
Nvidiaが昨日(米国時間5/29)発表したモンスターHGX-2は、ギークの夢の実現だ。それはクラウドサーバー専用機と称され、しかもハイパフォーマンスコンピューティングと人工知能の要件をひとつの強力なパッケージで満足させている。
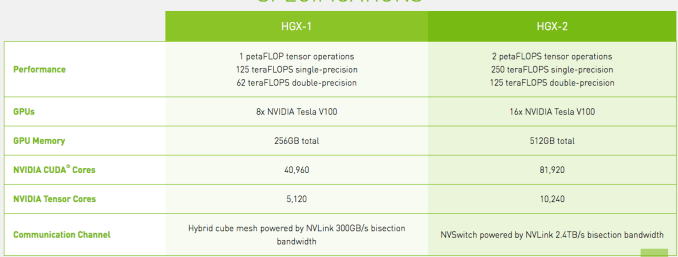
まず、誰もが気になる仕様から。プロセッサーは16x NVIDIA Tesla V100 GPUsで、処理能力は低精度のAIで2ペタFLOPS、中精度なら250テラFLOPS、最高の精度では125テラFLOPSだ。標準メモリは1/2テラバイトで、12のNvidia NVSwitchesにより300GB/secのGPU間通信をサポートする。これらにより、総合性能は昨年リリースされたHGX-1のほぼ倍になる。
図提供: Nvidia
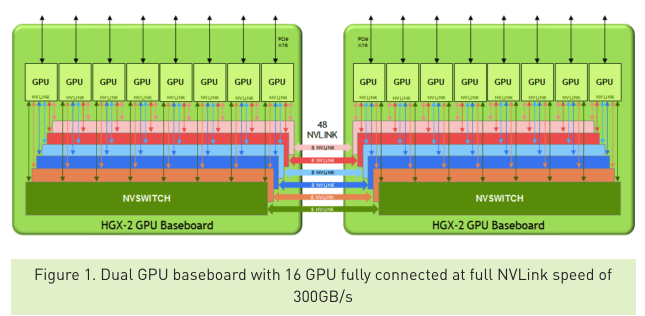
NvidiaのTeslaデータセンタープロダクトを担当するマーケティングマネージャーParesh Kharyaによると、これだけの通信スピードがあれば、複数のGPUを一つの巨大なGPUのように扱うことができる。“それによって得られるのは、膨大な処理能力だけでなく、1/2テラバイトのGPUメモリを単一のメモリブロックのようにアクセスできる能力だ”、と彼は説明する。
図提供: Nvidia
残念ながらこのボックスをエンドユーザーが直接買うことはできない。売り先はもっぱら、ハイパースケールなデータセンターやクラウド環境をエンドユーザーに提供する、インフラのプロバイダー、いわゆるリセラーたちだ。これによりリセラーは、ワンボックスでさまざまなレンジ(幅)の精度を実現/提供できる。
Kharyaはこう説明する: “プラットホームが統一されるので、企業やクラウドプロバイダーなどがインフラを構築するとき単一のアーキテクチャだけを相手にすればよく、しかもその単機がハイパフォーマンスワークロードの全レンジをサポートする。AIやハイパフォーマンスなシミュレーションなどで、各ワークロードが必要とするさまざまなレンジを単一のプラットホームで提供できる”。
彼によると、このことがとくに重要なのが大規模なデータセンターだ。“ハイパースケールな企業やクラウドプロバイダーでは、スケールメリットを確実に提供できることがきわめて重要だ。そのためにも、アーキテクチャがバラバラでないことが有利であり、アーキテクチャが統一されていればオペレーションの効率も最大化できる。HGXを使えば、そのような単一の統一的プラットホームへ標準化することが可能だ”、と彼は述べる。
そしてデベロッパーは、そういう低レベルの技術を有効利用するプログラムを書くことができ、必要とする高い精度を一つのボックスから得ることができる。
HGX-2が動くサーバーは、今年後半にLenovo, QCT, Supermicro, Wiwynnなどのリセラーパートナーから提供されるだろう。
画像クレジット: Nvidia