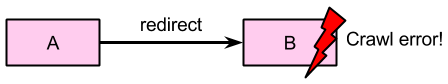ディープ リンクは、オーガニック検索内で最近見かけるようになった「新入り」ですが、目を見張るような速さで普及しています。ユーザーがログインしている場合、Android での Google 検索結果のうち、15% が App Indexing によるアプリ ディープ リンクを表示しています。前四半期だけで、アプリ ディープ リンクのクリック数が 10 倍に急増しました。
App Indexing を今年 6 月に公開して以来、デベロッパーの皆様からさまざまなフィードバックが寄せられました。ほとんどの実装はうまく行きましたが、うまく行かなかった実装からも多くを学ぶことができました。この記事ではそうした経験を踏まえ、App Indexing の実装を成功させるうえで欠かせない 4 つのステップについて解説します。また、アプリのパフォーマンスを把握したり、アプリの利用を促進したりするための便利な新機能も紹介します。
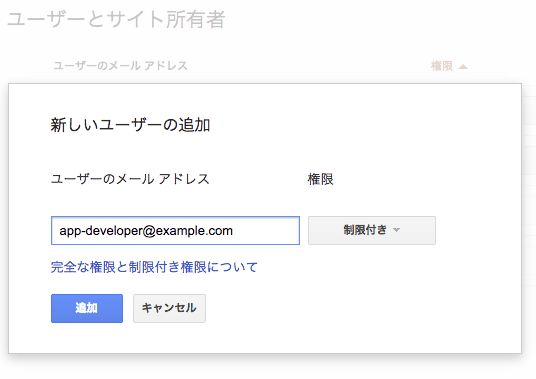
しかしながら、ウェブマスター ツールへのアクセスが許可されているデベロッパーは非常に少ないようです。アプリ関連の問題の修正に必要な情報を確実に伝達するには、デベロッパーにウェブマスター ツールへのアクセス権限を付与することが不可欠です。
確認済みのサイト所有者であれば、新しいユーザーを追加できます。付与したい権限レベルに応じて [制限付き] または [フル] を選択してください。
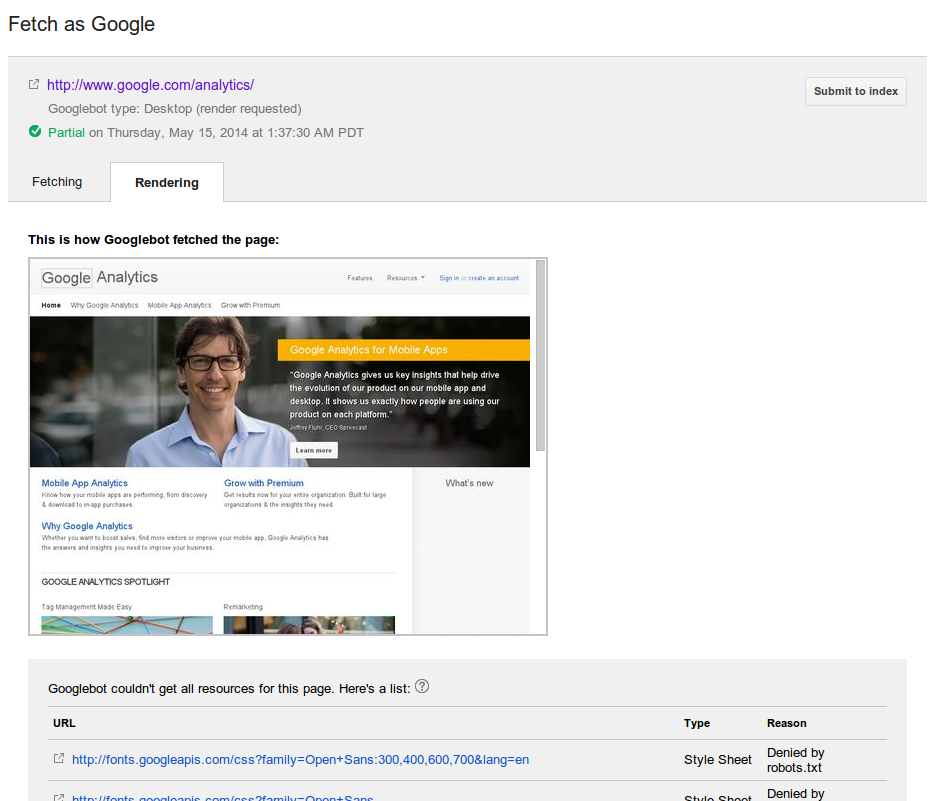
アプリ ページのレンダリングに不可欠なリソースにアクセスできない場合に、どのリソースがブロックされているかを簡単に特定できるようになりました。アプリで「コンテンツの不一致」エラーが発生した場合は、詳細ダイアログの手順 5 に沿ってブロックされているリソースの一覧を確認してください。

従来の「コンテンツの不一致」エラーと「インテント URI が無効」エラーに加え、以下の 3 つのエラー タイプを追加しました。
App Indexing 実装がうまく行くことを願っています。ご不明な点がありましたら、いつでもウェブマスター ヘルプ フォーラムまでお寄せください。
App Indexing を今年 6 月に公開して以来、デベロッパーの皆様からさまざまなフィードバックが寄せられました。ほとんどの実装はうまく行きましたが、うまく行かなかった実装からも多くを学ぶことができました。この記事ではそうした経験を踏まえ、App Indexing の実装を成功させるうえで欠かせない 4 つのステップについて解説します。また、アプリのパフォーマンスを把握したり、アプリの利用を促進したりするための便利な新機能も紹介します。
1. デベロッパーにウェブマスター ツールへのアクセス権限を付与する
App indexing は、ウェブマスターとアプリ デベロッパーが協力して取り組む必要があります。ウェブマスター ツールには、デベロッパーが必要とする情報も表示されます。現時点で表示されるのは以下の情報です。- アプリ内のインデックス登録済みページのエラー
- Google 検索でのアプリ ディープ リンクのクリック数とインプレッション数(週単位)
