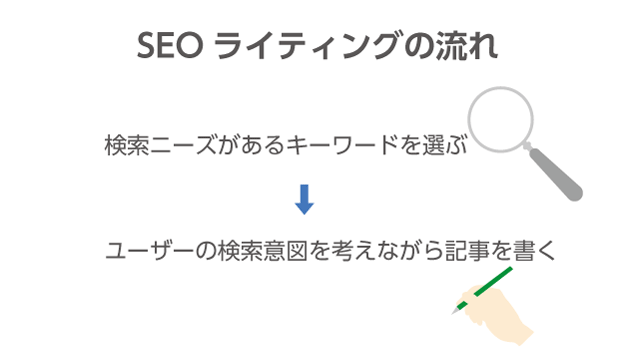
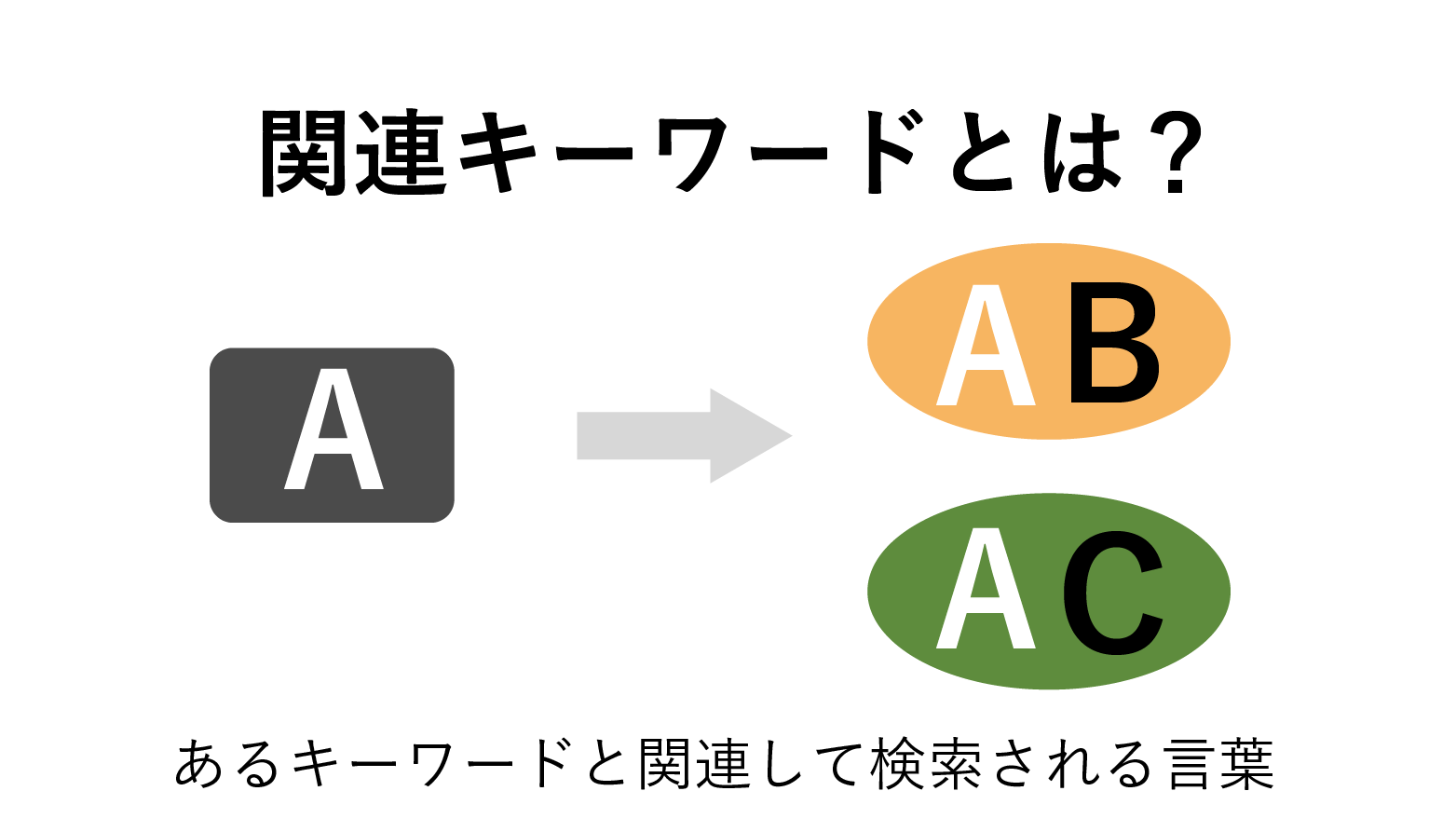
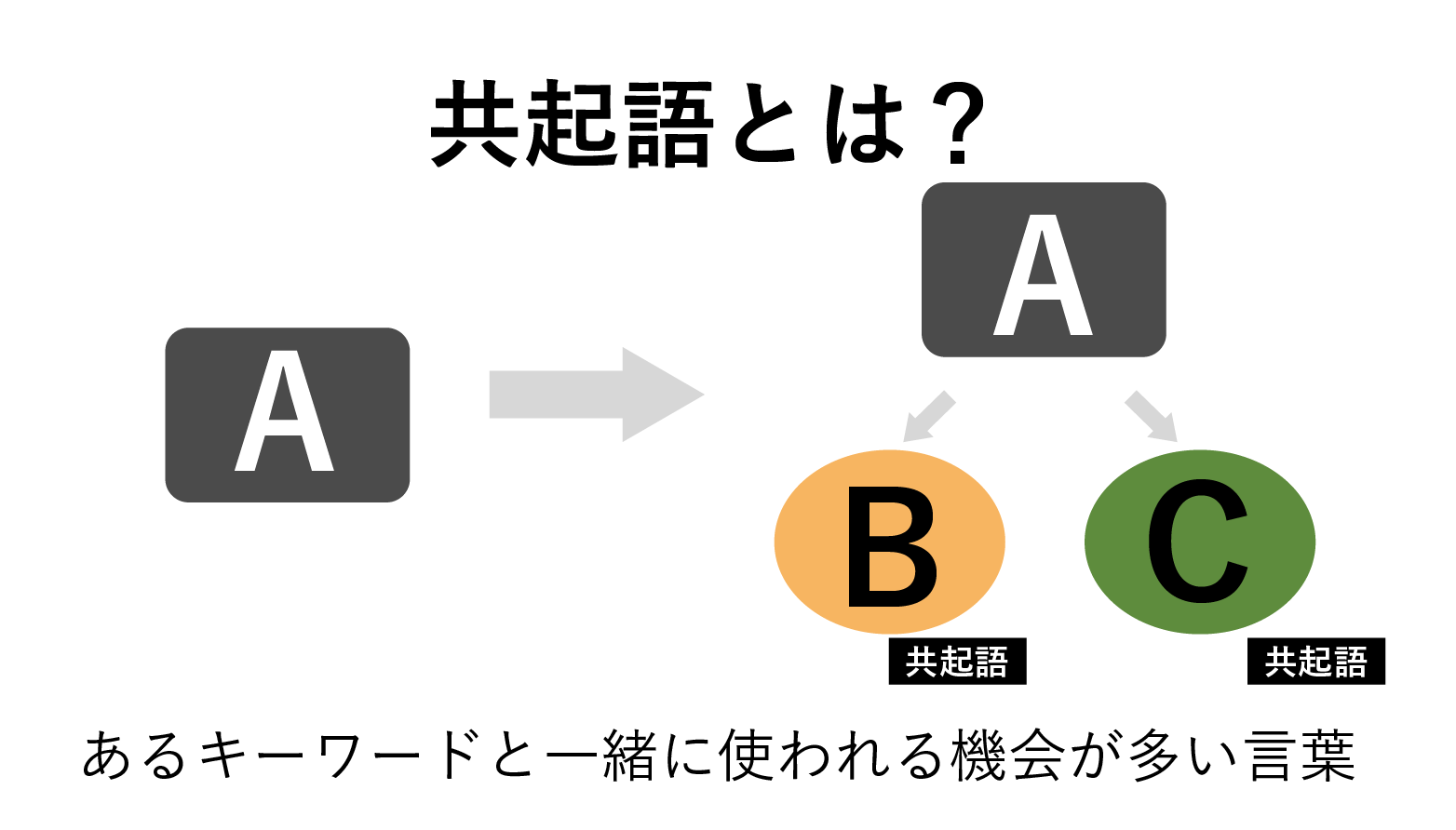
コンバージョン率の増加やUXの向上を目的としたABテストは広く行われています。有益なテストデータが得られ、コンバージョン率やUXの改善につながることもあります。
しかし、ABテストの結果を読み誤ると、貴重な気づきを見逃したり、実装した施策がマイナスの効果を与えてしまうこともあるでしょう。
今回は、そんなABテストにおける「落とし穴」を解説したCXLの記事を紹介いたします。
あなたのABテストがどれほど綿密に計画され、戦略的に行われたとしても、実際にテストを実行すると、明確な有意性も重要な解釈も導き出されないことがある。
不正確な統計学的アプローチが採用された場合は特に、エラーが起こりやすい。
この記事では、あなたが気をつけるべき、よくある10個の統計学的な落とし穴を紹介したいと思う。さらには、それらを避けるための方法も解説する。

