
数年前、私はカメラを向けるとそれが何かを教えてくれるようなアプリを熱望していた。結局その問題は、皆が期待していたものよりもはるかに困難だったが、そのことは高校生Michael Royzenのやる気を削ぐものではなかった。彼のアプリであるSmartLensは、何かを見て、それが何かを特定し、さらに詳細を知りたいという問題を解決しようとするものだ。正直なところそれは完璧な成功とは言えないが、ポケットの中に忍ばせておくことに抵抗はない。
Royzenが私に連絡してきたのは少し前のことだったが、私は興味深いと(実は正直疑わしいと)思っていた。GoogleやAppleのような企業もずっと失敗してきた(少くとも良い製品はリリースできていない)課題解決を、空き時間を使って作業している高校生ができるものだろうか。私は彼と喫茶店で会い、実際に動作するアプリを見て、嬉しい驚きと、ちょっとした困惑を感じた。
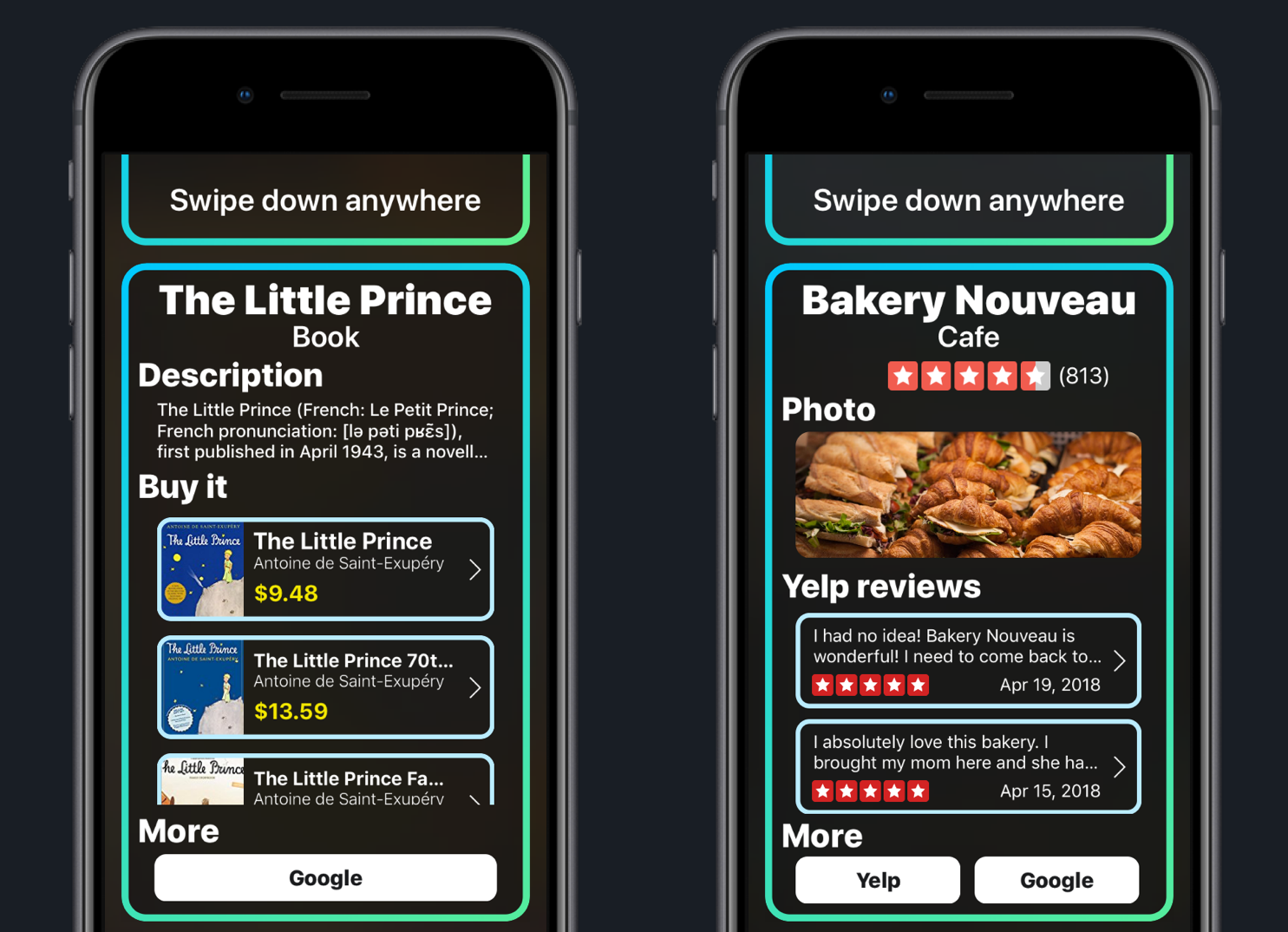
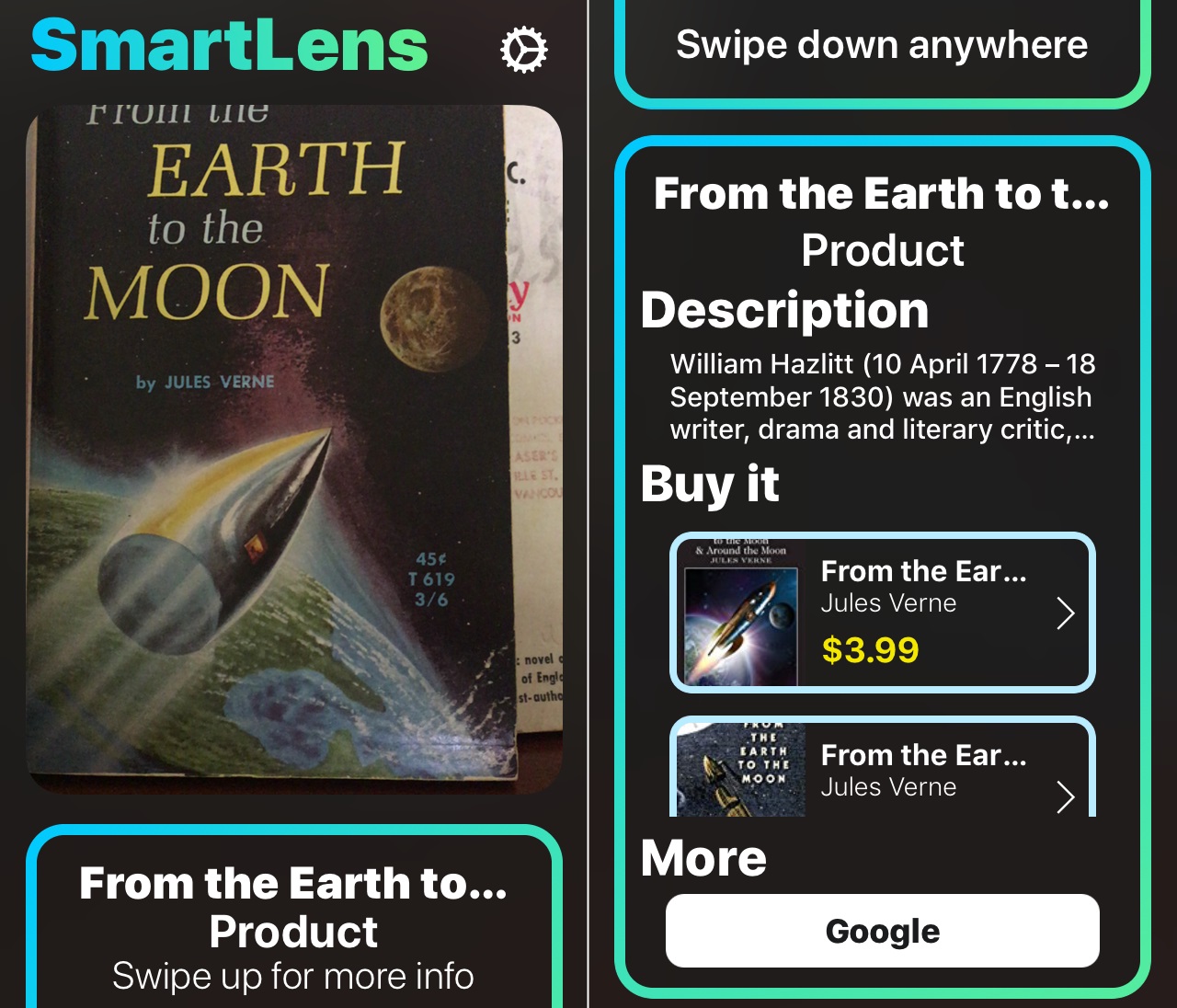
このアイデアは単純だ:携帯電話のカメラを何かに向けると、何千万枚ものイメージを使って訓練され、巨大だが高度に最適化された分類エージェントを利用して、アプリがその対象を識別しようとする。WikipediaとAmazonに接続することで、アプリが識別したものに関して、より詳細に知ったり購入したりすることができる。
それは1万7000以上の物体を認識する。多くの種類の果物や花、ランドマーク、道具などなど。アプリはリンゴと(少々変わった見かけの)マンゴーの区別や、バナナとプランテーンを区別すること、そしてサイドメニューとして注文したピスタチオの識別には少々苦労した。その後、私自身が行ったテストでは、近隣の植物を特定するのにとても便利であることがわかった:ツルニチニチソウ、アネモネ、カタバミなどなど、どれも迷うこと無く識別したのだ。
