
Googleのクラウドプラットホームでは、社内用に作ったツールやサービスがGoogleのプロダクトとして顧客に公開提供されることが多い。今日(米国時間3/28)同社は、その一環として、Google Cloud Platformの上でアプリケーションを構築するデベロッパーにとって重要な、アプリケーションのパフォーマンス管理(application performance management)ツール集Stackdriver APMを発表した。
APMの考え方はやや変わっていて、問題の責任をオペレーションに渡すのではなく、デベロッパーがアプリケーションを調べる。つまりアプリケーションを作ったデベロッパーがコードにいちばん近いところにいるので、そこから出てくる信号もいちばんよく理解できるはずだ、とする。
StackDriver APMは、三つのツールで構成される: プロファイラーとトレース(トレーサー)とデバッガだ。トレースとデバッガはすでに利用できるが、しかしプロファイラーと併用することによって、三つのツールが協働してコードの問題を特定し、調べ、そして修復できるようになる。
Stackdriver APMを発表するブログ記事でGoogleのプロダクトマネージャーMorgan McLeanはこう書いている: “これらのツールのすべてが、どんなクラウドの上で動くコードやアプリケーションでも扱えるし、オンプレミスのインフラでも使える。つまり、アプリケーションがどこで動いていても、一貫性がありアクセス性の良いAPMのツールキットを使って、アプリケーションのパフォーマンスをモニタし、管理できる”。
ほかにStackDriverにはモニタリングとロギングのツールもあり、これら完全なAPMのスイートが、SplunkやDatadog、New Relic、AppDynamics(Ciscoが買収)などのベンダと競合することになる。しかしGoogleのプロダクト管理担当VP Sam Ramjiによると、これらのベンダは競合他社であるだけでなくパートナーでもあり、お互いのツールが協働して問題解決に取り組むことを、Googleも十分に理解している。
“しかし、コアシステムがみんなによく見えるようにする点では、うちが一番だ。人びとはこれまで使ってきたお気に入りのツールをこれからも使って、彼らの企業の事業目的という見地からプロダクションシステムを検査したり、適切なタイミングでアラートしていくだろう”、と彼は述べる。
まず最初は、プロファイラーの出番だ。これによりデベロッパーは、軽量級の(全量ではなく)サンプリングベースのツールで、アプリケーションのすべてのインスタンスからデータを収集する。
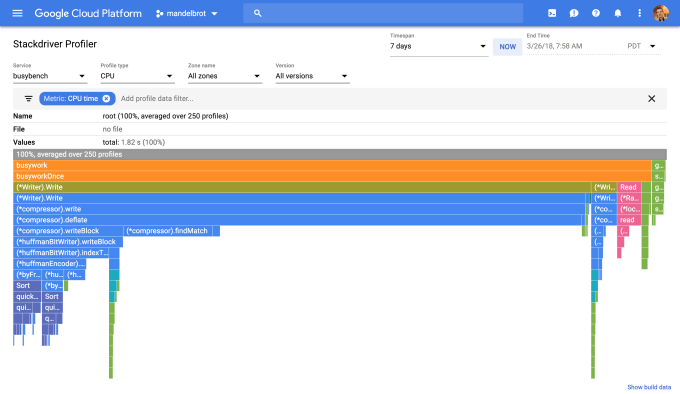
Stackdriver Profiler. 画像提供: Google
プロファイラーが集めたデータから問題を判定したプログラマーは、次にトレースを動かす。Ramjiによると、コードの問題はほとんどつねにクリティカルパスの後(あと)にあるから、このツールを使えば、問題が分散システムの全域にわたって伝搬していく様子を理解できる。トレースの画面(下図)は視覚化されたアナリティクスのような形をしていて、これらにより問題の性質と、計算資源に対するそのインパクトが分かる。
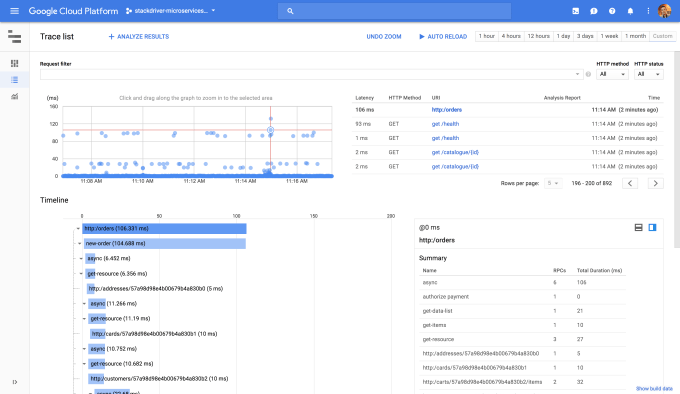
Stackdriver Traceツール。 画像提供: Google
そして最後がデバッガだ。Ramjiがこれをとくに好きなのは、若き日の90年代のツールを思い出させるからだ。当時はデバッガでアプリケーションを止めたり動かしたりしながら、問題の所在を突き止めていた。このAMPのデバッガもやはり、指定した箇所でコードを止めて、問題の核心を見つける。
ただしこの現代的なデバッガには、Ramjiが“マジック”と呼ぶものがある。デベロッパーによるコードの停止や再開が、顧客に影響を及ぼさないのだ。McLeanもこう書いている: “プログラマーにおなじみのブレークポイント方式のデバッグ処理を提供するが、それによって顧客へのネガティブなインパクトはない”。
Stackdriver APMは今日(米国時間3/28)から可利用になり、完全なサービスから成る完全なモニタリングスイートが提供される。これでGoogleは、モニタリング〜デバッグという分野でも、既存の選手たちと競争するつもりのようだ。