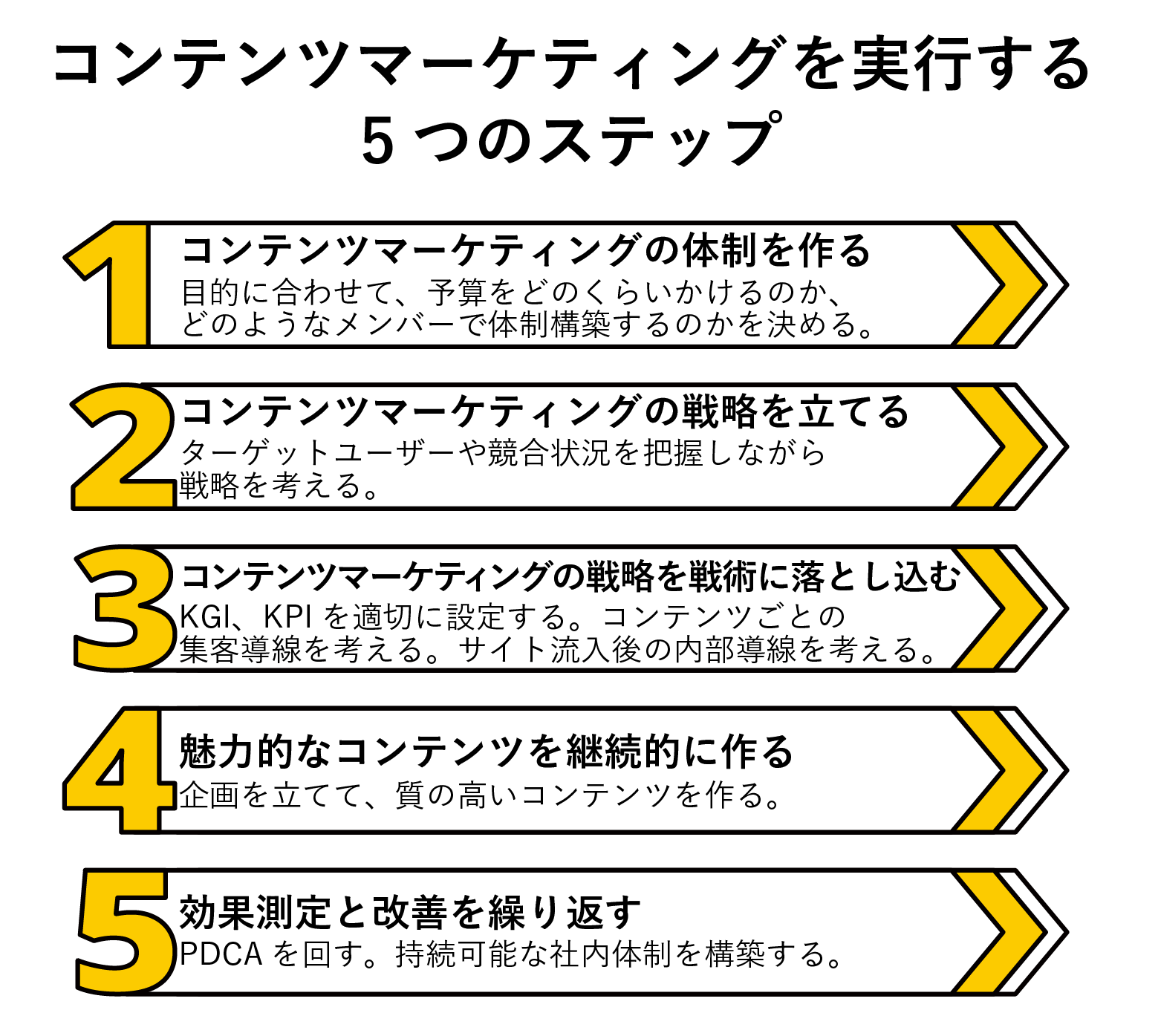
テストの各段階に潜んでいる、統計学的なつまづきやすいポイント
まずは、この記事で紹介する各項目をまとめてみようと思う。
Ⅰ.テストを行う前の統計学的な落とし穴
統計学的な落とし穴#1:多すぎる変数
「可能な限り多くの変数を用いてテストしよう。その中の1つは上手くいくはずだ。」
多くの場合、多くの変数を同時にテストすることは、良いアイデアとはならない。
一般的に、最適化のプロセスは、常に仮説ベースであるべきだ。壁にランダムなアイデアをぶつけても、それらはあなたをどこへも連れて行ってくれない。
多くのテストを行うことによる問題は他にもある。妥当性である。より多くの変数をテストすれば、実際はそうではなくとも、その変数の中のどれかが勝者となる可能性が高まってしまう。
「累積αエラー」という概念をすでにご存知の方もいるかもしれない。
各テストには、「テスト結果の中に特定のエラーが含まれている」という考えを受け入れて行われている。
ABテストは、全体の顧客の一部(選定されたサンプル)のみを考慮しており、実際の効果については不確定な要素が常に存在する。
しかしながら、テストを行う目的は、テストによって測定された効果を顧客全体へと波及させることだ。そのため、テストの信頼性が重要となる。

