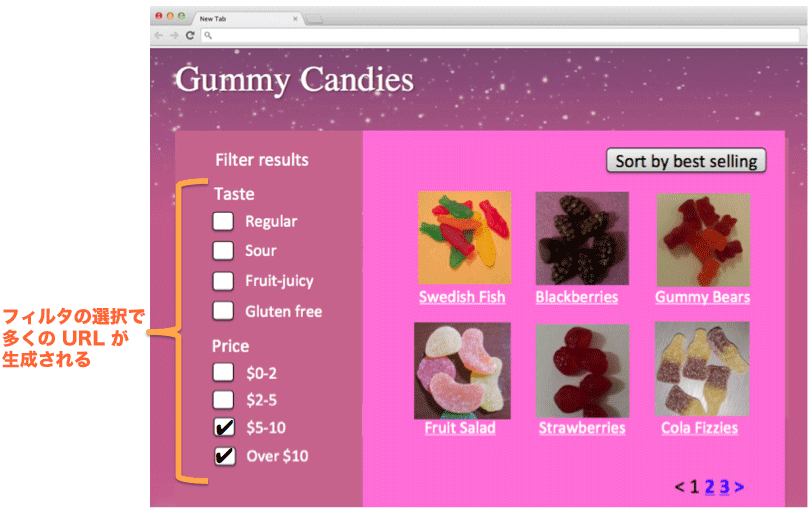
多くのユーザーが、Google を利用してさまざまな店舗を検索しています。多くの場合、最良の情報はウェブサイトのお問い合わせページや、支店リスト ページで見つかります。これらのページには、住所や電話番号、営業時間などが含まれています。
このようなページをユーザーにとっても Googlebot にとっても理解しやすいものにするために推奨される方法 (英語) も本日発表いたします。ここには、クローリング、インデックス登録、デザインに関する推奨事項、そして Google により正確にそのページをインデックスさせるための新しい構造化データ マークアップに関するガイドラインが掲載されています。
また、Google Maps やナレッジグラフ、AdWords キャンペーンなどの Google のサービスに対して店舗の情報をアップデートするためのツールであるビジネス オーナー向けプレイスを利用することも引き続き推奨されています。
なにかご質問がありましたら、ウェブマスター ヘルプ フォーラムをご利用ください。