 驚くべきことに、これらは全てオフラインで行われているのだ。画像をモバイル回線やWi-Fiを通してどこかのサーバーに送信して、解析しているわけではない。すべてがデバイス上で、1〜2秒以内に完了する。Royzenは、さまざまな情報源から自分自身の画像データベースを構築し、AWS EC2の計算時間を何日も使って複数の畳み込みニューラルネットワーク(CNN)を訓練した。
驚くべきことに、これらは全てオフラインで行われているのだ。画像をモバイル回線やWi-Fiを通してどこかのサーバーに送信して、解析しているわけではない。すべてがデバイス上で、1〜2秒以内に完了する。Royzenは、さまざまな情報源から自分自身の画像データベースを構築し、AWS EC2の計算時間を何日も使って複数の畳み込みニューラルネットワーク(CNN)を訓練した。
さらに、アイテム上のテキストを読んでAmazonデータベースを照会することによって、さらに多くの商品を認識することができる。それは、書籍、薬のボトル、その他のパッケージ商品を、ほぼ即座に識別し、それらを購入するためのリンクを提示する。オンライン時にはWikipediaリンクもポップアップするが、かなりの量の基本的な説明がデバイスにダウンロード済である。
注意点として、SmartLensのダウンロードサイズは500メガバイトを超えていることを指摘しておかなければならない。Royzenのモデルは巨大である。なぜなら、携帯電話上にすべての認識データとオフラインコンテンツを保持しなければならないからだ。これはFire Phone(RIP)上のAmazon自身による認識エンジンや、Google Goggles(RIP)、あるいはGoogle Photosのスキャン機能(SmartLensが0.5秒で認識できる対象に対して役に立たなかった)などとは、相当異なるアプローチを採用している。