テスト結果は、全体に効果があると認められるものを、全ての顧客に適用されるべきだ。
原則として、我々は信頼性が95%のものを受け入れる傾向がある。これは、5%の1型エラー(「αエラー)、もしくは、偽陽性)の可能性を受け入れることを意味する。
全てのケースの5%で、実際はそうでないにも関わらず、有意性のある効果が得られてしまうことを想定している。
しかし、この低確率のエラーは、変数が1つのテストにおいてのみ、公正とすることができる。複数の変数を使用すると、指数関数的に増加してしまう。
つまり、1つの変数を用いた場合、エラーの可能性は5%となるが、複数のグループが1つのグループと比較されると、αエラーは累積的に増加してしまう。
個々のグループの比較では単純なαエラーの発生となるが、全てのグループ間においては累積的に発生すると考えるべきだ(これは、確率の公理に従っている)。
3つの変数のテストでは、それぞれがコントロールグループと比較され、エラーの可能性はすでに14%となっている。8つの変数のテストの場合、34%となる。
つまり、この場合、3回に1回のケースにおいて、偶然の結果による有意性が見られることになる。
一度に複数の変数を使用することで、こうしたエラーが「加速」することがわかる。

より多くの変数が使用されると、不正確な判断を下してしまう危険性も高まる。
下記は累積アルファエラーの算出公式だ。
Cumulative alpha = 1-(1-Alpha)^n
アルファ=選択された有意性のレベル。原則として0.05。
n=テストで使用された変数の数(コントロールグループは含まない)
朗報として、VWO社のSmart StatsやOptimizely社のStats Engineを使用すれば、複数の変数によるエラーが増加する可能性を適切に処理する機能が自動的に備わっている。
こうした適切に処理する機能がないツールを使用した場合、起こりうる可能性が2つある。
1.アルファエラーを自身で修正する
分散分析(ANOVA:Analysis of Variance)の助けを借り、テストされた最初の項目が、複数の変数テストの比較においても有意性が存在するかを確認する(F検定と呼ばれるものだ)。
しかし、この場合、どの変数であるかを知ることはできない。変数のユニ・ファクトリアル分析を行えば、個々のサンプルの変数の差異を確認することができる。
2.テストで使用する変数を制限する
最初の選択が複雑で時間のかかるものであれば、テストで使用される変数の数を最初から正しい値に制限すべきだ。我々の経験からすると、3つ以上の変数は1つのテストで追加されるべきではない。
エラーの可能性が増加してしまう問題は、多変量テスト(MVT:Multivariate Testing)でも起こることは覚えておこう。多変量テストを成功に導く方法は、統計学的な落とし穴#4で解説している。
統計学的な落とし穴#2:相互依存の推定
「2つのテストを同時に行うことはできない。結果が相互に影響しあい、歪んでしまう。」
1人のユーザーが複数のテストを同時に受けるべきかどうかについては、異なる意見がある。
効果は最終的に釣り合うため問題にはならないという意見がある一方、並行でテストを行う結果として汚染効果が見られてしまうとする意見もある。
つまり、テストと変数の相互作用が非線形の効果、広範囲の分散、信頼性の低下を導いてしまうということだ。
相互作用の効果が高い次元で見られることもあれば、見られない場合もある。いくつかのケースを例に挙げ、それぞれの対応を説明しよう。
1.相互依存のリスクが低い
リスクが低く、テスト間でのトラフィックの重複が管理できるのであれば、その2つのテストを並行で行うことは可能だ。同じユーザーが複数のテストを受けることができる。
例えば、トップページのユニークバリュープロポジション(UVPs:Unique Value Proposition)のテストは、製品ページの顧客の意見の表示のテストと同時に行うことができる。2つのテストは、技術的には全てのトラフィックにおいて、秩序立てたテストを行うことができる。
そのため、1人のユーザーが同時にテストを受けることができる。ここでは、1つのテストが別のテストと競合してしまう可能性は、低くなるはずだ。
なぜ、このようなことが起こるのだろう?
ABテストの仕組みを深く考えなくとも、ABテストの土台となる、無作為の原則に含まれている。
ユーザーはテストグループか、コントロールグループに、偶然に割り当てられる。これは、ユーザーを複数のテストに同時に割り当てる、複数のテストを同時に行う場合も含め、あらゆるテストに当てはまる事実である。
無作為の原則に加え、大数の法則の結果、他のテストにも参加しているユーザーの割当が、テストグループとコントロールグループで比例していることは確実となる。
その効果、グループ内で計測されているコンバージョン率のバランスが取れ、上昇の値も信頼できる測定となる。

