
【編集部注】著者のOphir Tanzは、GumGumのCEOである。GumGumはコンピュータービジョンの専門知識を持つ人工知能企業で、広告からプロスポーツに至る世界中のさまざまな分野にAI技術を応用しようとしている。カーネギーメロン大学で学士・修士の学位を修めたTanzは、現在ロサンゼルスに住む。
id SoftwareのJohn Carmackが、1993年にDoomをリリースしたとき、彼はその血なまぐさいファーストパーソン・シューティングゲーム(1人称視点でのシューティングゲーム。最初に3D環境を採用したものの1つであり、あっという間に人気作になった)が、その後の機械による情報処理を、如何に変えてしまうかには全く自覚がなかった。
その6年後にはNvidiaが、急成長するゲーム業界向けに、3Dグラフィックスの生成に特化した、初めてのグラフィックプロセッシングユニット(GPU)であるGeForce 256をリリースした。それから17年。GPUはその開発の元々の動機であったハイエンドゲームだけではなく、人工知能(AI)の大きな進歩のための原動力ともなっている。
より強力なGPUの誕生により、深層機械学習とニューラルネットワークは、私たちが関わる仕事や運転する車から、医者に行ったときに受ける診断までの、およそ全ての社会的様相を変えようとしている。
私たちがこれまでに書いた「数学抜きのニューラルネットガイド」の第1回(数学知識もいらないゼロからのニューラルネットワーク入門)と第2回(Why the Future of Deep Learning Depends on Good Data――深層学習の未来が良いデータに依存している理由)では、深層学習がどのように機能しているのか、そして何故AIの成功にはデータが重要なのかについて、それぞれ解説を行った。シリーズの第3回となる今回は、今日の深層学習ブームの先導に役立っている処理系の開発に焦点を当てる。まずは、GPUとCPUの仕組みの違いを理解することが役立つ。
GPUとCPU
今なら読者も既に「中央処理装置」あるいはCPUという用語には馴染みがあるだろう。これはコンピューターの中にある頭脳である。コードを読み込んで、数の計算からHDビデオの再生、そして様々なプログラムを、淀みなく一斉に実行してくれるものだ。あのしつこかった「インテル入ってる」マーケティングキャンペーンを覚えているだろうか?あれはCPUのことを宣伝していたのだ。
しかし、CPUがコンピューターの唯一の頭脳ではない。マシンの中には、特定のタスクに対してはCPUよりも優れた性能を発揮する機構が抱えられているのだ。そうしたものの中で、最も重要なものがグラフィックスプロセッシングユニット(GPU)だ。これらのチップは、いくつかの点ではCPUに似ているものの、その他の点では大きく異なる。
最新のCPUの多くは、その内部に2〜8個の「コア」(本質的にはミニCPU)を持っていて、それぞれが同時に異なる操作を処理することができる。これらのコアは、投入されたどのような命令でも処理することができ、お互いにシームレスに切り替えることができる。このため、ビデオを見ながらソフトウェアをダウンロードし、同時に、特に引っかかりも感じずに親友たちとSnapchatを楽しむこともできるのだ。
野球のボール、ボウリングのピン、斧、りんご、卵などを同時にジャグリングするサーカスのパフォーマーを想像してみて欲しい。非常に目まぐるしく、彼はリンゴをかじりながら、斧を置いて火の付いた松明を拾い上げる。これがCPUである。要するに一度に様々な仕事をこなすことのできる何でも屋だ。

これとは対照的に、最新のGPUは数千ものコアを持っているが、そのデザインは遥かにシンプルだ。それぞれのコアは特定の1つの仕事しかできないが、しかし集団としてその仕事を、正確に同時に、何度も繰り返し、非常に素早く行うことができるのだ。
GPUサーカスパフォーマーは、ボウリングピンしか扱うことができないが――その代わりに同時に1万本ものピンをジャグリングすることができる。一方CPUは、万能でなければならない上に、柔軟にマスチタスキングも行わなければならないために忙しく、そんなに大量のボウリングピンを一度に扱うことができない。
この性質は、たとえばゲーム環境の中で3Dグラフィックスを創りだすために数十億のポリゴンを生成するといった、膨大な繰り返し演算が必要な仕事を行なう場合に、GPUを圧倒的に優位なものとする。そして、膨大な量のデータに対して、何度も何度も同じ操作を繰り返さなければならないニューラルネットワークのトレーニングに対しても、GPUが理想的なものとなるのだ。
遊びの中のGPU
GPUは、毎秒数十億回の複雑な数学的計算を行うことで、その魔法を実現している。
ビデオゲーム環境は、小さな三角形で構成されている。それらは様々な方法で組み合わされて、スクリーンの上に表示される土地、空、山、宇宙船、怪物などを形作っている。それらの三角形は、それぞれ環境内での位置、他の三角形に対する角度、色、テクスチャなどを示す、異なる数字で構成されている。GPUはこれらの数値を取り込み、それを平たいディスプレイ上のピクセル(画面上の点)に変換する。画面がリフレッシュされるたびに、またはシーンが少しでも変化するたびに、GPUは新しいピクセルを生成するために計算を行わなければならない。これが、最終的にコール・オブ・デューティーやグランド・セフト・オートといったリッチな3Dゲーム環境を生み出している。
毎秒60フレームで動作するHDディスプレイの場合、GPUは一度に1億2000万ピクセルを生成する必要がある。このため非常に強力なCPUであっても、1つのフレームを描画するのに1〜2秒が必要となる。しかし、同時に実行される何千ものGPUコアに仕事を分割すれば、仕事はほぼ瞬時に終了する(こうしたプロセスは並列処理と呼ばれる)。