「デスクトップクラスのプロセッサを搭載したここ数世代のスマートフォンと、それらのプロセッサ(とGPU)を利用できるネイティブマシンラーニングAPIの登場によって、ハードウェアは驚異的な高速のビジュアル検索エンジンとなりました」とRoyzenは電子メールに書いてきた。しかし、同様のことをすることが当然期待される大企業たちはどこもそうしたプロダクトを作成していない。それは何故だろう?
アプリケーションのサイズとプロセッサへの負荷は確かに問題の1つである。しかしエッジならびにオンデバイス処理は、こうしたことが最終的に目指している場所である。Royzenは、それに対して早めのスタートを切っただけなのだ。難しい点が2つある:収益化することは難しく、検索の質も十分には高くないということだ。
現時点では、SmartLensはスマートではあるものの、間違いがないとは言えない。対象が何であるかの正解にたどり着く直前には、(しばしば起きることだが)爆笑ものの間違いを答える。
それは私が持っていた本を「白い鯨」だと識別したが、それは書籍「白鯨」ではなかった。また、それがクジラ形の文鎮だと言ったものは、園芸用のコテだった。多くのアイテムでは、より高い確信度の推測に到達する前に、「人間」もしくは「プロダクトデザイン」という推測がチラついた。ひとかたまりの花の集まりが、4から5種類の植物として認識される…その中にはもちろん「人間」も混ざっている。私のモニターは「コンピューターディスプレイ」、「液晶ディスプレイ」、「コンピューターモニター」、「コンピューター」、「コンピュータースクリーン」、「ディスプレイ装置」などとして認識された。ゲームコントローラはすべて「コントロール」だ。スパチュラは木製のスプーン(まあ近いかな)だったが、不可解なサブタイトル「ブービー賞」が添えられていた。何だって?!