純粋な無作為の原則が適用された場合、2つのテスト内のユーザーの割合は等しくなる(ソース:Optimizely)
2.相互依存のリスクが高い
もちろん、同時に行うべきではないテストも存在する。通常、同じページ、特に、1つのページの同じ要素のテストの場合、妥当性のあるデータを取得できない。
(極端な)例を挙げてみよう。1つ目のテストでは製品ページ内の「オススメの製品」の表示位置をテストしようとする。2つ目のテストでは、「オススメの製品」のアルゴリズムの変更をテストし、セールスに特化した記事を優先的に表示させようとしている。
もし、とあるユーザーが両方のテストに遭遇した場合、2つの変更の組み合わせが、1つの変更しか遭遇していないユーザーと比べ、最終的な影響が異なってしまう。
相互に強く依存し合うテストに対しては、2つの解決策がある。
解決策A:それぞれのテストを別々に行う(安全策)
多くのテストツールでは、複数のテストへトラフィックを分割することができる。例えば、「オススメの製品」の表示位置のテストにはトラフィックの50%を割り当て、「オススメの製品」内にセールス目的の記事を差し込むテストには残りの50%を割り当てる、といったことも可能だ。
これにより、ユーザーは1つのテストしか遭遇しなくなる。この場合、テストの実行期間を、あらゆるテストに対し、適切に設定することが必要だ。
50対50にトラフィックを分割することが不可能であれば、それらのテストは別々に行われるべきである。この場合、常にテストには優先度をつけ、それらを適切にロードマップに落とし込むべきである。
解決策B:多変量テスト
もう1つの解決策は、多変量テストを用いることだ。テストによって最適化すべき目的が同一であり、同一のページでテストが行われる場合、有効となる。
これは、変数が合理的に組み合わせられなければならないことを意味する。例えば、片方のテストがメインのナビゲーションの変更であり、もう片方のテストがチェックアウト内のUVPsの変更であった場合、あまり意味はなくなってしまう。なぜなら、それらのコンセプトの間に、相互依存はほとんど見られないからである。
統計学的な落とし穴#3:クリック率とコンバージョン率
「クリック率が増加すれば、コンバージョン率も増加しているだろう。」
製品ページへの訪問数を増加させることができた場合、もしくは、より多くの訪問者が製品をカートに入れた場合、それらだけでは、最終的な目標数が増加したことを意味しない。
これほど単純であれば、どれほど良かったことか…

典型的なコンバージョンファネルでは、上昇の消滅が見て取れる。
それゆえ、あらゆるテストで最終的なコンバージョンを測定することは非常に重要となる。
主要KPIの選択と優先度付け
もちろん、最終的なコンバージョンは、ビジネス、目標、仮説などによって異なる。ここでは、いくつかの候補を紹介しよう。
コンバージョン率
ECサイトの場合、最も一般的なKPIだ。ユーザーを購入者へとコンバートすることを主目的としているテストであるならば、コンバージョン率の優先度は最も高くなるはずだ。
買い物カゴ内の価格と1訪問あたりの収益
1訪問あたりの収益も一般的なKPIであり、特定のケースにおいては、特に重要となる。
例えば、製品ページ内の「オススメの製品」の最適化(デザイン、表示位置、アルゴリズム)は、ユーザーに購入を促す必要はない。しかし、おそらく、最終的な購入数は増加するだろう。
例えば、補完製品のオススメ(クロスセル)は、新しい上着の購入と同時に、それに合ったジーンズの購入への刺激となる。この場合、コンバージョンごとの収益や、訪問ごとの収益は、コンバージョン率よりも、関連性が強くなる。
返品
例えば、サイズについての情報(より小さい場合が多い)を製品ページに記載することが、顧客が適切なサイズを発見するための手助けとなるかどうかのテストを行いたい場合、もう一歩踏み込んだテストにしよう。
返品されてしまうような購入を勧めることは、短絡的な考えである。この場合は、返品後の収益や、利益率を測定する。こうしたデータは、テストツールやデータウェアハウス(DWH:Data Warehouse)に連携することで分析が可能となる(詳細は「統計学的な落とし穴#8」を参照)。

