単純なウェブ検索で始まったGoogleもデバイスの多様化か検索サービス利用シーンの増加、そしてソーシャルメディア上の様々な情報を取り入れて急激に進化を遂げつつあります。今回はそんなGoogleの検索サービスの進化をナレッジグラフに代表される検索に影響を与える要素と交えて深く掘り下げてみた大変興味深い記事をサーチエンジンランドから紹介します。検索マーケッターに限らず、未来のウェブを知る上で誰でも読んでみたい内容です。 — SEO Japan
様々なサービスが、ナレッジグラフのようなアセットを持っているが、その中でも、グーグルは、ナレッジグラフの検索を巧みに活用している。ナレッジグラフがSERPを変えていくにつれ、グーグルは、セマンティックテクノロジーの採用を進め、徐々にリンクをベースとした従来のSERPを置き変えつつある。検索業界をリードする同社は、未来の検索を導く役割を担っているのだ。
グーグルナウが良い例である。グーグルナウは、シリの目的を果たしており、また、シリが生まれたDARPA PALプログラムに近い。現在、アップルはシリに対する取り組みをステップアップさせており、先週行われたワールドワイド・ディベロッパーズ・カンファレンスで、シリに新たに男性と女性の声が加わった点、ツイッター検索が統合された点、ウィキペディアが組み込まれた点、そして、ビングのウェブ検索がアプリに導入された点を発表していた。グーグルが進む方向に、その他の企業も進んでいくのだ。
ナレッジカルーセル
最近、グーグルは、ナレッジカルーセルを始めとする、付随する検索および関連する検索、想定した答え、新しいタイプの情報カード等、視覚的な情報の表示の形式に関して、多くの実験を積極的に行い、ユーザーエンゲージメントをテストしている。例えば、グーグルは、先日、ローカル検索向けのナレッジグラフカルーセルをリリースしていた。さらに、ナレッジグラフを拡大して、1000を超える食品に栄養素の情報を加えている。グーグルが指摘していたように、これはほんの序の口である。

面白いことに、「ナレッジグラフ」は商標化されていない。ビングは、「スナップショット」(現在はサファリに拡大されている)、フェイスブックは、エンティティグラフ、そして、ヤフー!は「ヤフー!ナレッジグラフ」を持っている。この専門的なフレーズは急速に普及しつつある。
グーグルナウは、ナレッジグラフを効果的に活用しており、ユーザーに対して、検索の質問への具体的な答えを提供している。「OK、グーグル」と伝え、質問を投げ掛けるだけでいい。グーグルナウは、リアルタイムで質問に対する答えを提供する「スタートレック」のコンピュータに急速に肉薄している。グーグルナウの機能は素晴らしく、また、その進化と発展を目にするだけでワクワクする。
セマンティックテクノロジーを採用する検索
このグラフ検索 – セマンティックウェブのような人工知能タイプのアプリによって提供される答えは、どのくらい現在の検索に影響を与えているのだろうか?また、意図したオーディエンスが、情報を「発見することが出来る」ようにするには、情報をどのように形式化すればいいのだろうか?
基本的に答えはシンプルである。この複雑なテクノロジー、そして、SemTechBizで、グーグルがウェブ上でアイテムをランク付けするために用いているメカニズムが議題に上った際に、グーグルのジェイソン・ダグラスが言及した、216点の奇妙な“シグナル”を理解すればいい。この答えは、SEOのアナリストにとって、別の疑問を提起することになる – 自分の会社、または、代理でSEOを行っている会社を、ナレッジグラフに反映させるにはどうすればいいのか?