非常に雑なたとえだが、この違いはミケランジェロを雇って天井にフレスコ画を描かせることと、数千人の職人を雇ってそれぞれに天井の1平方インチのエリアを担当させることの違いのようなものだ。
2010年に、米国空軍が1760台のプレイステーション3をデイジーチェーンで接続して、スーパーコンピューターを作ることができたのも、このGPUの圧倒的な馬力のお陰だ。その当時、それは米国防総省の中で最も強力なコンピューターだったが、従来のスーパーコンピューターよりも90%以上安価であり、電力消費量も10分の1だった。
RAMの中の象
画像認識にGPUを使用するのは、逆方向の動作だ。数値を画像に変換する代わりに、画像を数値に変換するのだ。
たとえば数千のGPUで構成されたニューラルネットワークを構築したとしよう。それぞれGPUが数千のコアを持つそのネットワークは、本質的にスーパーコンピューターだ。今このスーパーコンピューターに、ゾウを識別する方法を教えたいと考えているとする。教師あり学習と呼ばれる方法を利用するならば、考えられるすべての角度から撮影された数十万の象の画像に「象」というラベルを貼って、ネットワークに供給するところから始めることになる。ネットワークは、各画像内のすべてのエッジ、テクスチャ、形状、そして色をマッピングして、そのラベルを有する画像と一致する数学的パターンを特定しようと試みる。

学習過程では、ネットワークが見るもの全てを象であると判断しないように、ゾウを含まない画像も投入することになる。これにより、ネットワークは徐々にモデルを調整し、全体的な精度を向上させることができる。ネットワークは各画像でこのプロセスを連続して行い、それぞれの新しいパス毎に象探索アルゴリズムを改良して行く。
そして出来上がったスーパーコンピューターに新しいイメージを入力すれば、そのイメージが象であるか否かが判断される。もしニューラルネットワークが間違った場合には、より多くのトレーニングで調整が行われることになる(バックプロパゲーションと呼ばれるプロセスである)。画像認識能力が向上しなくなったときが、訓練の終わるときだ。
ここで一番クールなのは以下の点だ:あなたはニューラルネットに対して、象というものは暗い灰色の肌、長い柔軟な鼻、丸みを帯びた背、そして太い脚を持っているものだ、ということを伝えたわけではない。伝えた事はただ「ここに『象』と呼ばれる大量のデータがあります。その共通の性質を把握しなさい」ということだけだ。実際には、ネットワーク自身が、象がどのように見えるかを、自分自身に教えたのだ。
大量計算兵器
GPUがニューラルネットワークの訓練に非常に優れている理由の1つは、行列乗算と呼ばれるものに優れているからだ。つまり、1つの数値テーブル(たとえば、画像のある部分のピクセル値)を別のテーブル(別の部分のピクセル値)と乗算するような演算に優れているということである。ニューラルネットワークは行列の乗算に大いに依存しているため、GPUを使用することで、場合によっては数カ月または数週間かかるトレーニング期間が、数日から数時間に短縮されることがある。
現代のGPUは多くのオンボードメモリを搭載するようになって来ているため、コンピューターのメインメモリとの間でデータを往復させることなく、計算処理を行うことが可能だ。これにより計算はさらに速くなる。またスケーラビリティも優れている。投入するGPUが多ければ多いほど、一度に処理できる計算量が増えるからだ。そしてそれらはプログラム可能なので、手書き文字認識や音声認識などの、さまざまなタスクを実行するようにプログラムすることができる。
ひ弱な人間たち
画像内の物体を認識する際に、GPU駆動のニューラルネットにはどれくらいの性能があるのだろうか?実はそれらは既に人間よりも優れているのだ。2015年には、GoogleとMicrosoftの両者が、毎年恒例のImageNetコンピュータービジョンチャレンジの中で、画像の中の物体の認識能力において、人間よりも正確な深層ニューラルネットを発表している。グラフィックスチップメーカーのNvidiaは、GPUを使ったニューラルネットのトレーニング速度が、わずか3年で50倍になったと主張している。
GPUがそれほどまでに急速に進歩した理由は――お金のためだ。昨年世界中で、ビデオゲームは1000億ドルの売上を果たした――これは映画、音楽、書籍を合わせたものよりも多い額である。ゲームの驚くべき収益性が、GPUやその他のテクノロジーへの研究開発への多大な投資を可能にしたのだ。昨年 Nvidiaは1つのGPUの開発に20億ドル以上を費やした。そのGPUは深層ニューラルネット専用に作られたものである。一方Googleやその他の企業は新しい「Tensorプロセッシングユニット」に取り組んでいる。これもニューラルネット専用に設計され、より多くのデータを効率的に扱うことができるものだ。
こうした投資は、ビデオゲームをはるかに超えた様々な領域で回収されることになる。Googleは、GPUを使ったニューラルネットを使用してAndroidでの音声認識を行い、Googleマップ上の外国語の道路標識の翻訳を行う。Facebookはそれらを使ってあなたの友人たちの顔を認識し、あなたのニュースフィードをカスタマイズする。ニューラルネットは、運転手のいない車の中でのインテリジェンスを提供し、木と一時停止標識の識別を行なう。またそれは、診断医がMRIの中の腫瘍と健常組織との違いを見分ける手伝いをして、癌の早期兆候の検出にも役立つ。そしてそれは原子力発電所の部品に入った亀裂を見つけることも可能だ。
そしてまた、スーパースマッシュブラザーズのプレイがかなり得意だ。
いつか、GPUを使うディープニューラルネットによって可能になった発見が、あなたの命を救う日が来るかもしれない。それは皮肉にも、最初のファーストパーソン・シューティングゲームの副産物なのだ。
[原文へ]
(翻訳:Sako)