マクロコンバージョンは、マイクロコンバージョンよりも優先度が高い
マイクロコンバージョンは診断機器
もちろん、クリック率やページビューなどのKPIは意味がない、というわけではない。しかし、その考えの最終的な成功を評価するために用いられるのではなく、診断用の機器として用いられるべきだ。
より多くの顧客がより多くの商品を買ってもらうため、ナビゲーションの最適化をテストする場合を考えてみよう。驚くべきことに、コンバージョン率や収益に全く変化が見られないこともある。
顧客は、新しいナビゲーションを、古いナビゲーションと同じように使用しているのだろうか? もしくは、サイトナビゲーション、検索、ティザーカテゴリーなど、他のエントリーポイントを使用しているのだろうか?
この場合、ナビゲーション要素のクリック率や、サイト内検索の使用率などを見てみるといい。「なぜ?」に対する解答に近づくことができ、ユーザー行動の理解が深まるはずだ。
KPIに合わせてテストのサイズを調整する
比較的短い期間でのテストの場合、買い物かごへの追加数やクリック数などのマイクロコンバージョンで大きな上昇が見られることがある。しかし、これら全てが、コンバージョン率には反映されるわけではない。
実際、KPIの種類と求められるテストサイズには関係がある。これは、KPIによって可変する変動や不確定要素によるものだ。不確定要素が多いほど、有意性のある効果を得るために、テスト期間は長くする必要がある。

KPIの変動が大きいほど、テスト期間は長くしなければならない
クリック率やページビューは、カウントデータと呼ばれており、変動幅は比較的小さい。クリックするか、しないか、である。
しかし、コンバージョン率は別物である。実際に購入するかしないかは、このKPIの不確実性を増加させる他の要素によって影響される。
収益のKPI(バスケットサイズなど)の効果を検証するためには、コンバージョン率よりも大きなサンプルサイズが必要となる。こうしたメトリックKPIと呼ばれる指標は、ユーザーが購入するレベルについての不確実性が高いのである。
返却後の収益の最適化を目指す場合、サンプルサイズはさらに巨大になる。このKPIの場合、信用できる結果を獲得することは非常に困難である。
誰かが何かを購入し、どのくらいの金額を購入したか。また、何を返却し、どのくらい返却したか。テストの不確実性は増し、結果として、テストの実行期間はより長くなる。
信頼性のある結果を実際に手にしたかどうかを確認するため、そのテストにおけるメインとなるKPIについて、まずは考えるべきだ。そして、そのKPIに適したサンプルサイズに調整しよう。
過多な指標を測定しない
より多くのKPIを測定するほど、最終的な判断を下すことが難しくなる。
テストを行う前に、どのマクロコンバージョンと、どのマイクロコンバージョンが必要なのかを考えるべきだ。ツール内で使用できるあらゆる指標をランダムに使用した場合、そのテストの目標を見失ってしまうだろう。
判断を下すことが困難になってしまうテキサスの狙撃兵の誤謬のように、認知バイアスに屈服することは容易である。
さらに、高すぎる指標は、偶然によって発生した指標の効果を見てしまう可能性を高めてしまうだろう。
統計学的な落とし穴#4:多変量テストへの恐れ
「多変量テストを行うべきではない。コストが掛かりすぎるし、結果にも信頼性がない。」
多変量テストの成否は、それをどのように行うかによる。適切に設定されれば、多変量テストは異なる要素やその組み合わせをテストする上で、非常に優れたツールとなる。
1つのページ内にある複数の要素を同時にテストするために多変量テストを使用することは、複雑に聞こえるかもしれない。しかし、必ずしもそうではない。守らなければならないルールが、いつかあるに過ぎないのだ。
多すぎる変数を使用しない
複数の変数を用い多変量テストを設計する際も、累積アルファエラーの問題が生じる。実際はそうではない、片方の変数を勝者と宣言することを防ぐために、可能な限り、変数の組み合わせの数を制限すべきだ。
よく練られた仮説をベースに、複数の要素とその組み合わせは、慎重に選択されるべきである。さらに、結果が公正であることを確証するために、信頼性は高いレベル(例えば、99.5%)に到達すべきだ。

多変量テストの結果を盲目的に信じるべきではない。
多変量テストの結果、どの変数が最も高い(最も有意性のある)上昇であるかを確認するだろう。しかし、どの要素の組み合わせがこの上昇を達成したかという確認しかできない。個々の要素がコンバージョン率にどのように影響したかを確認することが重要だ。
これは、分散分析と呼ばれる手法の助けを借りることで実現できる。この手法は、コンバージョン率への個々の要素の影響(例えば、色やレイアウトなど)を取り出すことができる。
フォローアップテストの結果の正当性を確かめる
多変量テストの結果の信頼性を増すために、継続したABテストを行うことで、テストの勝者の信頼性を確かめることができる。単純に、勝者の組み合わせを、コントロールグループと対比すればよい。

個々の要素の効果は、個別に算出することができる(例:分散分析の助けを借り、色とレイアウトの効果を区別させる)
Ⅱ.テスト中の統計学的な落とし穴
統計学的な落とし穴#5:早すぎる時点でやめてしまう
「テストを開始してから3日が経った。変数のパフォーマンスは悪い。ここでテストをやめてしまおう。」
テストを初期の段階で止めてしまう理由は多くあるかもしれない。例えば、ビジネス上の目的が、非常に悪いパフォーマンスを出している変数によって脅かされている場合などだ。
しかし、仮説の成否を判断するには、3日以上のテストが求められる。仮説が正しいか、正しくないかについての意見を述べるために、あらゆるテストは最低限のテストサイズが求められている。
テストの最初の数日間で、大きな変動が見られることがある。その数はまだ小さいため、偶然による結果である可能性もある。
おそらく、全くの偶然によって、コントロールグループ内の顧客が大量の買い物を行い、テスト中の機能が一時的に大きく減少することもある(詳細は「統計学的な落とし穴#8」をご参照)。

テストの初期段階で、大きな変動は発生しうる。これらの数字を信用すべきではない。
テストの初期段階ではネガティブな効果が見られたが、3週間後には非常に大きなポジティブな効果が見られることも経験している。テストを行う前に、テスト期間を算出するツールの助けを借りるなどして、テストに必要な期間を算出すべきである。
テストの初期の段階で、大きな減少が見られなければ、それは単純に、現在は落ち着いているのでこのままテストを継続すべきであることを意味している。

