
Google Cloud PlatformやAWSの上で動くアプリケーションの、モニタリングやロギング(ログ取り)、診断などのサービスを提供するGoogleのツールStackdriverが今日(米国時間8/31)アップデートされ、ロギングの機能が増えるとともに、無料のログサービスの大きさが拡張された。すなわち12月1日からは、Stackdriverのロギング機能は1プロジェクトあたり1か月に50GBまでのログを無料で提供する。50GBを超えるぶんは、1Gバイトにつき月額50セントが課金される。
このアップデートのスローガンは、ログの分析を早くし、管理を容易にし、そしてより強力にすることだ。そのためにGoogleのチームは、ログに何かが書き込まれたときと、それがStackdriverの分析結果に反映されるまでの時間を短縮した。これまでは、ログのアップデートがStackdriverのユーザーにとって可視になるまで5分以上を要していた。それが今や1分未満になったそうだ。
これまでも、5分では困るというユーザーはあまりいなかったと思うが、でも早くなって怒るユーザーはいないだろうね。
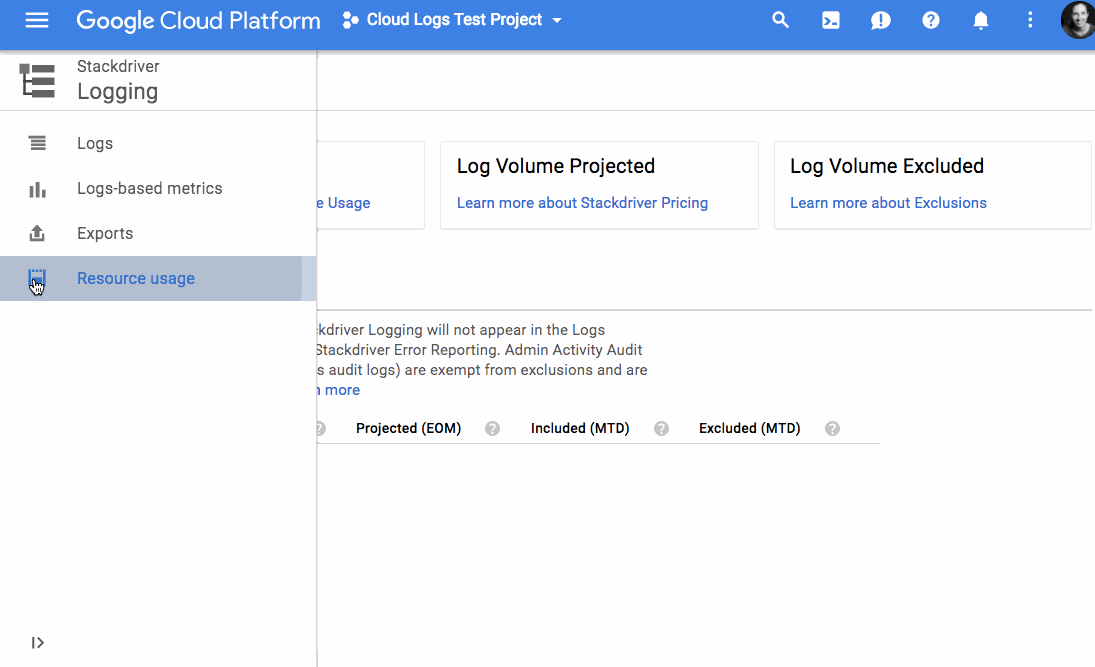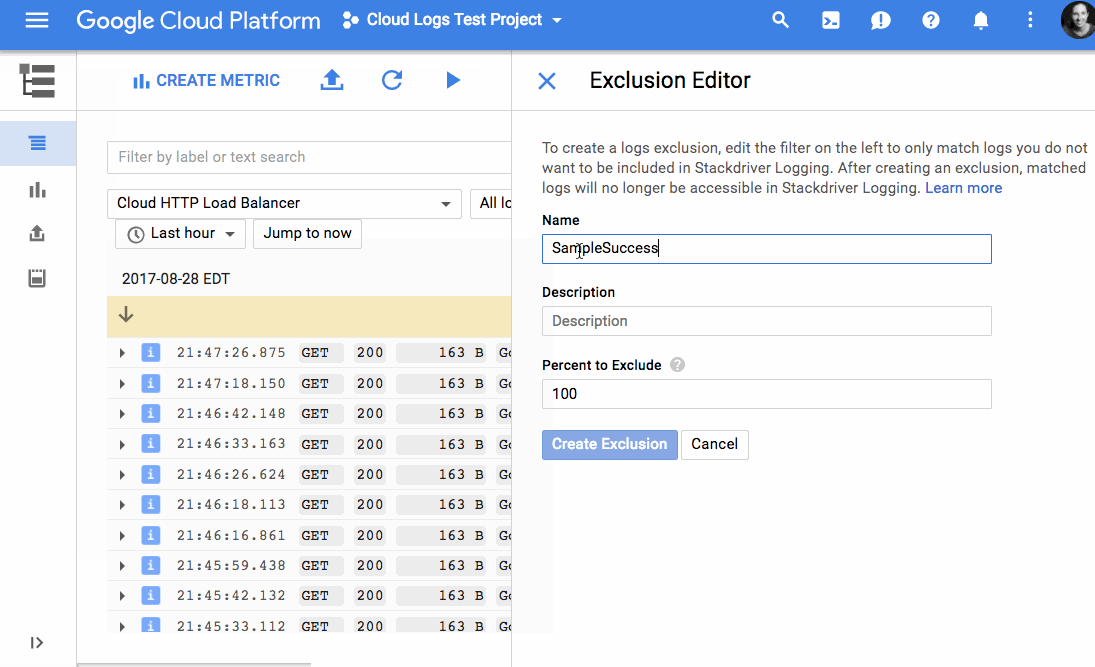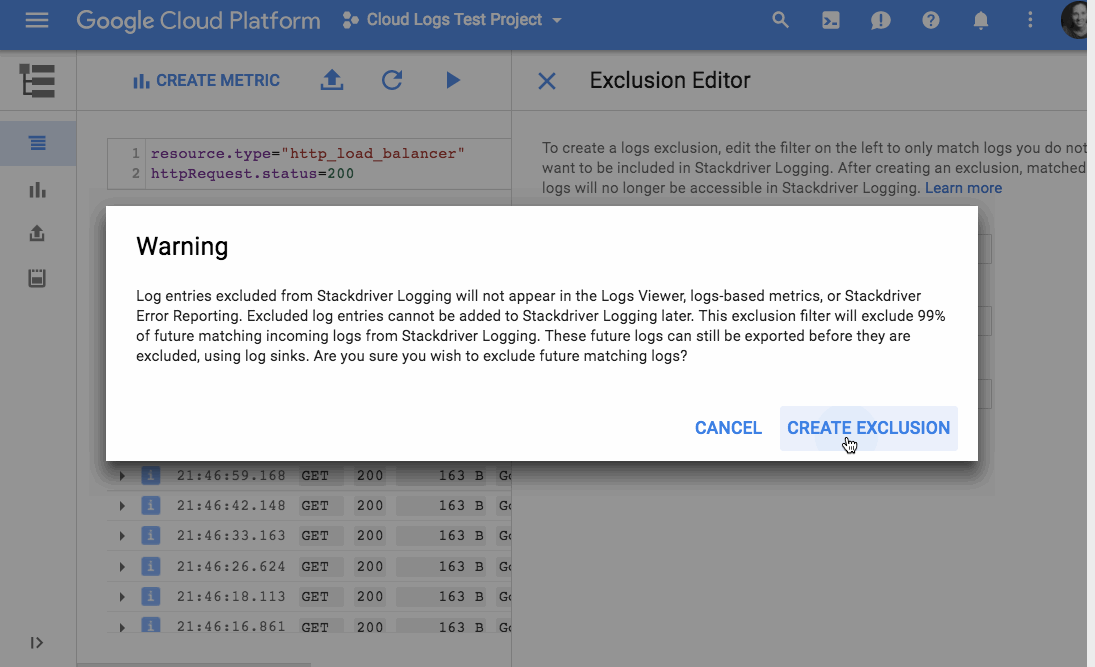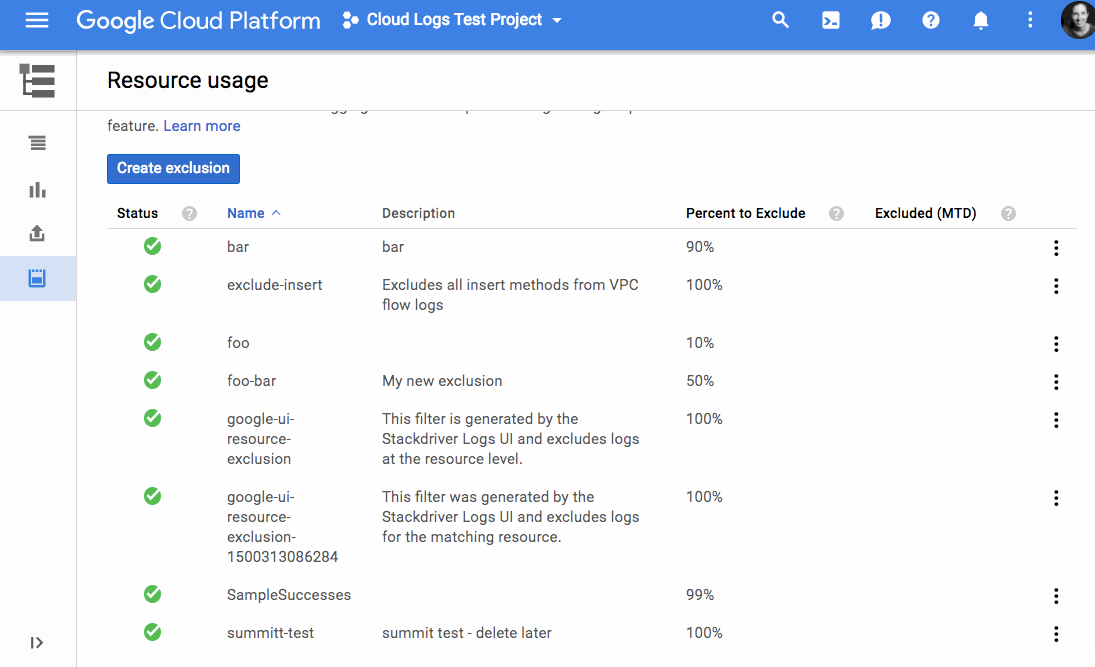
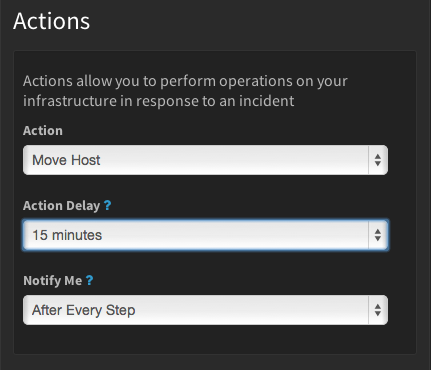
またこれからは、ログのどんな項目でもそれらの各欄をラベルにして、ログのデータを視覚化できる。しかしもっとおもしろいのは、ユーザーが排除フィルターをセットアップして、必要なデータだけをログに出力させられることだ。GoogleのプロダクトマネージャMary KoesとDeepak Tiwariが、今日の発表声明で書いている: “排除フィルターを利用してコストを下げ、無駄なログを減らしてS/N比を上げられる。特定のソースをブロックしたり、逆に特定のパターンにマッチする項目を拾うことによって、コンプライアンスにも貢献する”。
もうひとつの新機能一括エクスポート は、複数のプロジェクトのログをGCS, PubSub, BigQueryなどにエクスポートできる。これまではデベロッパーが、一つ々々手作業でエクスポートしていた。
[↓排除フィルターと排除を指定するエディター]
{kind=link}
{kind=link}
{kind=link}