 ニューラルネットを利用した新しいアルゴリズムは双方向エンコーダーによる変形生成、「Bidirectional Encoder Representations from Transformers」あるいは、セサミストリートの有名なキャラにかけて頭文字でBERT(バート)と呼ばれる。同社は昨年BERTによるモデル化の実装をオープンソース化して公開している。 変形生成(Transformers)というはもっと最近開発された機械学習テクノロジーで、データ要素間にシーケンシャルな関連がある場合に特に有効だという。自然言語による質問を解析する場合に効果があることは当然だ。
ニューラルネットを利用した新しいアルゴリズムは双方向エンコーダーによる変形生成、「Bidirectional Encoder Representations from Transformers」あるいは、セサミストリートの有名なキャラにかけて頭文字でBERT(バート)と呼ばれる。同社は昨年BERTによるモデル化の実装をオープンソース化して公開している。 変形生成(Transformers)というはもっと最近開発された機械学習テクノロジーで、データ要素間にシーケンシャルな関連がある場合に特に有効だという。自然言語による質問を解析する場合に効果があることは当然だ。

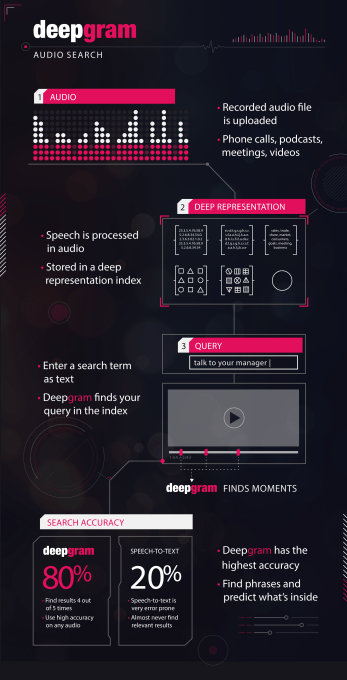 創業者たちによれば、このオーディオ検索テクノロジーは、自然言語処理に依存している他の技術とは相当に異なっているものだということである。「私たちは、モデルが通話の違いを区別できるように訓練しています」と、Stephensonはインタビューで述べている。「それをコンテキストの観点でやっているのです」。
創業者たちによれば、このオーディオ検索テクノロジーは、自然言語処理に依存している他の技術とは相当に異なっているものだということである。「私たちは、モデルが通話の違いを区別できるように訓練しています」と、Stephensonはインタビューで述べている。「それをコンテキストの観点でやっているのです」。