テストを行う前に、サンプルサイズの見積もりを行うべきだ。
統計学的な落とし穴#6:変数を閉ざしてしまう
「問題ない。1つの変数が上手くいかなければ、それを変更するか、切り離してしまえばいい」
使用した変数のうちの1つのパフォーマンスが悪く、ビジネス上の目標を脅かしてしまった場合、もちろん、その変数を切り離したいと思うはずだ。
同様に、トラフィックの配分が少ない変数からスタートし、時間をかけて増やしてしまうこともある。さらに、テスト中に対象の場所を変更してしまうこともある。
上記3つの現象は、全て結果を破損しうるものだ。ABテストにとって、テスト結果はテスト時間の代表である。トラフィックを変更してしまうと、特定の期間が反映されなかったり、過度に反映されてしまったりすることになる。
テスト中に変数を切り離してしまうことも、同様の影響がある。変数の中身が変更した場合、テスト結果は異なる仮説と考えの混ざり合いになってしまい、ついには、どんなインサイトも提供してくれなくなるだろう。
ここで、科学的な厳密さと、公正で実践的なビジネス上の課題の健全なバランスを、我々は発見する必要がある。
そのバランスを発見するためのいくつかのアドバイスを紹介しよう。
・テストが開始された数日後に変数を切り離してしまう場合、その変数を含めず、テストを再度行うことを勧める。この場合、時間のロスはそれほど大きくない。
・テスト中に変数を変更する前に、新しいテストを開始し、コントロールグループに対して適用された変数をテストすべきだ。
・トラフィックを日毎に高いレベルで変更する場合、望まれるトラフィック量に達する十分な量の時間をカバーし、それにより、テスト期間中のトラフィック数が安定するようにしなければならない。
統計学的な落とし穴#7:ベイジアンテストの手順
「新しいベイジアンテストは、我々により早く結果を提示してくれる。」
VWOやOptimizelyにすでに適用されている新しい統計手法は、どの時点でもテスト結果を読み取ることができるという利点を提供してくれている。また、求められるテストサイズに達していなくとも、その結果の信頼性は高い。
しかし、ベイジアンテストは、誤った手段に対する防護策ではない。もしくは、New York Timesが指摘しているように、「ベイジアンテストは、簡単に言うと、悪の科学から我々を守ることはできない」のだ。
期待の問題
ベイジアンテストを行う前に、テストのコンセプトが成功する可能性を想定した、事前確率と呼ばれるものを行うべきだ。この想定が誤っていた場合、テスト期間が長くなったり、無効な結果を得ることになったりするリスクを負ってしまう。

VWOのレポート画面
テストサイズが小さい問題
テスト期間中のどの時点でも、結果を読み取ることができるが、テストの初期段階で変動が大きい場合、注意が必要だ。テスト中の訪問者の数はまだ非常に少なく、稀な観察結果に強く影響をうけてしまうからだ(例:非常に多いオーダー数)。
ベイジアンテストが持つ利点にも関わらず、データセットがまばらである場合、十分な信頼性は提供してくれない。
新しい手段だからといって、ABテストへの不正確なアプローチから守ってくれるものではない(ちなみに、伝統的な頻度確率の手法でも同様である)。誤った手法からあなたを守ってくれる手法は存在しないのだ。
Ⅱ.テストを行った後の統計学的な落とし穴
統計学的な落とし穴#8:たった1つのデータソースを信頼してしまう
「テストツールの結果は判断を下すのに完全に適している。」
確かに、テストツールは、テストのコンセプトがより高いコンバージョン率を導いてくれるかどうか、その判断を助けてくれる。しかし、より多くのインサイトを発見したり、結果の正当性を判断するために、データを詳細に確認する価値があったりする場合もある。
テストツールからの結果は、奥まったフォルダに格納すべきではなく、Web分析のシステムやDWHなどの他のデータベースに組み込むべきだ。
それにより、一連の重要な質問に答えられるようになる。
なぜだろうか?
テストの結果が予測したものでなかった場合、「なぜ?」という質問は常に浮上する。前述のメタナビゲーションの例であるように、テスト結果をより良く理解するために、マイクロコンバージョンを見てみることは有益である。
ナビゲーション要素のクリック数のセットアップを怠ってしまったり、テスト前に内部検索を目的として使用している場合、このような質問に後からテストツールは答えてくれない。
反対に、テストツールがWeb分析ツールに接続されている場合、これらの指標を評価することができる。

顧客を完全に理解する手助けとなる、データソース間の良好な接続状況
コンバージョン率の増加はより多くの利益をもたらすのか?
最適化の施策の結果、顧客がより多くのオーダーをしてくれたら、それは素晴らしい。
しかし、それと同量か、それ以上の量を返却してしまった場合、最終的には金銭的なロスを意味してしまう。テストツールとDWHを接続することで、返却後の結果を分析することができる。
ここで、変数のIDはバックエンドへ移行され、返却率や返却後の収益をテストとコントロールグループの追加KPIとして参照することができる。
大量のオーダーを考慮に入れてしまう
大量のオーダーは、ほぼ全てのECサイトが当てはまり、テストの評価を検証するうえでの問題となる。コールセンターの顧客、B2Bの顧客、過度なオンラインの買い物客、なども当てはまる。
これらは外れ値と呼ばれ、結果を歪めてしまう。なぜだろうか? テスト結果を評価する際、平均値を見るからである。
・コンバージョン率は訪問者の特定のグループ内のコンバージョン率の平均に他ならない
・訪問ごとの収益は、訪問ごとの平均収益である
通常、大量のオーダーやショッピングカートの金額は、平均値を上昇させてしまう。もし、全くの偶然により、比較的小さなサンプルサイズで、コントロールグループで極めて高い値の顧客を選んでしまった場合、この時点で結果がポジティブなものにならず、ネガティブな結果となるだろう。