 こうしたレベルの性能(そして楽しくはあるものの、奇妙な振る舞い)は、GoogleやAppleがリリースするスタンドアロン製品では許容されないだろう。Google Lensは遅くて出来の悪い代物だが、便利で役立つアプリの中の、オプション機能に過ぎない。もし花を人間として識別するビジュアル検索アプリを出したなら、企業はいつまでもそのことを言われ続けるだろう。
こうしたレベルの性能(そして楽しくはあるものの、奇妙な振る舞い)は、GoogleやAppleがリリースするスタンドアロン製品では許容されないだろう。Google Lensは遅くて出来の悪い代物だが、便利で役立つアプリの中の、オプション機能に過ぎない。もし花を人間として識別するビジュアル検索アプリを出したなら、企業はいつまでもそのことを言われ続けるだろう。
そしてもう一つの課題は収益化の側面である。理論的には、友人が持っている本の表紙を認識して即座に注文することは可能だが、そのことは、写真を撮って後で検索することや、最初の数単語をGoogleやAmazonに入力すれば用が足ることに比べて、それほど便利だとは言えない。
その一方で、ユーザー側にも迷いがある。それが識別できるのは何か?それが識別できないのは何か?何を識別すれば良いのか?それは犬の品種や店舗などの多くのものを識別することを意図しているが、例えば、友人が持っているクールなBluetoothスピーカーや機械式時計、あるいは地元のギャラリーに飾られた絵の作者などを識別はしない(とはいえ、いくつかの絵は認識される)。それを使っているうちに、私は花の識別のような、うまくいくことが証明されたタスクだけに使うようになっていったように思う。しかしそれ以外の不確実で上手く行かないものに関しては、フラストレーションが溜まるだけなので、試してみる気にはなれなかった。
それでも近い将来に、SmartLensのようなものが存在しないと考えることは、馬鹿げていると思う。数年のうちには、私たちがそれを当然のものとして扱うようになることは、あきらかだ。また、それらはオンデバイスで行われ、解析のために画像を何処かのサーバーへとアップロードする必要はないだろう。
Royzenのアプリ自身は課題を抱えているものの、多くの状況で非常にうまく動作するし、明白な有用性がある。ここでのアイデアは、道の向こうのレストランに携帯電話を向けたなら、2秒でYelpのレビューが見られるといったものだ、マップを開く必要もなく、住所や名前を入力する必要もない。こうしたことは既存の検索パラダイムの自然な延長線上にあるものである。
「ビジュアル検索はまだニッチですが、私の目標は、あるアプリケーションが身の回りの全てのものに関する有益な情報を教えてくれるようになったら、どのように感じるかを皆に伝えることなのです ―― それも今すぐに」とRoyzenは書いている。「しかし、大企業が最終的には競合製品を発売することは必然です。私の戦略は、最初の普遍的なビジュアル検索アプリとして市場に出て、先行者であり続けられるように(あるいは買収されるように)できるだけ多くのユーザーを集めることです」。
しかし、私の最大の不満は、アプリの機能そのものではなく、Royzenがそれをマネタイズする際に決定したやり方である。ユーザーはアプリを無料でダウンロードすることができるが、立ち上げるとすぐに、月額2ドル(日本だと月額200円)のサブスクリプションを促されるのだ(まだアプリがちゃんと働くかどうかも見ていないのに)。もしアプリが何をして、何をしないのかを既に知っているのでなければ、そのダイアログを見た瞬間に考える間もなく削除することだろう。そして仮にそれを支払うことにしたとしても、それを永遠に払い続けることはない。
アプリを有効にするための1回限りの手数料を徴収することがおそらく妥当だろう、また紹介コードの提供という選択肢は常に存在している。しかし商品のテストさえしていないユーザーから月額家賃を徴収しようというのは、成功の見込みがない。私はRoyzenに懸念を伝えた。私は彼が再考してくれる事を願っている。(訳注:5月2日現在、サブスクリプション登録は必要なままだが最初の30日間は無料となっている。この期間中に解約すれば料金は発生しない)。
既に撮影した画像をスキャンできるようにしたり、検索に利用した画像を保存できるようにするのも良いだろう。確信度インジケータのようなUIの改善や、それがまだ識別中であることを知らせる何らかのフィードバックもあると良いだろう、少くとも理論的にはそうした機能が考えられる。
なんだかんだと言ってはみたが、私はRoyzenの努力には感銘を受けている。一歩退いて眺めてみれば、高校生であるということは置いておくとしても、このように洗練されたコンピュータービジョンタスクを実行可能なアプリを、1人でまとめ上げたというのは驚異的なことだ。これは、10年前のGoogleのような、大きくて遊び心のある会社から出てくることが期待できるような(やり過ぎ)野心的アプリケーションの一種である。これは今のところ普通のツールというよりは、好奇心先行のものかもしれないが、最初のテキストベースの検索エンジンも似たようなものだった。
SmartLensは現在App Storeから入手可能だ ―― お試しあれ。
[原文へ]
(翻訳:Sako)