- サイトマップに関する統計情報(アプリ ディープ リンクをサイトマップで実装した場合)
しかしながら、ウェブマスター ツールへのアクセスが許可されているデベロッパーは非常に少ないようです。アプリ関連の問題の修正に必要な情報を確実に伝達するには、デベロッパーにウェブマスター ツールへのアクセス権限を付与することが不可欠です。
確認済みのサイト所有者であれば、新しいユーザーを追加できます。付与したい権限レベルに応じて [制限付き] または [フル] を選択してください。
2. 検索結果からのアプリへのアクセス状況を把握する
ユーザーは、検索結果からアプリにアクセスしてくれているでしょうか。アプリ ディープ リンクのパフォーマンスをトラッキングする方法として次の 2 つを追加しました。- ウェブマスター ツール アカウントのメッセージ センターに、週ごとのクリック数とインプレッション数が送信されるようになりました。
- アプリ ディープ リンクによってどれくらいのトラフィックがアプリにアクセスしたかを、リファラー情報(具体的には ACTION_VIEW インテントのリファラー extra)を使用してトラッキングできるようになりました。将来的には、この情報を Google アナリティクスに統合して簡単にアクセスできるようにする予定です。デベロッパー サイトでは、リファラー情報をトラッキングする方法(英語)について解説しています。
3. アプリの重要なリソースがクロール可能であることを確認する
ウェブマスター ツールのクロール エラー レポートで、「コンテンツの不一致」エラーが発生する大きな原因の 1 つがリソースのブロックです。クロールでは、アプリ ページをレンダリングするために必要なすべてのリソースにアクセスする必要があります。これにより、アプリ ページのコンテンツが、関連付けられているウェブページと同じかどうかを確認できます。アプリ ページのレンダリングに不可欠なリソースにアクセスできない場合に、どのリソースがブロックされているかを簡単に特定できるようになりました。アプリで「コンテンツの不一致」エラーが発生した場合は、詳細ダイアログの手順 5 に沿ってブロックされているリソースの一覧を確認してください。
4. Android アプリのエラーに注意する
アプリのインデックス登録時のエラーを簡単に特定できるようにするため、検出されたすべてのアプリ エラーをメッセージとして送信することになりました。また、そのほとんどがクロール エラー レポートの [Android アプリ] タブにも表示されます。従来の「コンテンツの不一致」エラーと「インテント URI が無効」エラーに加え、以下の 3 つのエラー タイプを追加しました。
- APK が見つからない: アプリに対応するパッケージが見つからない
- First Click Free(英語) がない: アプリへのリンクがコンテンツに直接つながっておらず、ログインしないとアクセスできない
- 戻るボタンの違反: アプリへのリンクをたどって移動した後、戻るボタンで検索結果に戻ることができない
App Indexing 実装がうまく行くことを願っています。ご不明な点がありましたら、いつでもウェブマスター ヘルプ フォーラムまでお寄せください。