外れ値の適応によりテスト結果は変化してしまう
外れ値にはどう対応すべきか?
ほぼ全てのテストツールは生データを取得することができる。ここで、変数内の全ての顧客のオーダーはリスト化されている。他の可能性として、あなたが選択したWeb分析ツールに対応したレポートをセットアップすることが挙げられる。
そして、フィルターを設定し、異常なほど高いオーダー数を排除すればいい。

分析ツールで大量のオーダーのフィルターを設定する
いくらかのコストはかかってしまうが、外れ値の除外は行う価値はある。なぜなら、外れ値によって「隠されている」重大な効果を発見できる場合もあるからだ。
データフリークのために:信頼区間の算出を正当化する
従来の信頼区間の算出方法は課題を含んでいる。基本データが特定の分布、つまり正規分布に従っていると想定していることだ。左図は完全な(理論的な)正規分布の図である。オーダー数は、正の平均値周辺を上下する。
この例では、多くの顧客が5回オーダーをしている。多かれ少なかれ、オーダーの発生件数は少ない頻度となる。右図は、実際のケースを表している図である。

理論の図と実際の図
コンバージョン率の平均が5%とすると、95%の顧客は買い物をしていない。購入者の多くは1つか2つのオーダーをしており、規格外の量を注文する顧客は僅かである。
このような分布は「右への歪み」と呼び、特にテストサイズが小さい場合は、信頼区間の正当性に影響を与える。実質的には、その区間は十分な信頼性をもって算出されていない。
中心極限定理は、非常に大きなサンプルではこれらの歪みの影響は少ないとしている。しかし、実際にこの区間がどの程度「不正確」であるかは、データが完全な正規分布からどの程度外れているかによる。
平均的なオンラインショップに関しては、少なくとも90%の顧客は何も購入しない。データ内の「0」の割合が極端であり、偏差も膨大であることが一般的である(シャピロ-ウィルク検定はデータが正規分布しているかを確かめることができる)。
結果として、従来のt-検定とは別のデータに目を向けることには価値がある。正規分布でないデータに信頼性を提供する方法は他にもある。
1.U検定
マン・ホイットニーのU検定(ウィルコクソンの符号順位検定)は、データが正規分布より大きく逸脱している場合、t-検定の代替となる。
2.ロバスト統計
ロバスト統計は、データが正規に分布していない場合や、外れ値によって歪んでいる際に、用いられる。ここでは、平均値と変数が、極端に高い値や低い値に影響されないように、算出される。
3.ブートストラップ
ノンパラメトリック手法と呼ばれるこの手法は、あらゆる分布の想定とは独立して作用し、信頼水準と区間へ信頼性のある推定値を提供する。核としては、リサンプリング手法に属する。ランダムサンプリングの手法によって得られたデータを基に、変数の分布の信頼できる推定値を提供するのだ。
統計学的な落とし穴#9:セグメント内での評価
「セグメント内の結果を見るつもりだ。どこかで上昇値が見つかるだろう。」
一般的に、セグメントを確認することは良いアイデアだ。そもそもとして、ABテストの結果は全ての訪問者間で報告される。しかし、異なる反応を示すグループもあり、それらは集約されたデータからは発見できない。

収益性の高い顧客グループと収益性の低い顧客グループ内のセグメント
そのオンラインショップを独自とさせる特徴、つまり、ユニークバリュープロポジション(UVP:Unique Value Propositions)はその好例である。
新規顧客と既存顧客では影響が異なることが一般的である。既存顧客はすでに購入するメリットを知っているが、UVPは新規顧客の購入と信頼性の構築の過程で大きな助けとなる。
このような可変する反応は、集約されたレポートでは検知されず、有意性のある上昇が確認できないことによって、がっかりしてしまうかもしれない。
テストツールを他のデータソース(Web分析やDWH)に接続することにより、テストツールでは発見できない一連の顧客の特徴のテスト結果を分析することができる。例を挙げてみよう。
- 性別
- 年齢
- 購入者のカテゴリー
- 訪問されたページ
- クリック行動のデータ
- 収益率
- 地理情報
しかし、ここでも注意が必要である。より多くのセグメントを他のセグメントと比較すると、エラーが発生する可能性は指数関数的に増加してしまう。
そのため、セグメントをランダムに選ぶことは避けるべきだ。解釈でき、活用でき、テストのコンセプトと関連性のある状態を維持しよう。
さらに、セグメントのサイズが十分であることにも気をつけよう。
例えば、タブレットでカテゴリーページへアクセスし、製品ページに訪れ、女性で、週末に購入したユーザーしか含んでいなければ、訪問者全体の一端のデータしか見られないことになる。
それゆえ、セグメント内のテストサイズが十分であることを常に意識しよう。テストを行う前にそのセグメントが分かっている場合は、少なくともテスト期間を2倍にしよう。
konversionsKRAFTの有意性計算機やCXLのABテスト計算機などを用いれば、それぞれのセグメントの信頼性がどの程度あるのかを確認することができる。
統計学的な落とし穴#10:テスト結果を受けた安易な推測
「結局の所、テストは成功しなかったようだ。そのコンセプトをロールアウトしたが、コンバージョン率は上昇しなかった。」
成功したテストの後、そのテストの結果を基に、将来的な追加利益が算出されることはよくある。その結果、見栄えの良いマネージメントへのプレゼンテーションが行われ、
特定のテストのコンセプトを適用すれば、今後2年間で利益が40%上昇するという予測を披露するかもしれない。素晴らしい。しかし、実際にそんなことが起こるのだろうか?
暴言を吐くようで申し訳ないが、そのような雑な推測はすべきでない。
そのような推測は、3ヶ月後の天気予報を信じるようなものだ。テストの結果をそのまま未来に反映するような単純な予測は、下記の理由で、実現することはない。
理由1:短期的な効果と長期的な効果
基本的に、ABテストはそのコンセプトがユーザー行動に短期的な変化を導くかどうかを測定するために行われる。
3週間のテストを行い、コンバージョン率がX%上昇した。しかし、この変化は、ユーザー行動に長期的に影響することは約束しておらず、顧客満足度やロイヤリティなどのKPIを保証するものでもない。
これらを現実のものとするためには、顧客基盤や、ユーザーニーズの変化や習慣の効果を記録するために、非常に長い間テストを実行しなければならない。また、ノベルティ効果にも気をつけなければならない。ユーザーは目新しさに慣れてしまうのだ。
つまり、今日、我々にとって印象的なものは、明日にはただの慣習になっており、強く認知されることはない。
結果として、短絡的な効果が継続し、将来に渡って影響があると想定することは、間違いなのである。
理由2:因果関係と相関関係
テスト結果に有意性のある上昇が見られ、テストのコンセプトがしっかりと実装されたとしよう。ここでよく発生することは、コンバージョン率への効果を測定することを目的とした、ビフォー・アンド・アフター比較と呼ばれるものだ。
ここでは、実装前の期間のコンバージョン率が、実装後の期間のコンバージョン率と比較される。この2つのコンバージョン率の差は、テストで得られた結果と完全に一致すると予測される。しかし、実際そうなることは稀である。
もちろん、コンセプトが実装された後、コンバージョン率の増加は見られるだろう。しかし、その他数百の要素が並行して影響しており、それらがコンバージョン率を決定するのだ(例;季節、セールのイベント、配送の困難さ、新製品、異なる顧客やノイズ)。
因果関係と相関関係を分けて考えることは非常に重要である。相関関係は、2つの特徴的量が同様の傾向をたどる程度を示すに過ぎない。
しかし、相関関係は、1つの特徴的な数字に因果関係があるか、もう1つの変数の変化の原因となっているかについては何も語っていないのである。
この考えは、下記の図で明らかになる。科学、宇宙、技術への米国の投資は増加しており、それと同時に、自殺者の数も増えている。全く理にかなっていない。