控えめに言ってもこれは割と面倒なタスクである。そのため、誰でも理解することが出来るメトリクスを見ていこう。まず、キーワードよりも、コンセプトやエンティティが優先されつつある。信じ難いだろうか?以下に比較的新しいグーグルトレンドのトップチャートを掲載する。このチャートは、現在、(キーワードではなく)エンティティによってグループ分けされている。
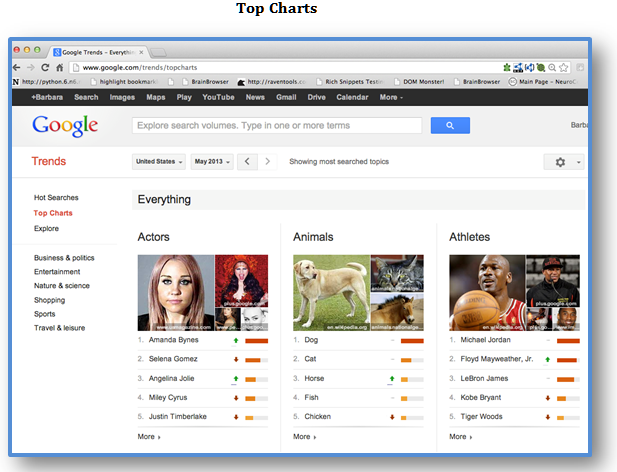
このエンティティは、Dbpediaとフリーベースとして始まった、グーグルのナレッジグラフから引き出されている。この2つのサービスは、セマンティックウェブコミュニティによって管理されている、リンクトデータ(リンクが張られたデータ)のクラウドの中心に存在し、また、schema.orgのエンティティのインスタンスを用いて拡大されている。
2011年版のリンクトデータクラウドのイメージを以下に掲載する(参照資料と共に)。ご覧のようにDBPediaが中心に陣取っている(DBPediaは、恐らく、ウィキデータに取って代わると考えられている)。この図表は、若干古いが、情報を通して過去を振り返ってみると、このテクノロジーの爆発的な成長が色濃く表れていることが分かる。
検索エンジンは、このリンクが張られた、構造化されたデータを、例えば、魅力的で視覚的な各種フォーマットを介して、表示を改善するため、クエリに直接答えを出すため、娯楽等の領域におけるファインダビリティに改善するため等、多くの方法で活用することが出来る。これは、取り込まれた、もしくは、有効な認証済みの構造化データにおいて、直接的な検索を活用することで、魅力的なユーザーエクスペリエンスを生み出すために用いられるメカニズムの一部に過ぎない。
イベントやエンターテイメント等のカテゴリから、グーグルショッピングやeコマース自体に至るまで、ユーザーのインタラクションやエンゲージメントの増加のために、このようなエンティティグラフを活用する考えは、ますます拡大を続け、また、検索エンジンに利用されていくだろう。グーグルでトレンドになっている別のセクションを取り上げた画像を以下に経済する。今回、私は「shopping」の選択肢を採用した。

また、会社のページ、または、会社のエンティティ(さらには、グーグルナウを完全に活用したいなら、個人においても)で、グーグル+を活用することがますます重要になりつつある。
グーグル+もまたグーグルが活用する優れたメカニズムである。このソーシャルネットワークを利用しない状態では、ナレッジグラフでビジビリティを確立することは、事実上不可能である。
「検索」する行為よりも「見つける」行為が重要視されている点は明白である。昔の10本の青いリンクが提供される検索は、フラストレーションの溜まる作業になるが、代わりに、自分専用のアシスタントが、個人のコンピュータ(スマートフォン)として、どこまでもついてきてくれる贅沢を考えると、思わずワクワクする。この問題は、解決されたわけではないが、徐々に解決に近づきつつある。
しかし、検索結果での、個人的な答え(グーグルナウでは、カードとして提供される)、そして、グーグルナウ経由の情報の提示は、それぞれのユーザーに合わせて行われるため、ある程度ユーザーに犠牲を強いることになる。スマートフォンが、持ち運ぶセンサーとして、様々な役割を果たし、多くのアクティビティ/行動を記録する点を忘れないでもらいたい(このデータは、後に適切な情報を、適切なタイミングで提供するために用いられる可能性がある)。
個人的には、メリットはリスクを大幅に上回り、また、素晴らしい時代になったと思う(例えば、私は方向音痴であり、見知らぬ土地では、コンピュータのナビに依存している)。しかし、とりわけPRISMのリーク問題の後、プライバシーの侵害を警戒する人達が現れていることも事実である。
検索ではグラフの右に出る者はなし
大規模なソーシャルエンジンや通常の検索エンジンは、ソーシャルネットワークの形式であれ、ナレジグラフであれ、エンティティグラフであれ、関連するエンティティ等のグラフを用意している。グラフはユビキタスであり、大抵、ビッグデータとグラフ分析に関して、多くの興味深い分析データのベースを構築している。
SEOの観点から考えると、検索エンジンが、内部の構造化されたナレッジグラフとして取り入れ、その後、好みに合わせて問い合せを行うことが可能な、HTMLまたは構造化マークアップの“作成”については、議論の余地が多く残されていると思う。しかし、例えば、グラフのデータベースに問い合せを行い、ユーザーのクエリに対する答えを生成するため、セマンティックウェブクエリ言語(SPARQL(リレーショナルデータベースに対するSQLに似ている)を利用するアプローチが存在する点は、注目に値する。
SemTechBizカンファレンスで、ヤフー!のナレッジグラフが話題に上がった時、ヤフー!のエンティティグラフのトピックが、次の順序で表れることが明らかになった: ニュース、ファイナンス、スポーツ等。スナップショットを持つビングは、リンクトインを売りにしており、よりソーシャルな色が濃い。リンクトイン自体が、ユーザー自身のネットワークのグラフを閲覧する優れた手段を用意している。そこで、私のリンクトインのグラフの例を作ってみた(自分のグラフを見たいなら、ここをクリック)。.