因果関係と相関関係の面白い例をいくつも見つけることができる
コンセプトが実装された後、コンバージョン率の変化が観測された場合、特定の要因を1つだけ抽出することはできない。コンバージョン率の変化の因果となる要素はわからないのである。
想定したコンセプトがポジティブな影響を与えた場合、ネガティブに働く他の要因も存在しており、結局の所、全ての効果を証明することはできないのである。
因果関係の測定とテストのコンセプトの長期間における効果を測定する可能性は1つしかない。成功したテストの後、そのコンセプトを95%の顧客に対してロールアウトする(テストツールなどを用い)。5%の顧客はコントロールグループのままとする。
この2つのグループを継続して比較することで、そのコンセプトの長期的な影響を測定することができるのである。
この手法に馴染みがないのであれば、因果関係と相関関係を区別するために、さらに多くのアドバイスをこちらで得ることができる。
理由3:信頼性の誤った解釈
信頼性の解釈を誤解してしまうという問題もある。
仮に、テスト結果で4.5%の上昇が見られ、信頼性も98%を得られたとする。これは、4.5%の効果が98%の確率で起こることを意味しているわけではない。あらゆる信頼性の分析が提供するのは、ある確率(信頼度)における、期待される上昇を含む区間、それだけなのである。
この例では、2%から7%の間の測定値にもとづく効果が、98%の確率であることを意味している。そのため、実際の効果がテスト結果の効果と完全に一致すると想定するのは、間違いなのである。テストの期間が長くなるほど、この区間は短くなる。
しかし、推定値の正確なポイントに到達することは決してない。信頼度のレベルは、その結果がどの程度安定しているかについての推定値を与えているのだ。
ところで、信頼性のレベルと、多くのツールで影響されている、チャンス・トゥ・ビート・オリジナル(CTBO:Chance to Beat Original)には、僅かであるが、重要な違いがある。
信頼性のレベルは、特定の区間における上昇(信頼区間)の可能性を提供し、そのコンセプトが成功しているか、成功していないかについては何も語っていない。
一方で、CTBOは、信頼区間がどの程度重複され、何らかの意味において、テストされた変数がコントロールグループよりも優れているかを測定する。正確なテスト結果をしるために、この違いを知っておくことは重要である。
結論
テストツールからの数字のみを信頼している場合、エラーの原因となり、結果の公平性を脅かす恐れがある。これを避けるため、テストのあらゆる段階で守るべき基本的なルールがいくつかある。
ABテストのトピックとして、テストの妥当性を求める科学的な要求と、ビジネス上の実際のニーズには、常に対立が存在する。
テストデータを十分に信頼し、あなたが実行するテストが常に実践的で関連性のある結果を得られるよう、素晴らしい方法を見つけるようにしよう。
コンバージョン改善(CRO)の観点で重要なABテストの罠についてわかりやすくまとめられた記事でした。
SEOと組み合わせるなら、SEOで認知度とトラフィックを上昇させ、ABテストによってコンバージョン率を改善する。もちろん、こんなにきれいに行くことは稀かもしれませんが、少しでもその可能性を高めるため、とても有益な記事でした。
SEO担当者の中にはUXを担当している方もいるかもしれませんが、少しでも参考になれば幸いです。
メールマガジン購読・SEO Japan Miniのご案内
SEO Japanの記事更新やホワイトペーパーのリリース時にメールにてお知らせいたします。
SEOを始めとしたWebマーケティングの情報を収集されたい方はぜひご購読ください。
>>メールマガジンを購読する
投稿 ABテストにおける10個の統計的な罠:オプティマイザーのためのパーフェクトガイド は SEO Japan|アイオイクスのSEO・CV改善・Webサイト集客情報ブログ に最初に表示されました。