ハッシュタグ & トピックベースの検索
ハッシュタグは、どのトピックベースの検索が役に立つのか、そして、どのリンクトデータが引き出されるのかを把握する上で、注目を集め始めている。グーグルは、以前、グーグル+でのハッシュタグのオートコンプリート機能の発表を行っていた。また、先日のI/Oカンファレンスでは、グーグル+の投稿が、自動的に分類されるトップ3のハッシュタグでタグ付けされると新たに発表していた。フェイスブックもまた、2013年6月12日に、ハッシュタグを加えて、公開されている会話の整理を促すと発表している。
従って、ハッシュタグもまたユビキタス化している – ツイッター、ピンタレスト、グーグル+等々。リンクトデータとハッシュタグ、そして、自動的にアノテーションを付ける、セマンティックウェブの関係を詳しく知りたい方はここをクリックしよう。
現実の難題に話を戻す。自分の会社、または、SEOの取り組みを代理で行っている会社を、ナレッジグラフに掲載してもらうには、どうすればいいのだろうか?適切なマークアップとschema/エンティティおよびアトリビュートをサイトに用意している点をどのように確認すればいいのだろうか?
グーグルはマークアップの利用を求めている
グーグルは、マークアップをサイトに加える方針を大きくプッシュしている。最近の取り組みの例を幾つか紹介していくが、この点からも、グーグルが構造化マークアップを積極的に求めており、有益で信頼に値するナレッジグラフを拡大すようとする姿勢が窺える。
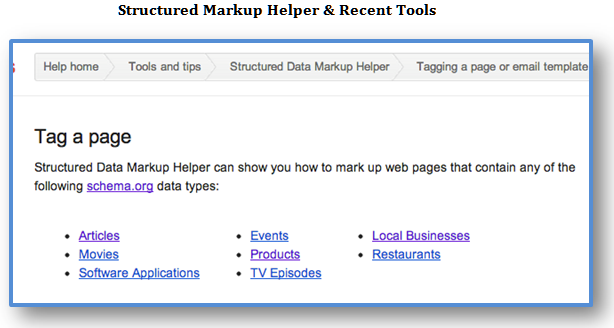
また、グーグルが、構造化マークアップ、そして、ナレッジグラフの領域に関連すると考えている情報にも注意してもらいたい。

上の画像にリストアップされているように、構造化マークアップに関連するアイテムとして、次のアイテムが挙げられている:
- マイクロデータ
- グーグルの基礎(そのまま)
- グーグル+のページ
- リッチスニペット
- サイトマップ
重要なポイント
このトピックに関しては、もっと徹底した調査が必要だが、以下に重要なポイントを挙げていく:
- ページが適切にマークアップされている点、そして、適切なエンティティを活用している点を確認する。
- グーグルやセマンティックウェブコミュニティ等が提供する適切なリソースに真剣に目を通し、活用する。
- セマンティックウェブの会合やSEOの会合は基本的に無料であり、様々な地域で開催されている。meetup.comにアクセスし、「Semantic Web」と入力しよう。
リソースに余裕があるなら、セマンティックウェブおよびSEOのエキスパート、あるいは、専門家が作ったツールを採用して、ナレッジグラフおよび検索エンジンでのビジビリティを確保する。
この記事の中で述べられている意見はゲストライターの意見であり、必ずしもサーチ・エンジン・ランドを代表しているわけではない。
この記事は、Search Engine Landに掲載された「Search, Answers & Knowledge Graphs Galore」を翻訳した内容です。
未来というか既に現実の話でもあったわけですが、しかしGoogle検索もいよいよ本格的にキーワードではなくエンティティ(日本語で書くと意味不明になるので、テーマやジャンルというイメージの方がわかりやすいかもです)レベルでセマンティック化しつつあるようです。キーワード単位で考えるSEOの時代は終わり、、、というわけではないと思いますが、検索エンジンが大きく変化していくのに合わせて検索マーケッターもその変化に対応していく必要はありそうですね。 — SEO Japan [
G+]


